Swin Transformer: Hierarchical ViT using Shifted Windows
概述
1.SwinTransformer想设计一个可以作为密集预测任务的Transformer Backbone,其采用PatchMerging的策略,构建了层次化的特征,使得其可以作为密集预测任务的Backbone。
2.同时考虑到密集预测任务中,tokens数目太多导致计算量过大的问题,其采用一种在local window内部计算Self-Attention的机制去降低计算复杂度,使得整体计算复杂度由O(N^2)降低至O(N)水平。
3.为了弥补Local Self-Attention带来了远程依赖关系缺失的问题,其创新性地采用了Shift Window操作,引入了不同window之间的关系,并且在精度以及速度上都超越了简单的Sliding Window的方法。
核心思想
Swin Transformer就是想让 Vision Transformer像卷积神经网络一样,也能够分成几个 block(分组计算),也能做层级式的特征提取,从而导致提出来的特征有多尺度的概念
分组计算的复杂度优势
- 原生 Transformer 对 N 个 token 做 Self-Attention ,复杂度为 NxN,
0 Swin Transformer 将 N 个 token 拆为 N/n 组, 每组 n (n设为常数)个token 进行计算,复杂度降为 [N*nxn] ,考虑到 n 是常数,那么复杂度其实为N。
分组计算导致的问题和解决方式
- 其一是分组后 Transformer 的视野局限于 n 个token,看不到全局信息
- 对于问题一,Swin Transformer 的解决方案即 Hierarchical,每个 stage 后对 2x2 组的特征向量进行融合和压缩(空间尺寸HxW变成0.5Hx0.5W,特征维度C->4C->2C ),这样视野就和 CNN-based 的结构一样,随着 stage 逐渐变大。
- 其二是组与组之间的信息缺乏交互。
- 对于问题二,Swin Transformer 的解决方法是 Shifted Windows,
整个Swin Transformer其实最重要的就两个点:
- 相对位置信息
- 核心点在于可以把每种相对位置信息和att对应的一行信息对应上
- 移动窗口注意力机制
- 移动窗口注意力机制核心点在于mask,mask矩阵的生成是通过窗口索引tensor相减得到的;
综合就是两个优点:
- 相比于ViT,Swin Transfomer 计算复杂度大幅度降低,具有输入图像大小线性计算复杂度。
- Swin Transformer随着深度加深,逐渐合并图像块来构建层次化Transformer,可以作为通用的视觉骨干网络,应用于图像分类、目标检测和语义分割等任务。
