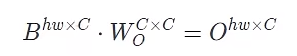原文地址:https://arxiv.org/pdf/2103.14030.pdf
收录:CVPR 2021 Best paper
代码: https://github.com/microsoft/Swin-Transformer
摘要
目前Transformer从文本领域 应用到 图像领域主要有两大挑战:
- 视觉实体变化大,在不同场景下视觉Transformer性能未必很好 large variations in the scale of visual entities。但In existing Transformer-based models, tokens are all of a fixed scale.
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大 the high resolution of pixels in images compared to words in text, as the computational complexity of its self-attention is quadratic to image size.
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计a hierarchical Swin Transformer。
其中shifted windowing scheme滑窗操作包括: 不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
1 introduction
Modeling in computer vision has long been dominated by convolutional neural networks (CNNs). 但NLP领域里 the prevalent architecture today是Transformer。
本文想要扩展transformer的应用性,因为它可以被当做一个for CV的通用任务的backbone,就如同在视觉里CNN做的一样。

为了解决上面两个问题,本文提出一个 hierarchical feature maps 其具有has linear
computational complexity to image size。如上图的a, Swin Transformer 构建一个层次性的representation 通过一开始是small-sized patches (outlined in gray)然后逐渐合并 neighboring patches 在更深的Transformer layers。通过这种层次性的结构,Swin Transformer可以方便地利用密集预测的advanced技术,例如Unet 和 FPN。
Swin Transformer 的一个关键设计元素是它在连续的自注意层之间移动窗口分区 shift of the window partition,如图 2 所示。

The shifted windows桥接前一层的窗口,在它们之间提供连接,从而显着增强建模能力(see Table 4). 这种策略在real-world latency方面也很有效: 在窗口的all query patches 分享一样的 key set 1 , 这有利于硬件中的内存访问。相比之下,早期基于滑动窗口的自注意方法suffer from low latency 在通用硬件上,因为不同的key sets 对 different query pixels 2 . (在通用硬件上实现基于滑动窗口的卷积层有许多有效的方法,是由于在feature map中kernel共享权重。但基于滑动窗口的SA层在实践中很难实现有效的内存访问。) 实验可看出shifted window 比sliding window有更低的延迟,和类似的性能。
我们相信,跨 CV和NLP的统一架构可以使这两个领域受益,因为它将促进视觉的和文本信号的联合建模,并且可以更深入地共享来自这两个领域的建模知识。
3. Method
3.1. Overall Architecture
patch merging

layer norm和linear 都是再channel方向上做的


3hwc^2是得到QKV的时候执行的线性变换,Q=WA = hw,hw *hw,c
2(hw)^2c是QK,AV相乘的时候
![]() ,最后一个hwc ^2是多头融合的时候
,最后一个hwc ^2是多头融合的时候