Enabling Fast and Universal Audio Adversarial Attack Using Generative Model
https://www.winlab.rutgers.edu/~yychen/
AAAI 2021
文章目录
- Enabling Fast and Universal Audio Adversarial Attack Using Generative Model
- Abstract
- Introduction
- Fast Audio Adversarial Perturbation Generator (FAPG)
- Universal Audio Adversarial Perturbation Generator (UAPG)
- Attack Evaluation
- Conclusion
Abstract
近年来,基于深度神经网络(DNN)的音频系统在对抗性攻击中的脆弱性日益受到人们的关注。然而,现有的音频对抗性攻击允许攻击者拥有整个用户的音频输入,并给予足够的时间预算来产生对抗性扰动。然而,这些理想化的假设使得现有的音频对抗性攻击在实践中大多不可能及时发起(例如,随着用户的流输入播放不明显的对抗性干扰)。
为了克服这些限制,本文提出了快速音频对抗性扰动发生器(fast audio adversarial perturbation generator FAPG),它使用生成模型对音频输入在单次前向传递中产生对抗性扰动,从而大大提高了扰动的生成速度。在FAPG的基础上,我们进一步提出了通用音频对抗性扰动发生器 (universal audio adversarial perturbation generator UAPG),这是一种可以对任意良性音频输入施加通用对抗性扰动以导致错误分类的方案。在基于dnn的音频系统上的大量实验表明,我们提出的FAPG可以获得较高的成功率,比现有的音频对抗性攻击方法加速高达214倍。此外,我们提出的UAPG产生普遍的对抗性扰动,可以实现比最先进的解决方案更好的攻击性能。
Introduction
深度神经网络(DNNs)作为目前最强大的人工智能技术,在许多实际应用中得到了广泛的应用。尽管dnn目前很成功,也很受欢迎,但它仍存在一些严重的局限性,特别是在面对对抗攻击时具有固有的高度脆弱性,这是一种非常有害的攻击方法,对dnn的良性输入施加精心设计的对抗性扰动,从而导致错误分类。dnn的脆弱性最初是在图像分类应用中发现的,迄今为止,尤其是各种类型的对抗性扰动生成方法,在许多图像域应用中得到了广泛的研究。
考虑到现代音频领域应用和系统中dnn的使用迅速增加,如智能音箱和语音助手(如Siri,谷歌assistant, Alexa),最近机器学习和网络安全社区都开始研究音频领域对抗性攻击的可能性。一些开创性的研究证明,在良性语音输入中注入不明显的扰动以误导基于dna的音频系统的想法不仅在概念上有吸引力,而且在实际中也是可行的。迄今为止,已有几项研究报告了在不同的音频领域应用程序中成功的对抗性攻击,包括但不限于说话人验证,语音指令识别,语音到文本的转录和环境声音分类。
Limitations of Prior Work
虽然现有的工作已经证明了音频对抗攻击的可行性,但它们仍然面临着一些挑战。更具体地说,最新的音频对抗性攻击方法在攻击设置上做出了几个理想化的假设:
- 有大量的时间预算用于产生对抗性扰动。在实际的音频应用中,良性输入通常是快速流语音输入。因此,由于时间的限制,现有的音频对抗性攻击依赖于耗时的迭代优化方法,如C&W或遗传算法,速度太慢,无法对这些实时音频处理系统发起攻击。
- 拥有观察良性输入上下文的授权。由于现有的扰动产生方法需要预先知道正在进行的语音输入的全部内容,所以音频信号固有的顺序性使得对手不可能在输入流阶段产生对抗性的扰动。因此,目前的音频对抗性攻击只能针对录制或回放的语音,而不能针对实时音频信号,从而使其不适用于各种现实世界的音频域攻击场景。
Technical Preview and Contributions