Swin transformer和viT的架构不同之处:
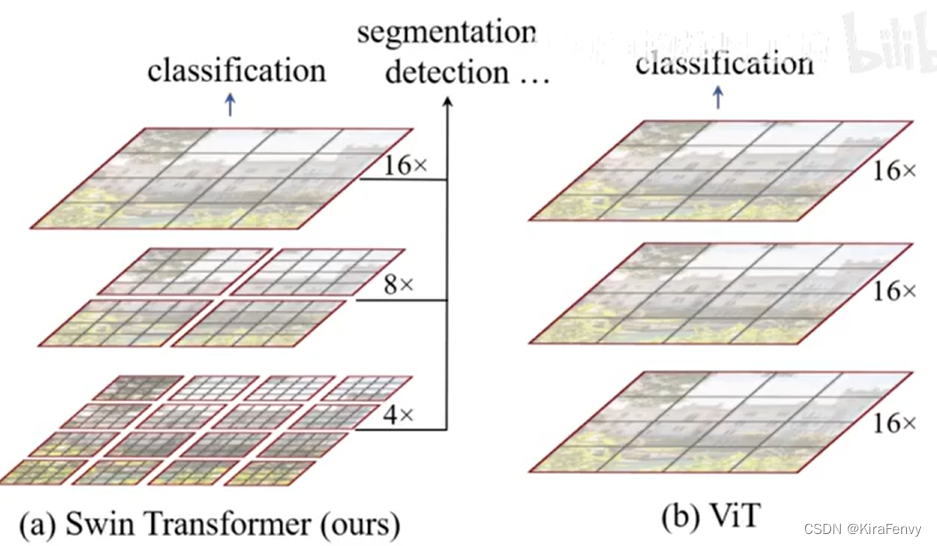
整体结构
上图有四个stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
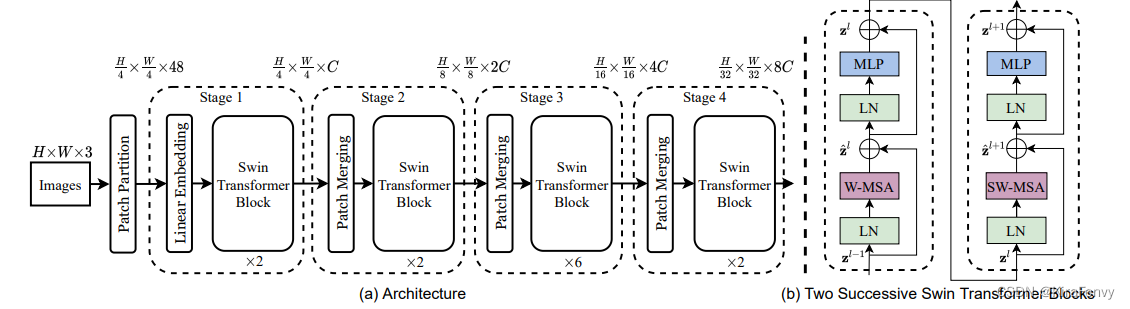
流程解释:
- 在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。
- 在每个Stage里,由Patch Merging和多个Block组成
- Patch Merging模块主要在每个Stage一开始降低图片分辨率
- Block具体结构如右图所示,主要是LayerNorm(LN),MLP(Multilayer Perceptron多层感知器),Window Attention 和 Shifted Window Attention组成
名词解释
假设输入图片的尺寸为224X224,先划分成多个大小为4x4像素的小片,每个小片之间没有交集。

- patch:224/4=56,那么一共可以划分56x56个小片。每一个小片就叫一个patch,
- token:每一个patch将会被对待成一个token。所以patch=token。
- window:而一张图被划分为7x7个window,每个window之间也没有交集。那么每个window就会包含8x8个patch
与vit区别
- patch大小:与ViT一样对于输入的图像信息先做一个PatchEmbed操作将图像进行切分后打成多个patches传入进行后续的处理,但与ViT不同的是初始的切分不再以16 * 16的大小,而是以4 * 4的大小(为了看到更多细节)
- PatchMerging且后续通过PatchMerging的操作不断增加尺寸,进而可以得到多尺度信息便于在目标检测和语义分割中的使用
- 位置编码:ViT在输入会给embedding进行位置编码。
Swin-T这里则是作为一个可选项(self.ape),Swin-T是在计算Attention的时候做了一个相对位置编码 - 分类:ViT会单独加上一个可学习参数,作为分类的token。
Swin-T则是直接做平均,输出分类,有点类似CNN最后的全局平均池化层
模型处理过程
概括
PatchEmbed将图像换分为多个patches,
之后接入多个BasicLayer进行处理(默认是和上述结构图一致,4个虚线框中的结构),
再然后将结果做avgpool输出计算结果,
最后再进行分类操作(所以这里与ViT中不一样的是并没有采用一个cls token来进行分类而是对多个tokens取均值参与最终的分类运算)
