6.一脚踹进ViT——Swin Transformer(下)
一、Shift-Window Attention
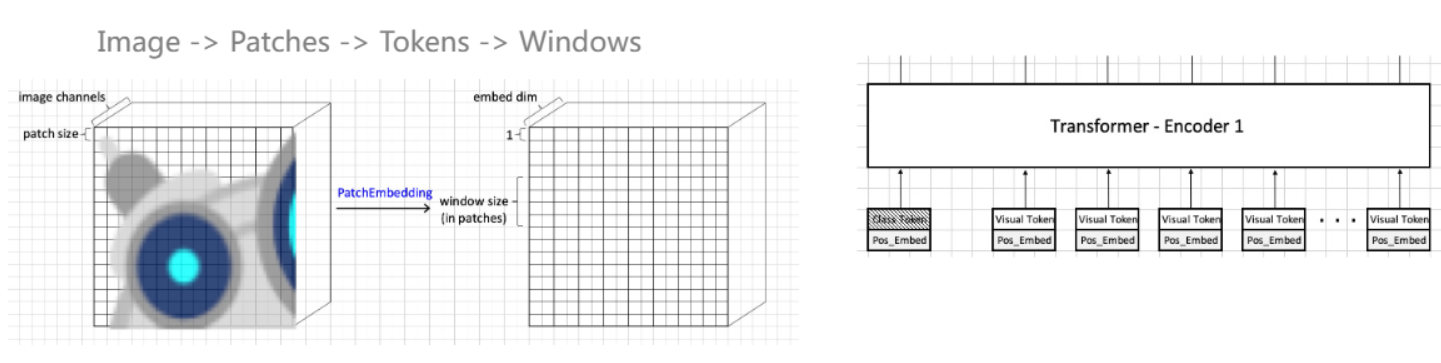
image输入后提一个patch块,如果是4×4=16个pixel,就把它展开,来做conv/proj,经过处理后它就变成1×embed dim的tensor, 每一个就叫做embedding或vision tokens,真正输入Transformer的就是embedding或vision tokens,我们在此基础上需要进行切分window
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U49jPYv3-1678526687222)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310211749075.png)]](https://img-blog.csdnimg.cn/8bf777403da9452eae7f448396ab0285.png)
上一节我们就是这样的进行window的划分,我们上图划了四个窗口,每一窗口里面一个小的格子就是embedding或vision tokens,Swin Transformer的第一步就是对单个窗口来做self-attention,但有一个问题,Window之间没有交互,那我希望每个token能看到gloab的信息应该怎么做呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CFnsTTaY-1678526687223)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310212751296.png)]](https://img-blog.csdnimg.cn/06183b6c61b44d9aababaafc880e6bfd.png)
最简单的办法可以类似卷积一样,画一个window,在某一个window大小上做一个滑窗操作,在该window中做self-attention
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XyvhfNf6-1678526687223)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310213256135.png)]](https://img-blog.csdnimg.cn/ae507d84bd944382b9ac1a1bde3bd27d.png)
Swin 论文提出了 Shift-Window Attention,之前是每个颜色单独算自己的attention,与其他颜色无关,为了改变这种情况,Swin在算完一次Window的Self-attention之后,更换了划分window的方式,这样划分完之后,窗口内的注意力就有了其他颜色的token
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Cb5dZWF-1678526687223)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310213331198.png)]](https://img-blog.csdnimg.cn/376816556afc44b4a5417bce4d055639.png)
所以我们的Task:对每个Window单独计算WMSA,可以单独做,但我们要找一个高效的方式来做
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vj7IfGD0-1678526687223)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310215236184.png)]](https://img-blog.csdnimg.cn/d0da756f69c44389b3989a8e8e56a7bb.png)
首先看一下位移怎么做,1<<3 ,01变成1000,二进制变为十进制就是8,那这种方式就是位移的操作,可以用numpy.roll,tensor.roll来实现,其中用到的是循环填充。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZzUv7VzK-1678526687224)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310220256507.png)]](https://img-blog.csdnimg.cn/eb5f9ee8bb4d40d4bf077de03f0bc00a.png)
将将切过的图重新标号,第一次向右shift A的宽度,再往下shift
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BUlMxpCO-1678526687224)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310220534098.png)]](https://img-blog.csdnimg.cn/2f60587800c34c02ba75e7cb3ae42bf5.png)
从下到上 E FD HB IGAC,对于每个window都是M×M大小的,对于每个窗口,进行 Q 和 K的计算得到![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8A1PWUsc-1678526687224)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230310220853008.png)]](https://img-blog.csdnimg.cn/a969ca600cf6400db779fc5fdc209e2b.png)
如果只算E的,和之前的一样,如果算F D,对于左半边F,不需要管右边D的内容,需要将它遮住,如果计算右边,也同样不需要看到左侧,将其遮住或者置为0。
所以我们需要找个 mask,把不需要的地方遮挡住,对于shift window的四方格,需要对每个window中找到对应的mask。
此时我们不需要管颜色,只需要管红框,第一个不需要设置Mask
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-88Pjc9hY-1678526687224)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311085853599.png)]](https://img-blog.csdnimg.cn/da19865be60a4c49bc0cba55d2fe216d.png)
对于每个token需要展开,这样设置mask就可以计算单个红框内的值,只把红色和红色,红色和黄色的结果保留,而红色和蓝色结果就舍去了,这样设计mask左部分F的self-attention就可计算出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N0CEKZgV-1678526687224)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311085951862.png)]](https://img-blog.csdnimg.cn/8aabd7d57d3c4d28bdf6df213f65292c.png)
同理,右侧mask这样设计
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4uchPI6S-1678526687224)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090214274.png)]](https://img-blog.csdnimg.cn/3da6ce27277a493989742dfb8c595e13.png)
所以这一部分的mask需要这样设计
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sLkovcQM-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090637323.png)]](https://img-blog.csdnimg.cn/02d47207c67f483986f4b7ab6dfb7fc2.png)
同理对于接下来的M×M窗口如何设计呢? 上方同样只关注绿 黄
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ohb5zmD7-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090706952.png)]](https://img-blog.csdnimg.cn/04d015b22f9142fe94c08e6fbc141796.png)
下方只关注蓝 红
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LFZWKxLV-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090749535.png)]](https://img-blog.csdnimg.cn/51e5c4d594714d15b89b9cde66563f9b.png)