为了克服这些限制,在本文中我们建议使用生成模型在音频域中产生对抗性扰动的模型。该生成模型以离线方式从训练数据中学习对抗性扰动的分布。生成模型经过良好的训练后,可以非常快速地产生音频对抗性扰动,从而解锁了在实时设置中实现音频对抗性攻击的可能性。本文的主要贡献总结如下:
- 我们首次提出了一种基于生成模型的快速音频对抗性扰动发生器(FAPG)。与现有需要大量对抗摄扰生成时间的方法不同,我们提出的FAPG通过良好的已训练好的生成模型Wave-U-Net在单次前向传递中生成所需的音频对抗扰动,从而大大加快了摄扰生成速度。
- 我们建议将一组可训练的分类嵌入特征映射集成到FAPG中,将音频数据中的所有标签信息编码到一个统一的模型中。传统的基于生成模型的图像域对抗攻击需要针对不同的目标类别使用不同的生成模型,而本文提出的音频域FAPG可以使用单个生成器模型针对任何对手期望的类别生成对抗性扰动。如果攻击者希望使用多个目标类别发起攻击,这种减少可以显著节省内存成本和模型训练时间。
- 在输入依赖的FAPG的基础上,我们进一步提出了一个输入独立的通用音频对抗摄动发生器(UAPG)。UAPG能够生成一个单一的通用音频对抗性扰动(UAP),它可以在不同的良性音频输入上应用和重复使用,而不需要输入依赖的扰动重新生成。此外,由于UAP的通用性存在于不同的良性输入中,这一重要特性消除了需要观察整个输入以产生扰动的先验约束,从而实现实时音频对抗性攻击。
- 我们使用FAPG和UAPG对三个基于dnn的音频系统进行攻击性能评估:谷歌语音命令数据集上的语音命令识别模型(Warden 2018), VCTK数据集上的说话人识别模型(Christophe, Junichi, and Kirsten 2016)和UrbanSound8k数据集上的环境声音分类模型(Salamon, Jacoby, and Bello 2014)。与最先进的输入依赖攻击相比,我们基于fapg的攻击在成功率相当的情况下实现了214倍的加速。与现有的输入无关(通用)攻击相比,我们基于UAPG的攻击在白盒设置和黑盒设置下的欺骗率分别提高了37.22%和29.98%。
Fast Audio Adversarial Perturbation Generator (FAPG)
快速音频对抗性扰动发生器
Motivation
Dilemma Between Speed and Performance
速度和性能之间的两难
尽管现有的音频对抗性攻击目前取得了进展,但正如引言中所分析的那样,最具挑战性的限制之一是它们固有的对抗性扰动的缓慢生成过程。这是因为:
- 目前普遍采用的潜在对抗性扰动生成方法,如PGD (Madry et al. 2017), C&W (Carlini and Wagner 2018)和遗传算法(Alzantot, Balaji, and Srivastava 2018),都是建立在迭代次数的基础上来优化或搜索扰动。虽然这种迭代机制可以带来很高的攻击性能,但是相应的所需生成时间非常长,例如产生一个精心制作的扰动需要几秒钟甚至几个小时。
- 减少迭代次数使生成时间满足实时性要求是另一种解决方案,然而,相应的攻击性能会严重降低。
- 另一方面,现有的扰动生成方法,如FGSM (Goodfellow, Shlens, and Szegedy 2014),虽然具有快速生成的优势,但受攻击性能限制较差,攻击成功率通常比基于迭代的方法低得多。
Why Fast Perturbation Generation Matters?
为什么快速摄动产生很重要?
为什么要以实时的方式产生扰动?攻击者不能仅仅记录良性的语音输入,在足够的时间预算下离线生成扰动,然后播放生成的敌对音频吗?事实上,上述假设的攻击策略可能适用于一些时间预算宽松的场景。
然而,在实际的攻击场景中,攻击者很有可能没有很多机会接近受害者,记录受害者的讲话或在飞行中改变受害者的讲话。如果有机会,攻击者可能想要记录下演讲,然后立即产生对抗性干扰(最好使用他们的移动设备),并将其注入受害者的现场互动演讲。这将使摄动产生和注入过程的时间预算和计算资源非常有限。因此,一种以非常及时和低计算复杂度的方式制作鲁棒对抗性扰动的有效方法是非常可取的。