Patch Embedding
不能直接将一整幅图片作为一个patch,所以需要对图像进行切分然后处理为一个patch,但与ViT不同的是,Swin-T不在以16*16作为一个切割大小,而是以4 * 4作为切分大小,并通过后续的Patch Merging操作不断增大每个Patch的大小,进而实现多尺度变化
BasicLayer
生成Patch之后就进入Swin- Transformer的核心模块部分了,每个basiclayer主要是由若干个Swin-Transformer Block和一个Patch Merging
Patch Merging
- 作用:是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 ,类似于CNN中Pooling层。进而形成层次化的设计,同时也能节省一定运算量。
- 启发:在做Window Attention这个操作时,数据的维度变换是和CNN是有些相似的地方的,当然SwinTransformer的初衷也是想让Transformer能像CNN一样能够分成多个Block,进而在不同层级的Block之间提取到分辨率不同的特征信息,
- 实现:SwinTransformer引入了Patch Merging操作来实现,类似于CNN的池化的操作
在CNN中,则是在每个Stage开始前用stride=2的卷积/池化层来降低分辨率。
每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。
然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍
Swin Transform Block
这部分是整个程序的核心,它由窗口多头自注意层(window multi-head self-attention, W-MSA)和移位窗口多头自注意层(shifted-window multi-head self-attention, SW-MSA)组成
包含了论文中的很多知识点,涉及到相对位置编码、mask、window self-attention、shifted window self-attention
整体流程如下:
- 输入到该stage的特征 z的l-1 先经过LN进行归一化
- 再经过W-MSA进行特征的学习,
- 接着的是一个残差操作得到 z ^ l z\hat{}^l z^l的估计值(头上带个帽子就是估计值的意思)。
- 接着是一个LN,一个MLP以及一个残差,得到这一层的输出特征 z l z^l zl。
- SW-MSA层的结构和W-MSA层类似,不同的是计算特征部分分别使用了SW-MSA和W-MSA,
