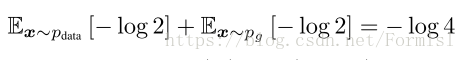Generative Adversarial Nets
- 这篇文章思想之大在于将生成器和判别器结合在一起,前无古人。
gan网络的开山之作,一个全新的网络,带有生成器(G)和判别器(D),生成器用来描述数据的分布,判别器是用来判别生成数据和真数据的差别或真假(可以用概率来描述真假的程度)。G应尽可以使D犯错。犹如两人的游戏,双方总想自己能赢。在函数空间中,总存在一类G和D,G能恢复训练数据集分布,D等于0.5。这篇论文用的是多层感知机。
- 对抗网络(Adversarial nets)
训练集数据分布x,定义噪声的z的先验概率p_{z}(z);
首先定义,G(z;\theta_{g}),G是从z映射x的分布,可微分;
D(x,\theta_{d}),D是x到常量映射,可微分;
目的最小化log(1-D(G(z))),如果G(z)生成最接近x分布的数据,D(G(z))则判断是x,因此此时值很大,即log(1-D(G(z)))很小。
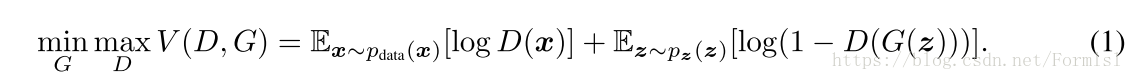
为了让两者结合训练,文章提出一个优化问题,上式。最小化log(1-D(G(z))),即最大化log(D(x)),即最大化D(x)。G(z)最小化。
算法1 mini随机梯度下降法,第k步训练D,论文用的k=1
for 训练次数 do
for k steps do
- 从噪声先验p_{g}(z)中采样m个minibatch
- 从真数据集分布p_{data}(x)采样m个minibatch
- 更新判别器D,由下面的梯度更新
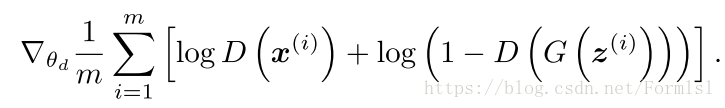
end
- 从噪声先验p_{g}(z)中采样m个minibatch
- 更新生成器G,由下面的梯度更新
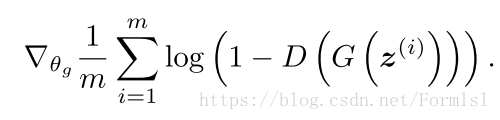
end
- 从数学上证明存在全局最优解:
命题1 :对于固定的G,优化的D是 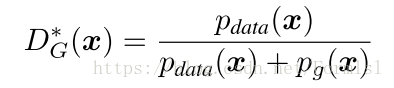
证明.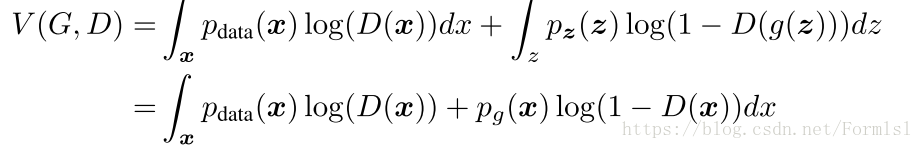
一个函数y=alog(y)+blog(1-y),y\in[0,1]他的极大值很明显是a/(a+b)
即上式
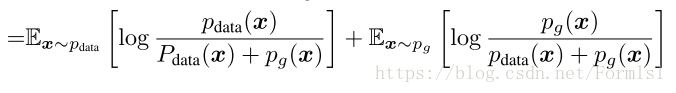
理论1.在D(x)取极值点时,C(G)=max_{D}V(G,D)能达到值是:
我们可以将C(G)转化另一种形式,p_g和p_{data}相似度量散度和极值点之和。
- 算法1的收敛性:
命题2:如果G和D参数足够多(有充足容量)通过算法1判别器D会使得p_{g}收敛到p_{data}
证明:使在迭代过程V(G,D)=U(p_{g},D),记U(p_{g},D)是一个凸函数