说明:以下内容是自己看论文的一些拙见,如有错误请指正。
《Generative Adversarial Nets》是Goodfellow大神在受到“二人零和博弈”的影响之后写出的GAN的开山之作。
GAN的基本原理比较简单:假设我们有两个模型,一个用来捕获数据分布的生成模型G(Generator)和一个用来估计样本来自训练数据而不是G的概率的判别模型D(Discriminator),G的训练过程是最大化D产生错误的概率。
以上是原文中所描述的内容,比较难以直接理解。做如下通俗解释:
G:是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
D:是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x) 代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
而G的训练过程就是尽可能的生成与真实图片相一致的图片,并让D相信它是真的;D的训练过程就是尽可能的区分一张图片是真实图片或G生成图片。在D和G的训练过程中,就构成了一个动态的博弈。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
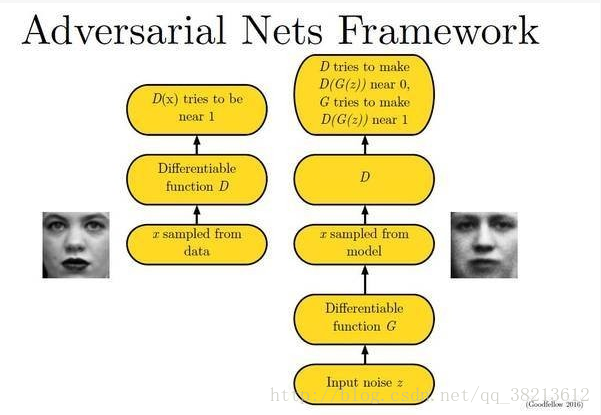
下面的图片很好的描述了这个过程:
用数学公式来表示,D和G的训练是关于值函数V(G,D)的极小化极大的二人博弈问题:
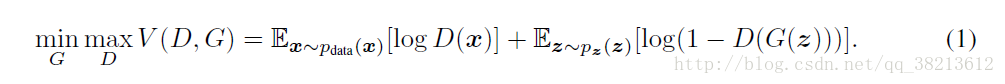
G希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
以上的训练过程看起来很清晰,我们只需要两步就能得到真实数据的分布,但现实中却并非如此。
第一,我们的 generator 并不是一个真正的「生成样本」的分布,通常我们的用作 generator 的模型的 capacity 都是有限的,它很大可能只是生成了所谓「生成样本流形」中一个子流形。所以如果我们用这样的 generator 生成的样本和真实样本去训练 D ,是不可能得到真正的 P(c|X) 的(关于这个概率,意思就是说在图片是真实图片的情况下,D判断其为真的概率),直觉上而言,因为这样的 discriminator 只能把一个子流形与真实样本模型分开,所以这个 discriminator 可能太「松」。
第二,D 的 capacity 也有限。
所以,在现实中,我们没法用两步优化就得到真实样本的概率分布。论文里提出了一种交替优化的方法解决这个问题。

第一步我们训练D,用 SGD ,先对做 k 步等式(1)内部最大化。D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,外部的最小化。V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。D 每次优化都达到最优的时候,G 学习到的概率分布收敛于真实分布。
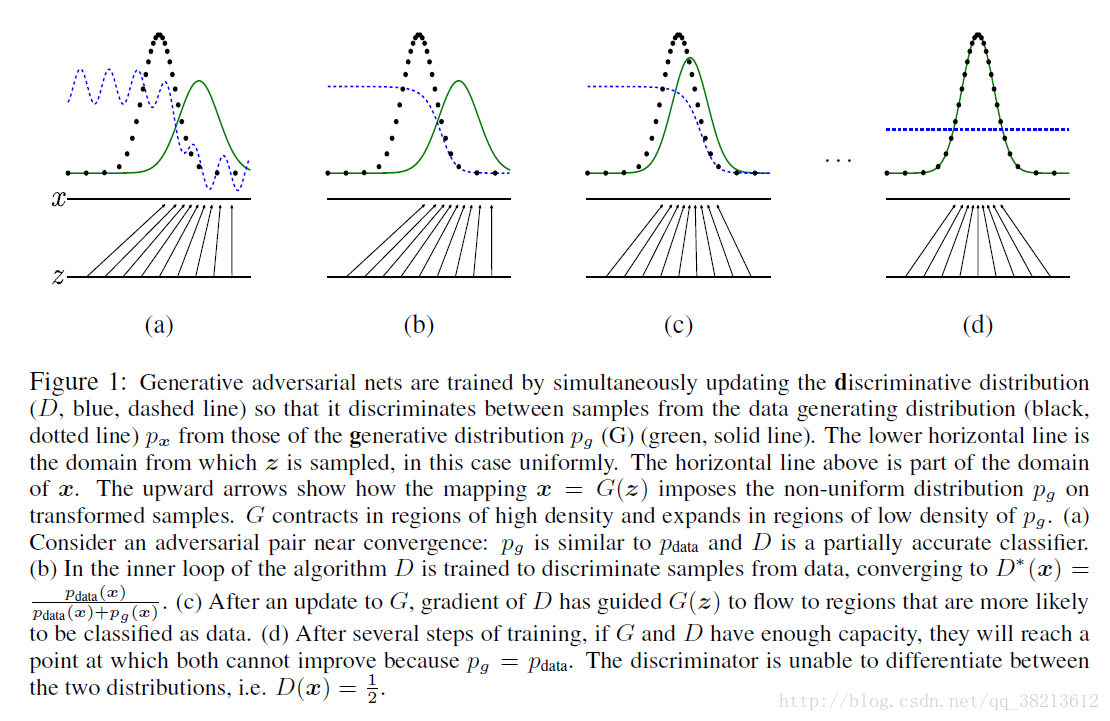
图1.训练对抗的生成网络时,同时更新判别分布(D,蓝色虚线)使D能区分数据生成分布px(黑色虚线)中的样本和生成分布pg (G,绿色实线) 中的样本。下面的水平线为均匀采样z的区域,上面的水平线为x的部分区域。朝上的箭头显示映射x=G(z)如何将非均匀分布pg作用在转换后的样本上。G在pg高密度区域收缩,且在pg的低密度区域扩散。(a)考虑一个接近收敛的对抗的模型对:pg与pdata相似,且D是个部分准确的分类器。(b)算法的内循环中,训练D来判别数据中的样本,收敛到:D∗(x)=pdata(x)/[pdata(x)+pg(x)]。(c)在G的1次更新后,D的梯度引导G(z)流向更可能分类为数据的区域。(d)训练若干步后,如果G和D性能足够,它们接近某个稳定点并都无法继续提高性能,因为此时pg=pdata。判别器将无法区分训练数据分布和生成数据分布,即D(x)=1/2。
当训练刚开始时候,D(G(z)) 很小,这时候 log(1-D(G(z))) 趋向饱和,而 logD(G(z)) 的导数却很可观,所以与其最小化 log(1-D(G(z))) 不如最大化 logD(G(z)) 。
剩下关于对算法的证明 ,文章中讲的很详细,不赘述。