可以从上面的源码中看出它们除了shifted的这个bool值不同之外,其它的值是保持完全一致的。这一部分可以表示为式(2)
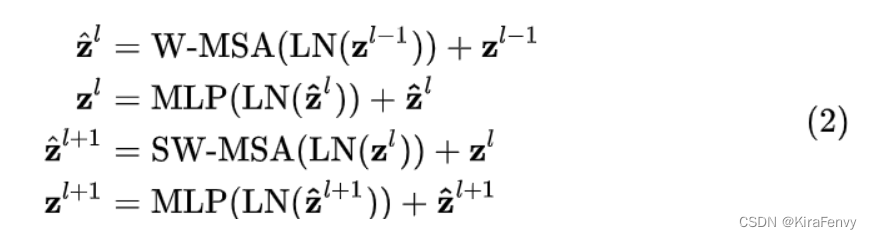
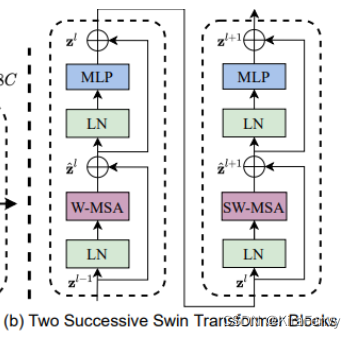
Swin Transformer使用window self-attention降低了计算复杂度,为了保证不重叠窗口之间有联系,采用了shifted window self-attention的方式重新计算一遍窗口偏移之后的自注意力,所以Swin Transformer Block都是成对出现的 (W-MSA + SW-MSA为一对) ,不同大小的Swin Transformer的Block个数也都为偶数,Block的数量不可能为奇数。
Window Attention
传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。
而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。
Window Attention与传统的Attention主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码
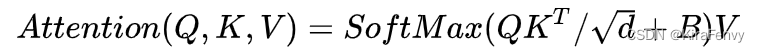
绝对位置编码是在进行self-attention计算之前为每一个token添加一个可学习的参数,
相对位置编码如上式所示,是在进行self-attention计算时,在计算过程中添加一个可学习的相对位置参数B。
实际上这里在参与Attention计算的B 是relative_position_bias_table这个可学习的参数,而relative_position_index则是作为一个index去取relative_position_bias_table中的值来参与运算
有了相对位置索引(relative_position_index)之后,后续将相对位置bias(relative_position_bias_table)加入 Q K T QK^T QKT 中
这里比较难理解的就是relative_position_index的生成代码,如下图所示为整个relative_position_index的生成过程:
假设window_size = 2*2即每个窗口有4个token [M=2] ,如图1所示,在计算self-attention时,每个token都要与所有的token计算QK值,如图2所示,当位置1的token计算self-attention时,要计算位置1与位置(1,2,3,4)的QK值,即以位置1的token为中心点,中心点位置坐标(0,0),其他位置计算与当前位置坐标的偏移量。