Generative Model-based Solution in Image Domain
基于生成模型的图像域求解方法。
上述对快速对抗摄动生成的需求并不是音频特有的问题,而是广泛存在于图像领域。为了满足这一时序要求,最近的图像域研究提出利用生成式对抗网络(GAN)和自动编码器等生成模型来加速图像对抗图像的生成扰动,与基于多步优化的方法(如C&W和PGD)不同,基于生成模型的解决方案旨在从训练图像中学习对抗性扰动的分布。生成模型经过良好的训练后,从输入图像到对抗摄动进行一步生成,这个过程本质上是在生成模型上快速的一次前向传播,从而显著提高了图像对抗摄动的生成速度。
Challenges in Audio Domain
音频领域面临的挑战
图像域上的这些进展自然鼓励了使用生成模型来加速音频对抗摄动生成的探索。然而,音频信号与图像有很大的不同。
- 说话人的声音本质上是一个一维时间序列信号,其中包含非常重要的顺序信息。
- 此外,与定义明确的固定大小的图像数据不同,语音数据通常具有非常不同的信号长度,即使来自同一用户和同一数据集中。
- 除了这些新的音频特定挑战外,基于生成模型的音频对抗性扰动也面临与基于图像的对抗性扰动相同的类特定模型准备问题。具体来说,当利用生成模型进行针对性攻击时,对于每个目标类,都必须训练一个单独的生成模型以用于特定的用途。考虑到类的数量可能非常高,例如数百甚至数千,发动攻击所需的内存成本非常高。
Proposed FAPG: Construction & Training
Overall Architecture
为了解决这些挑战,我们提出了快速音频对抗性摄动发生器FAPG,以快速,高性能和低内存成本的方式发起音频域对抗性攻击。
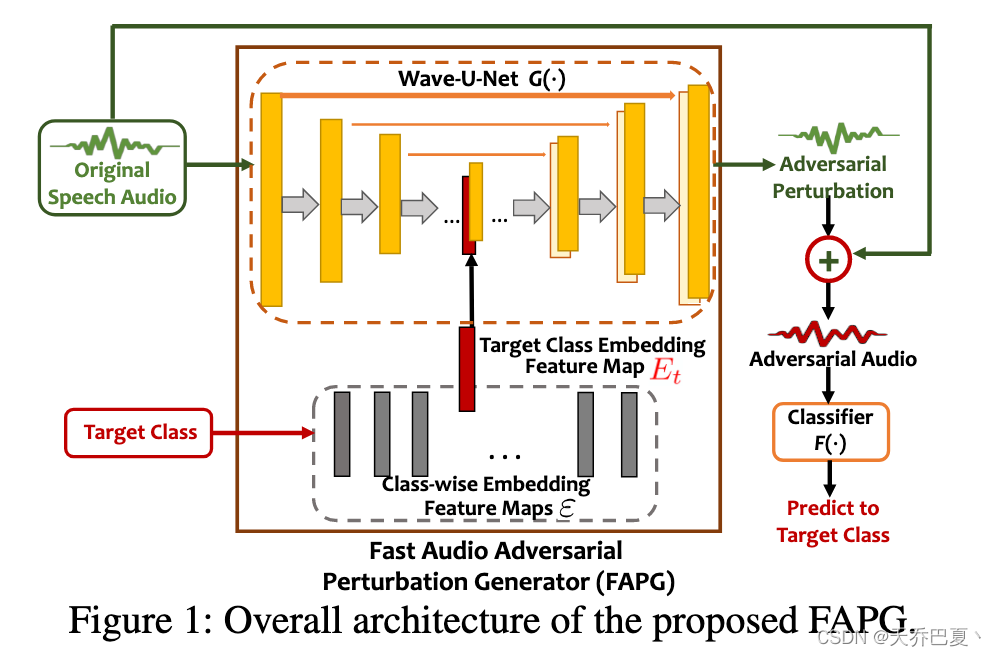
图1展示了FAPG的整体架构,其中包含一个生成模型 G ( ⋅ ) G(·) G(⋅),例如Wave-U-Net (Stoller, Ewert, and Dixon 2018),以及多个按类嵌入的特征映射。
- 在训练阶段,生成模型和嵌入特征映射在训练数据集上进行联合训练。
- 经过适当的训练,给定一个良性音频输入和攻击者计划误导DNN分类器 F ( ⋅ ) F(·) F(⋅)的目标类标签 y t y_t yt,通过生成模型对良性输入的推理,可以快速生成相应的音频对抗性扰动将目标类 y t y_t yt的映射连接到 G ( ⋅ ) G(·) G(⋅)的中间特征映射。
- 接下来,我们将详细描述所使用的生成模型和嵌入特征映射集,如下所示。
Audio-specific Generative Model
音频特定生成模型
生成模型是FAPG的核心组成部分。尽管各种类型的生成模型已经广泛应用于图像域应用,但由于图像和音频信号之间的固有差异(例如序列顺序和长度变化),它们并不适合在FAPG中使用。为了应对这些挑战,我们采用Wave-U-Net 作为FAPG的底层生成模型,该模型最初用于音频源分离。
Wave-U-Net是一种特殊类型的CNN,包含1D卷积、十进制下采样块和线性插值上采样块。这种固有的编解码器结构使Wave-U-Net表现出强大的分布建模能力。同时,其独特的第一层一维卷积和上下采样块设计也使Wave-U-Net可以自然地从一维变长数据中捕获时间信息。
Class-wise Embedding Feature Maps
类感知的嵌入特征映射
使用k类嵌入特征映射的目的是确保可以重用单个生成模型来攻击不同的目标类,而不是特定于类的设计。为此,这些类感知的嵌入特征映射,表示为 ε = ( E 1 , E 2 , … ) ε = {(E_1, E_2,…)} ε=(E1,E2,…),每一个都对应一个目标类。
生成模型 G ( ⋅ ) G(·) G(⋅)与这些嵌入特征映射 ε ε ε联合训练后,将类别 y t y_t yt的标签信息编码到相应的特征映射 E t E_t Et中。
