目录
1.算法仿真效果
本系统进行了Vivado2019.2平台的开发,Vivado2019.2仿真结果如下:
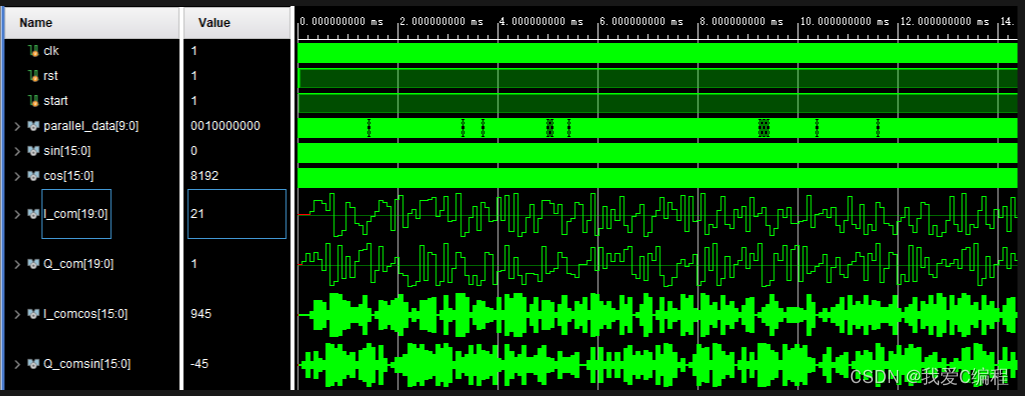
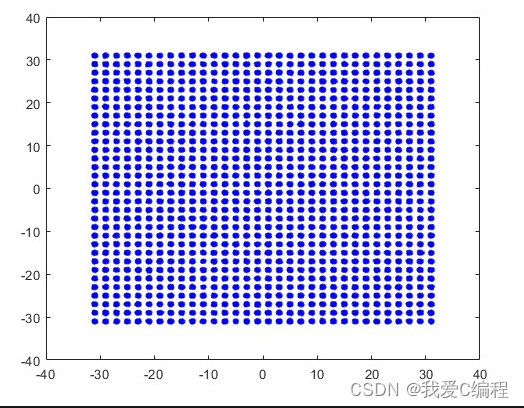
将1024调制信号导入到matlab显示星座图
2.算法涉及理论知识概要
本文将详细介绍基于FPGA的1024QAM调制信号产生模块。本文将从以下几个方面进行介绍:1024QAM调制信号的基本原理、符号映射方式、并行化处理和FPGA实现等。
2.1. 1024QAM调制信号的基本原理
1024QAM调制是一种高阶数字调制方式,将10个二进制比特映射到一个复平面上的1024个点。1024QAM调制信号可以表示为:
$$s(t)=A_c \sum_{n=0}^{N-1}a_np(t-nT)cos(2\pi f_ct+\phi_n)$$
其中,A_c是载波幅度,a_n是10个二进制比特,p(t)是脉冲成形滤波器,T是符号间隔,f_c是载波频率,\phi_n是相位。
2. 2符号映射方式
1024QAM调制信号的符号映射方式有多种选择,例如Gray映射、正交映射等。在本文中,我们选择Gray映射方式,其具有较好的错误容忍性和功率效率。
Gray映射的思想是将相邻的符号在二进制比特上只有一个位不同。例如,当a_n为0000000000时,其对应的符号为QAM调制图中的左下角点;当a_n为0000000001时,其对应的符号为左下角点往上移动一个单位。
2.3 并行化处理
由于1024QAM调制信号需要处理的数据量较大,因此需要采用并行化处理的方法,以提高运算速度和降低硬件资源消耗。
并行化处理的方法包括时间并行和空间并行。在本文中,我们选择时间并行的方法,即将数据流划分为多个并行处理单元,每个处理单元负责处理一部分数据,以实现并行化处理。如图3所示,将10个二进制比特分为5组,每组包含两个比特,每个比特对应一个并行处理单元。
在并行处理的过程中,需要考虑数据的同步和处理单元之间的数据传输。一种常用的方法是采用流水线处理,即将数据流分为多个处理阶段,每个阶段包含多个并行处理单元,相邻阶段之间通过寄存器进行数据传输和同步。
2.4. FPGA实现
FPGA是一种灵活可编程的硬件平台,可以根据具体需求进行定制化设计和实现。在实现基于FPGA的1024QAM调制信号产生模块时,需要根据具体硬件资源和运算速度要求进行设计和实现。通常,FPGA实现的步骤包括硬件描述语言编写、综合、布局布线、生成比特流和下载到FPGA芯片等。其中,硬件描述语言编写是实现的核心,可以采用Verilog或VHDL等语言进行编写。
基于FPGA的1024QAM调制信号产生模块的实现方法,包括1024QAM调制信号的基本原理、符号映射方式、I并行化处理和FPGA实现等。通过合理的设计和优化,可以实现高效、稳定和可靠的1024QAM调制信号产生模块,适用于通信、雷达、信号处理等领域。
3.Verilog核心程序
module TEST;
reg clk;
reg rst;
reg start;
wire [9:0] parallel_data;
wire [15:0]sin;
wire [15:0]cos;
wire signed[19:0] I_com;
wire signed[19:0] Q_com;
wire signed[15:0]I_comcos;
wire signed[15:0]Q_comsin;
// DUT
tops_1024QAM_mod top(
.clk(clk),
.rst(rst),
.start(start),
.parallel_data(parallel_data),
.sin(sin),
.cos(cos),
.I_com(I_com),
.Q_com(Q_com),
.I_comcos(I_comcos),
.Q_comsin(Q_comsin)
);
//wire signed[23:0]I_comcos2;
//wire signed[23:0]Q_comsin2;
//wire signed[7:0]o_Ifir;
//wire signed[7:0]o_Qfir;
//wire signed[7:0]o_sdout;
//tops_256QAM_demod top2(
// .clk(clk),
// .rst(rst),
// .start(start),
// .I_comcos(I_comcos),
// .Q_comsin(Q_comsin),
// .I_comcos2(I_comcos2),
// .Q_comsin2(Q_comsin2),
// .o_Ifir(o_Ifir),
// .o_Qfir(o_Qfir),
// .o_sdout(o_sdout)
// );
initial begin
clk = 0;
rst = 0;
start = 1;
#10;
rst = 1;
end
always #5
clk <= ~clk;
integer fout1;
integer fout2;
initial begin
fout1 = $fopen("II.txt","w");
fout2 = $fopen("QQ.txt","w");
end
reg [4:0]dcnt=5'd0;
always @(posedge clk) begin
if(rst == 0) begin
dcnt <= 0;
end
begin
dcnt <= dcnt+5'd1;
end
end
always @ (posedge dcnt[4])
begin
if(rst==1)
begin
$fwrite(fout1,"%d\n",I_com);
$fwrite(fout2,"%d\n",Q_com);
end
end
endmodule
00_024m4.完整算法代码文件
V