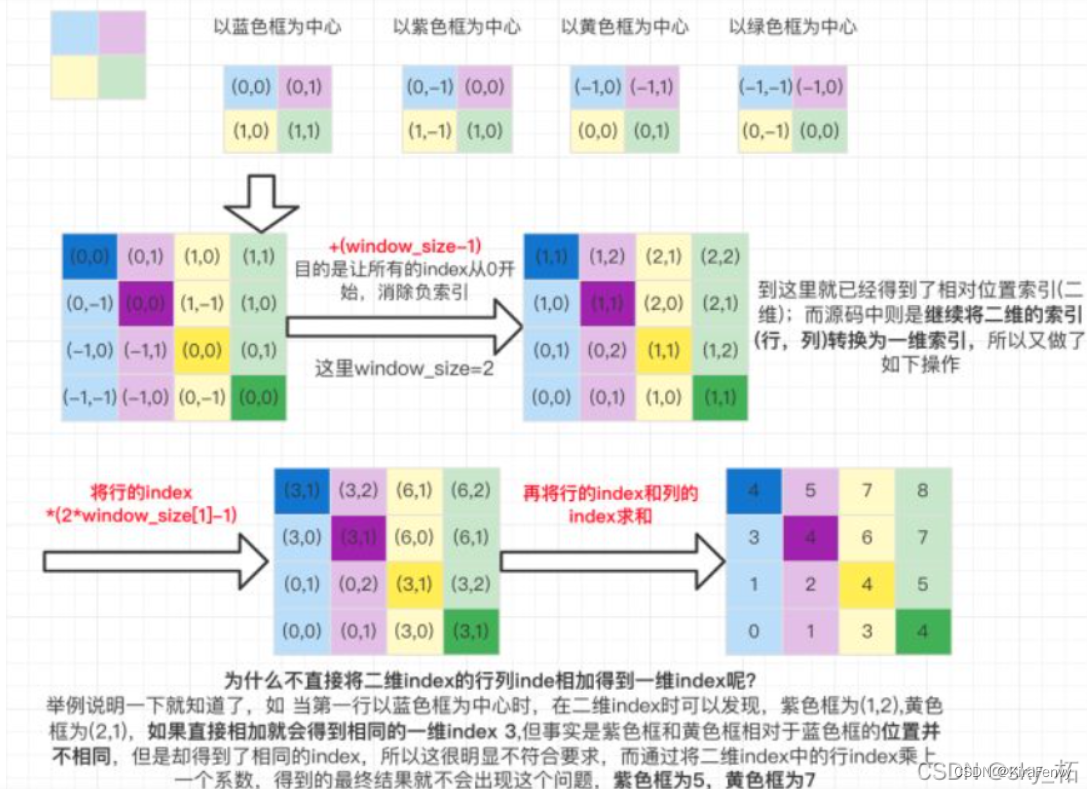
第一行就是以蓝色为中心的坐标,第二行是以紫色框为中心各颜色框的坐标,以此类推
下图没有明确的计算过程但更加清晰
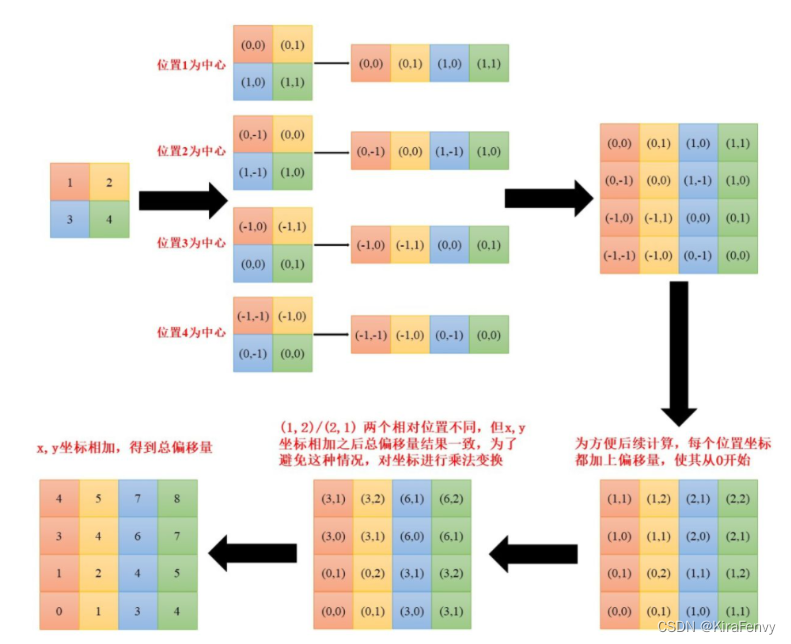
然后再最后一维上进行求和,展开成一个一维坐标,并注册为一个不参与网络学习的变量
Shifted Window Attention
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。
shifted window也就是把左侧的“规则”windows变为右侧“不规则”的windows,因为这样就能实现左侧“规则”windows之间的“信息交流”
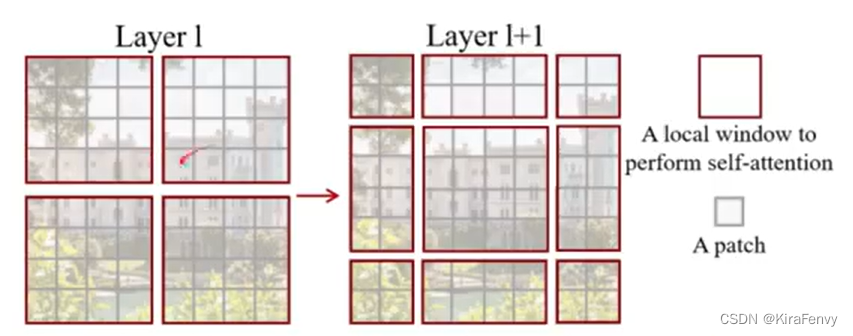
左边是没有重叠的Window Attention,而右边则是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。
为此论文提出了一种针对于shifted window Attention更加高效的计算方式,如下图所示,为论文提供的高效计算shifted window Attention的示意图
在实际代码里,我们是通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
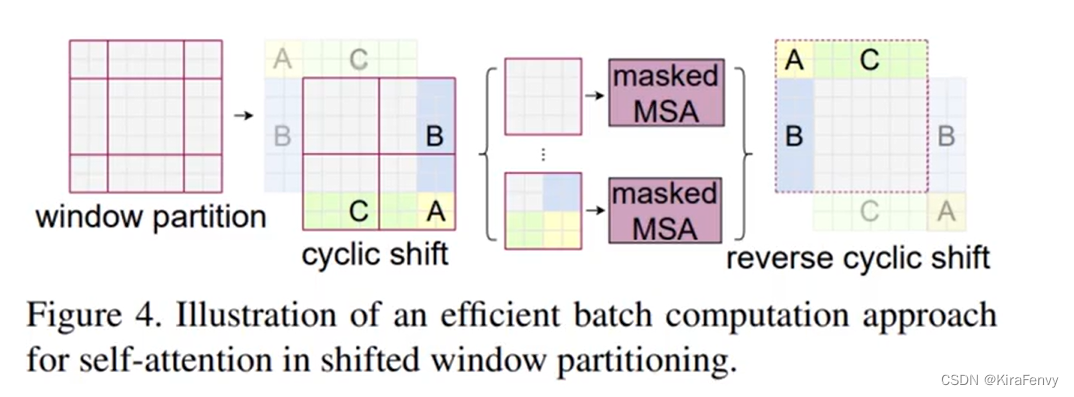
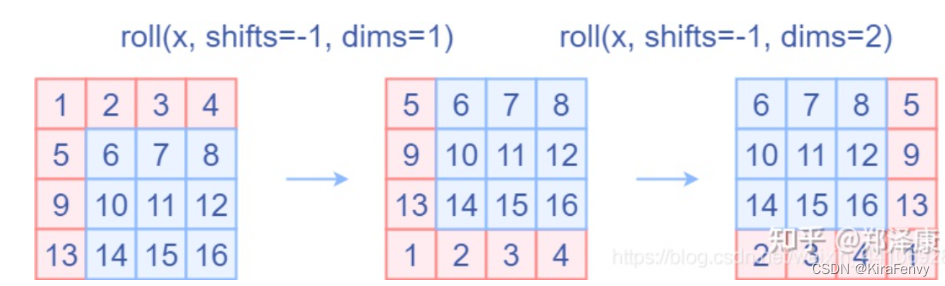
- 将特征数据进行cyclic shift操作,这个操作具体的代码中是使用的torch.roll实现的,如下图,通过将A B C三个区域的数据移动到如图的位置,那么整个窗口的划分就变得大小一致了
 2. Attention Mask:通过设置合理的mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。得到大小一致的窗口之后,再进行带掩码的MSA操作,因为shift之后windows的大小都一致,所以在进行Attention计算时就比较好并行计算,同时通过掩码的作用,原本不属于同一个窗口的数据进行Attention之后也不会得到较高的注意力(比如蓝天和草原之间的Attention值就不会高)。
2. Attention Mask:通过设置合理的mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。得到大小一致的窗口之后,再进行带掩码的MSA操作,因为shift之后windows的大小都一致,所以在进行Attention计算时就比较好并行计算,同时通过掩码的作用,原本不属于同一个窗口的数据进行Attention之后也不会得到较高的注意力(比如蓝天和草原之间的Attention值就不会高)。