然后在生成阶段,将 E t E_t Et与一个中间特征映射 G ( ⋅ ) G(·) G(⋅)串联起来,形成目标类别 y t y_t yt的对抗性扰动。
在我们的设计中, E t E_t Et具有将被连接到的中间特征映射的完全相同的形状。具体来说, E t E_t Et通常与Wave-U-Net的编码器和解码器部分相交处的中间特征图对齐。这是因为特征图在这个位置的尺寸最小,从而使对应 E t E_t Et的存储成本最小。
Training Procedure of FAPG
FAPG的训练流程
接下来,我们描述了FAPG的训练过程,或者更具体地说,G(·)和ε的联合训练。在整个训练过程的前向传播阶段,对于每一批输入语音数据 X X X,我们首先随机选择一个目标类 y t y_t yt,并获取相应的嵌入特征图 E t E_t Et,将所选择的特征图连接到生成模型 G ( ⋅ ) G(·) G(⋅)中,形成整体模型 G t ( ⋅ ) G_t(·) Gt(⋅)。
对输入 X X X执行 G t ( ⋅ ) G_t(·) Gt(⋅)上的前向传递,结果记为 δ t δ_t δt,将其裁剪到 ( − τ , + τ ) (−τ, +τ) (−τ,+τ)的范围内,以约束生成的扰动 δ t δ_t δt为不可察觉的,其中 τ τ τ是阈值参数。注意,根据我们的实验,初始 τ τ τ应该设置为一个比较大的值,在训练过程中逐渐减小。从经验上看,这种调整方案能带来更好的训练收敛性。
从生成模型中计算出扰动 δ t δ_t δt后,将扰动 δ t δ_t δt加到良性数据上,形成对抗性输入,会导致DNN分类器 F ( ⋅ ) F(·) F(⋅)的误分类。然后,整个训练过程的关键——损失函数的表达式为:
L o s s ( X , y t ) = − y t ⋅ l o g ( F ( X + G t ( X ) ) ) + β ⋅ ‖ G t ( X ) ‖ 2 , Loss(X, y_t) = −y_t · log(F (X + G_t(X))) + β · ‖G_t(X)‖_2, Loss(X,yt)=−yt⋅log(F(X+Gt(X)))+β⋅‖Gt(X)‖2,
其中第一项和第二项分别是交叉熵损失和L2损失,β是一个预设系数。整个损失函数中L2损失的存在是为了控制攻击强度,使生成的对抗性微扰难以察觉。因此,在反向传播阶段,生成模型 G ( ⋅ ) G(·) G(⋅)和当前选择的嵌入特征映射 E t E_t Et通过最小化损失函数同时更新。注意,对于每批数据, E t E_t Et是随机选择的。因此,经过几轮迭代后,生成模型 G ( ⋅ ) G(·) G(⋅)本身学习了对抗性扰动的一般分布,不同的 E t E_t Et学习了每个特定目标类的编码信息。算法1总结了整个FAPG训练过程的细节。

Universal Audio Adversarial Perturbation Generator (UAPG)
通用音频对抗扰动发生器
Motivation
Reducing the Observation of Full Content – Why It Matters?
减少对整个良性输入的观察,为什么是必要的?
如前一节所述,FAPG提供了一种快速解决方案来生成音频对抗性扰动。然而,它本质上是一种依赖于输入的生成方法。事实上,大多数最先进的对抗性攻击方法,在音频和图像领域,都属于输入依赖的攻击类别。换句话说,潜在的扰动产生机制是基于对整个良性输入的观察。
尽管这样的假设对于大多数图像处理应用来说是成立的,但是在现实中要满足这样的要求(实际的实时音频应用)是非常具有挑战性的。这是因为音频信号具有固有的时间序列,在输入流阶段预先知道正在进行的语音输入的全部内容是不现实的。换句话说,攻击只能针对录制或回放的声音执行,从而严重限制了攻击的可行性和场景。因此,除了显著减少扰动产生时间外,实际的音频对抗性攻击还应尽可能减少观察良性输入内容的需求。
Universal Audio Adversarial Perturbation Generator (UAPG).
为此,我们进一步开发了通用音频对抗摄动发生器(UAPG)来制作音频域通用对抗摄动(UAP)。顾名思义,一个通用的对抗性扰动可以被应用到不同的良性输入上,并被重复使用,从而导致错误分类,而不需要输入依赖的扰动的重新生成。这种独特的通用性完全消除了观察整个输入的先验约束,使得UAPG非常适合以零时间成本发起实时音频对抗性攻击。
Challenges of UAPG Design.
UAP的诱人优势已经导致了一些研究图像特异性UAP的努力(Moosavi-Dezfooli et al. 2017;Poursaeed et al. 2018)。借用图像领域研究进展中使用的方法,最近的作品(Vadillo和Santana 2019;Neekhara等人(2019)分别报告了语音命令识别和语音到文本系统的音频域UAP生成方法。
此外,(Gong et al. 2019)还提出了一种无需使用整个语音输入即可实现实时音频对抗性攻击的技术,其效果与使用UAP相似。尽管有这些现有的努力,设计一个鲁棒和强大的UAPG仍然是不平凡的,但面临着两个主要挑战:
- 实验结果表明,目前的音频域UAP通常比输入依赖的扰动具有更低的攻击性能;
- 一些音频域UAP所支持的攻击只是无针对性的攻击,攻击者无法精确地获得期望的目标结果。
Proposed UAPG: Construction & Training
Overall Scheme
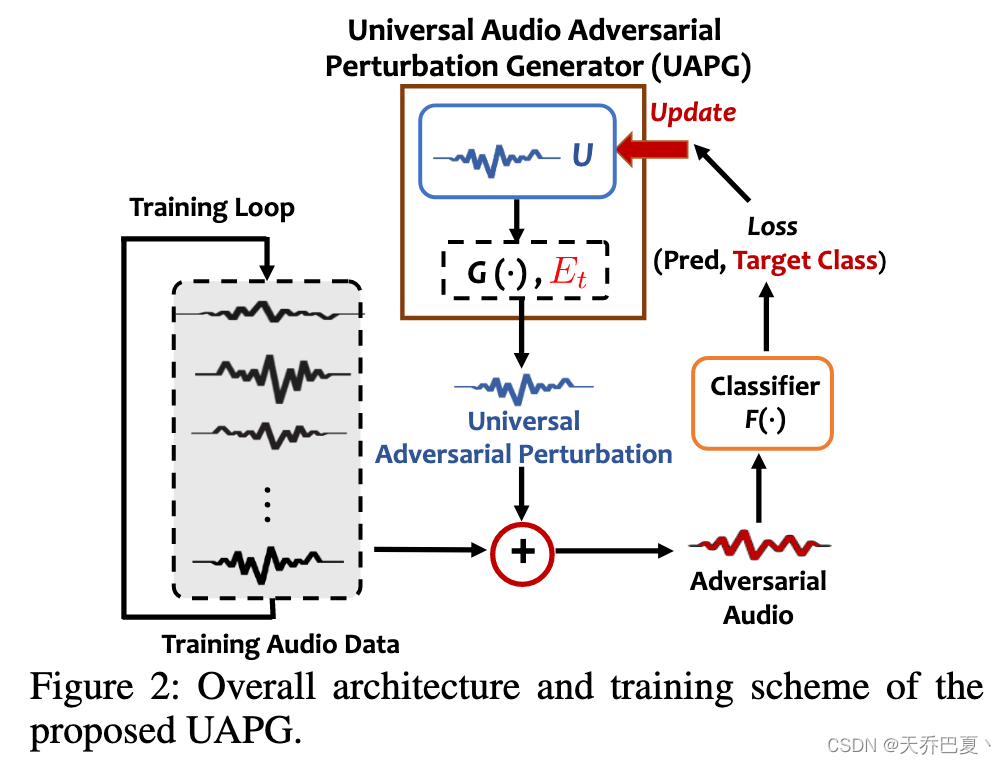
与现有的研究不同,我们的目标是设计一种能够实现高目标攻击性能的UAPG。
图2显示了关键思想:我们基于信号向量U生成一个依赖于输入的UAP,它将被训练成具有一定程度的普遍性。初始化后使用U生成UAPs,并通过迭代的方式在不同的训练数据样本中逐步提高推导出的UAPs的通用性。最后,一个有效的UAPG能够通过发展训练有素的U。
From FAPG to UAPG
用于生成UAP的基本方法是我们提出的FAPG。直观地,FAPG学习估计对抗性扰动的分布,而不是迭代地优化特定音频输入的扰动。因此,FAPG生成的微扰自然比非生成方法产生的微扰具有更好的通用性。此外,我们的FAPG被设计成将各种目标类信息集成到单个生成模型中,从而能够产生目标通用扰动。
Training Procedure of UAPG
然后,我们介绍UAPG的训练细节,以促进有效的UAPG。一般来说,为了形成一个与输入无关的通用攻击,我们的目标是找到一个通用扰动 v t v_t vt来满足
a r g m a x F ( x ( i ) + υ t ) = y t f o r m o s t x ∼ χ . argmax F (x^{(i)} + υ_t) = y_t \; for\; most\; x ∼ χ. argmaxF(x(i)+υt)=ytformostx∼χ.