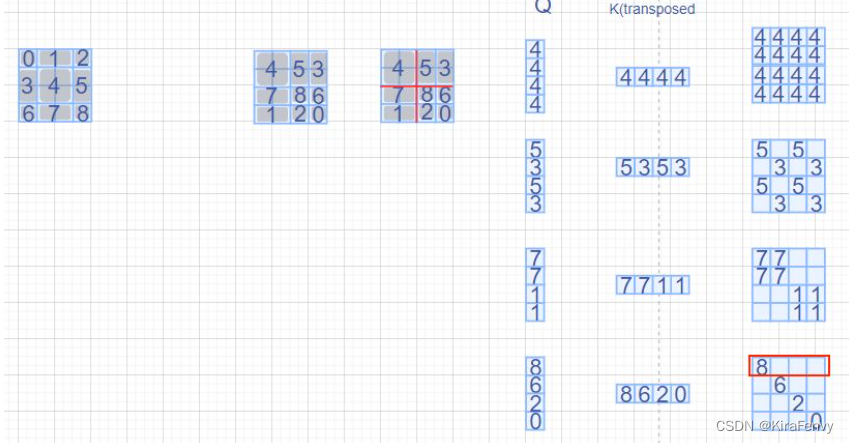
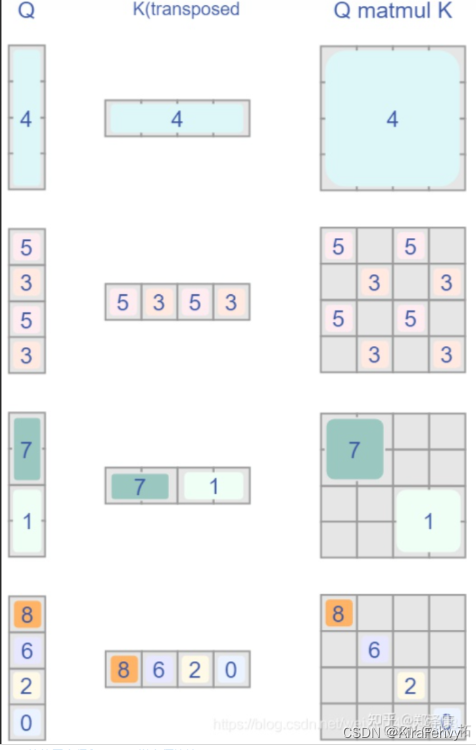
如下图,window_size=2,shift_size=-1,最左侧方块所示,我们分别对这9个方块编号为0~8,那么经过roll处理以后,每个区域的位置分布就如第二个方块所示;
再以window_size在每个window内做带掩码的MSA,具体而言就是相同编号的区域做MSA时就没有mask,不同区域之间做MSA就需要有掩码,例如
右下侧的那个window内一共有4个区域的数据(8,6,2,0),那么区域8的Q只和区域8的K^ T相乘时才不带掩码,与其他区域的K^T相乘都需要带掩码,计算结果就如右下侧的红色框中所示:
3. reverse cyclic shift
把之前cyclic shift的shift参数设置成对应的正数就行
小结
首先我们对Shift Window后的每个窗口都给上index,并且做一个roll操作(window_size=2, shift_size=-1)
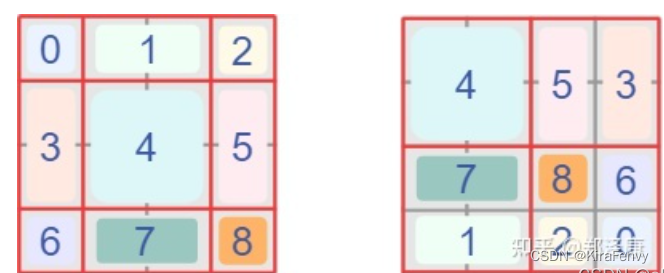
希望在计算Attention的时候,让具有相同index QK进行计算,而忽略不同index QK计算结果。
而要想在原始四个窗口下得到正确的结果,我们就必须给Attention的结果加入一个mask(如下图最右边所示)
最后正确的结果如下图所示
引入window这一个概念,将CNN的局部性引入,还能控制模型整体计算量。
在Shift Window Attention部分,用一个mask和移位操作,很巧妙的实现计算等价。
模型使用及代码
模型使用
环境配置
环境配置参考Swin Transformer算法环境配置(语义分割)
SwinT
Swin-Transformer最核心的部分制成了一个类似于nn.Conv2D的接口并命名为SwinT。其输入、输出数据形状完全和Conv2D(CNN)一样,这极大的方便了使用Transformer来编写模型代码。
参考SwinT-让Swin-Transformer的使用变得和CNN一样方便快捷
代码
代码讲解参考Swin-Transformer(原理 + 代码)详解
非常详细的原理和代码展示【深度学习】详解 Swin Transformer (SwinT)
Patch Embedding
-
Patch Partition
作用:将RGB图转为非重叠的patch块。这里的patch尺寸为 4x4,乘上对应的RGB通道可得大小为4 x 4 x3=48。 -