UAPG的训练过程如算法2所示。

我们的目标是通过训练良好的 G ( ⋅ ) G(·) G(⋅)和相应的 E t ∈ ε E_t∈ε Et∈ε产生一个单一的普适扰动 v t v_t vt,这可以从训练良好的输入依赖的FAPG中得到。与输入依赖的场景不同,音频输入信号现在被单个可训练向量U取代。然后将通用扰动返回并施加到良性数据上以制作对抗性音频示例。通过将这样一个对抗性音频输入DNN分类器F,我们可以通过最小化以下损失函数来更新U:
L o s s = − y t ⋅ F ( X + G t ( U ) ) + β ⋅ ‖ G t ( U ) ‖ 2 , Loss = −y_t · F (X + G_t(U )) + β · ‖G_t(U )‖_2, Loss=−yt⋅F(X+Gt(U))+β⋅‖Gt(U)‖2,
其中第一项和第二项分别表示交叉熵损失和L2损失。在上述损失函数的指导下,我们通过在整个训练数据上迭代应用推导出的 v t v_t vt来优化U。特别是,为了构建一个可以普遍应用于任何目标类的UAPG,在每个训练步骤中,随机选择一个目标类来帮助U学习类间表示。在构建统一的U后,我们的UAPG计算的通用扰动可以有效地应用于任何输入数据,以音频不可知的方式欺骗DNN模型,而不需要为每个单独的音频输入重新生成对抗式扰动。
Attack Evaluation
Experimental Methodology
Target Model and Dataset.
我们在语音指令识别、说话人识别和环境声音分类三种基于dnn的音频系统上对所提出的FAPG和UAPG进行了评估。
- 语音命令识别。我们使用了(Sainath and Parada 2015)中提出的基于卷积神经网络(CNN)的语音命令识别模型(CNN- trade -fpool3),该模型已在许多先前的研究中用作目标模型(Alzantot, Balaji, and Srivastava 2018;Abdoli et al. 2019;Yu et al. 2018)。该网络在一个众包语音命令数据集(Warden 2018)上进行训练,该数据集包含来自10个代表性语音命令的46,278个话语,以16kHz采样,每个记录被裁剪为15个。提取40维MFCC特征作为模型的输入。我们以4:1的比例将数据集随机分为训练集和测试集,该基线模型在测试集上的识别准确率为89.2%。
- 说话人识别。使用基于DNN的嵌入模型和概率线性判别分析(PLDA)后端的预训练x向量模型1 (Snyder et al. 2018)作为目标说话人识别模型。特征为30维MFCC特征,帧长为25ms。我们使用的数据集是CSTR语音克隆工具包(VCTK)中提供的英语多语语料库(Christophe, Junichi, and Kirsten 2016),其中包含109个说话者所说的44217个话语,每个录音被裁剪为1.75秒。演讲者将使用80%的数据进行注册,而其余的数据将保留用于测试。这使得来自109个说话者的8896个测试话语的基线准确率达到了92.8%。
- 环境声音分类。使用一维CNN模型(在(Abdoli, Cardinal, and Koerich 2019)中称为CNNrand)作为目标模型。该模型在UrbanSound8k数据集(Salamon, Jacoby, and Bello 2014)上进行训练,该数据集包含来自10个不同环境场景的8732个音频片段。每一个记录被裁剪到50999个样本,这相当于大约3秒在16千赫。数据集分为训练集、验证集和测试集,比例为8:1:1。经过训练,10个类的分类准确率为83.4%。
评价指标。
- Fooling Rate (FR) 用于评估目标攻击和非目标攻击,它显示了导致错误分类的对抗性示例数量与对抗性示例总数的比率。
- Success Rate (SR) 仅用于评估目标攻击,即导致对抗性示例被归类为目标类的攻击次数与总攻击次数之比。
- Distortion Metric 我们量化了 δ t δ_t δt相对于原始音频 x i x_i xi的相对噪声水平(dB): D ( x i , δ t ) = 20 l o g 10 m a x ( δ t ) m a x ( x i ) D(x_i, δ_t) = 20log_{10} \frac{max(δ_t)}{max(x_i)} D(xi,δt)=20log10max(xi)max(δt)。
Audio-dependent Targeted Attack via FAPG
FAPG Generator Implementation.
我们使用Wave-U-Net的M1模型来构建我们的FAPG。具体地说,我们的模型包含5个下采样块和5个上采样块。最后一个编码层的特征映射大小也是每个附加类嵌入特征映射的大小。对于FAPG,使用ADAM优化器进行了总共10,000个训练步骤,批大小为100。初始学习速率设置为 1 e − 4 1e^{−4} 1e−4,然后逐渐衰减到 1 e − 6 1e^{−6} 1e−6。所有数据集的β均设置为0.1。对于命令识别和说话人识别,初始设置为0.1,对于命令识别和说话人识别,分别在3,000和7,000步长时分别减少到0.05和0.03,对于声音分类模型,停止减少到0.05,导致噪声水平分别接近−30 dB和−18 dB。
Attack Speedup and Performance.
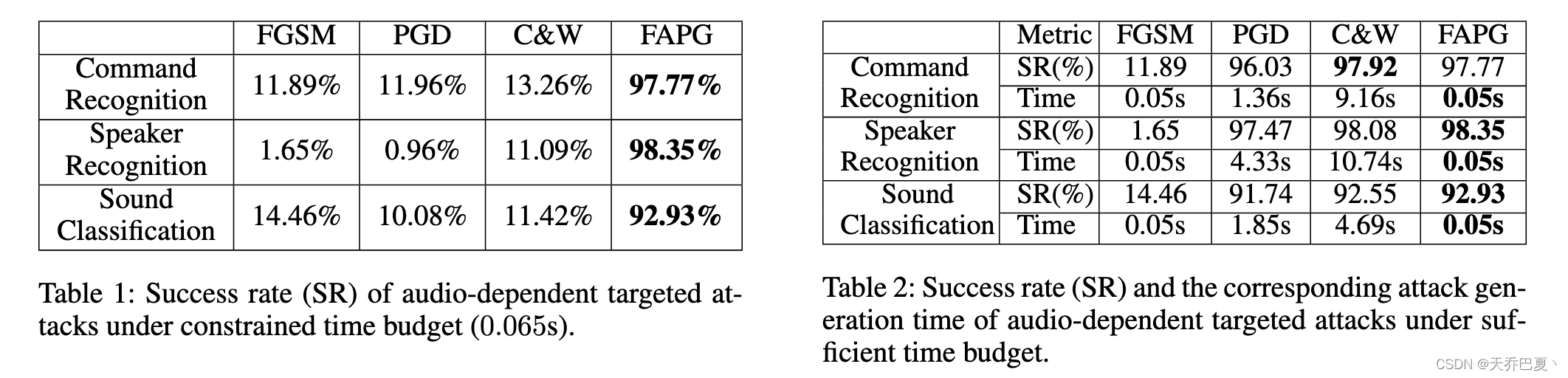
为了验证FAPG在保持较短攻击生成时间的同时获得较高的成功率的能力,我们在不同时间条件下对上述三种目标模型进行了实验。表1将提出的FAPG的攻击性能与常用的攻击进行了比较,即FGSM、PGD、C&W,要求生成对抗性实例的时间不超过0.065s(PGD和C&W攻击中一次迭代的大约执行时间)。为了进行公平的比较,我们对这些攻击产生的扰动进行了约束,对于语音命令分类和说话人识别,我们使用0.03的无穷范数,对于环境声音分类,我们使用0.05的无穷范数,这与FAPG实现中使用的相同。如表1所示,对于所有三种目标模型,所提出的FAPG在短时间预算下都可以实现高攻击成功率(超过90%),而FGSM、PGD和C&W攻击在有限的攻击时间预算下只能实现低于15%的SR。
此外,我们也会在有足够时间预算的情况下进行实验。如表2所示,尽管PGD和C&W实现了与我们提出的FAPG非常相似的SRs,但它们需要更长的对抗摄动生成时间。例如,对于说话人识别任务,PGD需要4.33秒,C&W甚至需要10秒以上的攻击时间,而每个数据的时间周期仅为1.75秒。这种巨大的差距使得基于PGD和C&W的攻击在实际的实时攻击场景中不可行。另一方面,在实现非常相似的高SR的情况下,我们提出的FAPG只需要0.05s就能产生对抗性扰动,从而带来非常高的加速(与PGD和C&W相比分别高达86倍和214倍)。此外,与另一种快速生成方法FGSM相比,FAPG实现了更高的SR。
Memory Cost Reduction
我们提出的可训练分类特征映射可以显著降低内存开销。如果没有分类特征嵌入映射,发起目标攻击需要为每个目标分类训练一个生成模型,这导致语音命令识别、说话人识别和声音分类模型分别消耗23.8 MB、259 MB和23.8 MB的内存。相比之下,采用基于类的嵌入特征图,我们提出的FAPG只需要训练一个生成模型和一组嵌入图,而不考虑目标类的数量,因此这三个目标模型分别只占用2.4 MB、3.53 MB和2.44 MB。这使得内存成本分别降低了9.9倍、73.5倍和9.8倍。
Audio-agnostic Universal Attack via UAPG
UAPG Implementation