Linear Embedding
作用:将处理好的patch投影到指定的维度,这里embed_dim=96。 -
核心代码实现
通过设定固定大小(4*4)的patch进行卷积,实现Patch Partition,再设定输出通道实现 Linear Embedding
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size,stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
Patch Merging
作用:将传入矩阵划分为2 x 2 大小的窗口,每个窗口的对应位置(例如下图中的同色块[^3])相merge,再对merge后的四个特征矩阵相concatenate。最后经过layer normalization和linear layer降维。
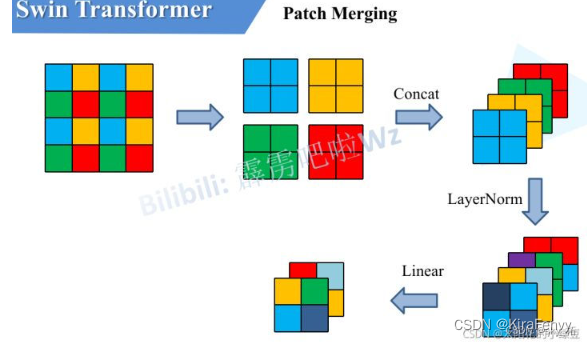
Layer normalization和Linear layer的初始化
self.norm = norm_layer(4 * dim)
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
其中由图可知,每一层通道在传递给LayerNorm时都是原通道的4倍。传递给Linear时同理,Linear的输入为原通道的4倍,输出为原通道的2倍。
Merging的实现
def forward(self, x, H, W):
"""
x: B, H*W, C
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
# to pad the last 3 dimensions, starting from the last dimension and moving forward.
# (C_front, C_back, W_left, W_right, H_top, H_bottom)
# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
其中12-17行的作用是对行数或者列数是奇数的层进行扩充;
19-24完成的是Merging操作,即每隔2行2列取一次元素并将这些元素沿最后一个维度(通道维度)concat
Mask
构建Mask是为了以后SW-MSA移动后窗口只对连续部分做self-attention,整个构建过程分为两步。
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍,起到了padding的作用
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1