UAPG建立在预先训练的FAPG模型和具有与原始音频输入相同大小的可训练通用对抗性输入向量U上。然后在与用于目标模型训练的训练集相同的训练集上训练向量U。使用Adam优化器进行了总共8000个训练步骤,学习率为1e−4,批量大小为100。我们将τ设置为0.03,这对应于语音命令识别模型和说话人识别生成的对抗性扰动的平均失真−30.21dB,而环境声音分类的τ=0.05。
Analysis of Learned Representation

为了研究UAPG的有效性,我们使用主成分分析(PCA)在语音命令识别模型上绘制了由FAPG产生的音频相关的扰动以及由UAPG产生的音频不可知的扰动(Wold, Esbensen, and Geladi 1987)。我们在图3中显示了针对五个命令的对抗性扰动。虽然通用扰动是在不访问真实语音命令分布的情况下创建的,但所有通用扰动都位于为同一目标类生成的相应音频依赖摄动的流形中。
这表明我们的UAPG可以有效地学习相对于每个目标命令的固有对抗性表示。
White-box Attack Performance
我们将我们提出的UAPG的性能与几种最先进的音频通用攻击进行了比较,包括基于DeepFool算法的UAP-HC (Vadillo和Santana 2019) (Moosavi-Dezfooli, Fawzi和Frossard 2016), RURA (Xie等人2020)和UAAP (Abdoli等人2019)。
为了评估UAPG攻击,对于每个目标模型,我们为每个目标类生成一个泛扰动。表3给出了UAP-HC在语音命令模型上的结果,RURA在说话人识别模型上的结果,UAAP在声音分类模型上的结果,以及提出的UAPG在这三个模型上的结果。具体来说,由于UAP-HC被设计为非目标的通用攻击,我们只报告其FR。
我们观察到,我们提出的UAPG在所有三个任务上都优于现有方法,在三个模型上分别评估的平均SR为89.90%,89.59和86.05%。
Black-box Attack Performance
我们还评估了所提出的UAPG在黑盒设置下的性能,其中目标受害者模型的架构和参数是未知的。对于每个任务,我们首先在替代模型(CNN-3模型(Zhang et al. 2017), d-Vector (Variani et al. 2014), EnvNetV2 (Tokozume and Harada 2017))上训练UAPG,如表4所示,然后在目标模型上评估生成的对抗示例以研究其可转移性。
对于语音命令识别模型,我们以黑箱方式比较了所提出的UAPG与最近在同一目标模型上的无目标实时对抗性攻击(RAA) (Gong et al. 2019)的性能。如表4所示,即使在不同任务的黑盒设置中进行测试,我们提出的UAPG也实现了高FR。与目前最先进的无目标实时攻击RAA相比,我们的UAPG实现了FR增加29.98%。
Conclusion
在这项工作中,我们提出了一种快速和通用的对抗性攻击三种音频处理系统:语音命令识别,说话人识别和环境声音分类。通过利用Wave-U-Net和分类特征嵌入图,我们提出的FAPG可以在单次前向传播中使用统一的生成模型,针对任何语音命令发起快速音频对抗性攻击,与最先进的解决方案相比,对抗性扰动生成速度高达214倍。此外,在FAPG的基础上,我们提出的UAPG能够产生通用的对抗性扰动,可以应用于任意良性音频输入。大量的实验证明了所提出的FAPG和UAPG的有效性。