合并起来,即
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N9V7Xsm4-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090801665.png)]](https://img-blog.csdnimg.cn/018f5d9dd95342f0a84ad6d78e4362d4.png)
最后一部分每个颜色为一个小窗口,自己算自己的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yIjktwSX-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090830239.png)]](https://img-blog.csdnimg.cn/5aa848bc75954bc381a4e68277f86b8f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Plef828r-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090839814.png)]](https://img-blog.csdnimg.cn/3348ca216f3e4b3f89671945a88255ba.png)
四个放到一起为
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WmRZbpDp-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090912747.png)]](https://img-blog.csdnimg.cn/fb84dcc3e92e47e38a9b3cec1783d686.png)
这样设计完后,我们怎么进行mask呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wqY2Cy3v-1678526687225)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311090924464.png)]](https://img-blog.csdnimg.cn/2bd539b463df4a56a3a965956a1f1359.png)
需要的部分是0,不需要的地方选了-100,因为softmax中x越小,得到的值越接近于0,越不影响attention
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N6l5BCXr-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311092008055.png)]](https://img-blog.csdnimg.cn/d9620b42c9714da4b43b2cd750c39111.png)
因为我们之前为了高效计算,进行了cycic shift,但是如果我们要最后计算的时候,要恢复原来的shape,需要反向cycic shift
二、Relative Position Bias
有一个tensor,尺寸是3×3,其中有9个vision tokens,将其拉平,然后得到Q×K’后 9×9的attention Weight的矩阵,这时我们需要加一个B
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nwxyg4f0-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311092805300.png)]](https://img-blog.csdnimg.cn/44ffa9605a09449da00fa0f385ba309f.png)
那这个B干什么的呢,它是一个偏置,可学习的bias,加一个相对位置的bias,希望把相对位置信息给attention weight的信息加进去。
更详细的说,如果有9个token,那它有几个相对位置呢?
我们只看同一行用相同颜色的表示,竖直方向位置变化就是不变、+1、+2、-1、-2,那同一行位置变化就是0,那么黄色比蓝色位置多1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sEDlU5O9-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311093128043.png)]](https://img-blog.csdnimg.cn/26f3b2331ebf4a86854fddb17f766e94.png)
对于横向来看,位置偏置如图,![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-er1awOAy-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311093453946.png)]](https://img-blog.csdnimg.cn/c01153cdab404658a2e5986bec08a1c7.png)
那我们合起来会怎么样呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-otmlwHsv-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311093616712.png)]](https://img-blog.csdnimg.cn/11a0015a1f3e4044b778aeda94044c3c.png)
这个就是针对于横向和纵向的偏置,它一共有25种相对位置,我们可以用更少的数量表示,用索引标记
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kPSFSQz8-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311095744346.png)]](https://img-blog.csdnimg.cn/173605a9e1f143de80ed2d28e1a88d69.png)
我们有这样一个可学习的Table,最后得到相对位置的索引之后,我们查询Table将其填入 Relative Position Bias中,与Attention weight相加。
这里需要注意的是尺寸的一个问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OM7P6Zev-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311100635948.png)]](https://img-blog.csdnimg.cn/d49ad62380b645a3aa065dd93a5581b2.png)
假如我们的window为 M×M,那我们Q×K’ 为 M²×M²,我们的Relative Position Bias Table为(2M-1)×(2M-1)。
实现的话,我们可学习的Relative Position Bias Table,创建一个parameter,shape为2倍的(window_size-1)× 2倍的(window_size-1),那我们的头可以是单独的也可以是公用的,Swin中给每个头单独来做。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dJQUxNXf-1678526687226)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311102041871.png)]](https://img-blog.csdnimg.cn/0045903b6ad7480a8ff0cb018a2c2876.png)
设置完后还需要去注册一下,将值注册到层里面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xXmajwR8-1678526687227)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311102032888.png)]](https://img-blog.csdnimg.cn/7c84fd4d1c9044f6a4f30583f7f1bd87.png)
三、实践部分:主要是实现Shift-Window-Multihead-Self-Attention
1. img_mask部分
假设我们shift已经做完了,我们现在有十字格,在算mask之前,要算image mask,建立mask.py文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CfF41C5O-1678526687227)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311102750034.png)]](https://img-blog.csdnimg.cn/7b6292fcc5f143d4bdac4866816bc1bb.png)
有了image mask之后,我们会将它切分然后展开,看下方,针对于第四行,我们最后4578这部分,我们的目标就是这个,最终就能生成左下角的Attention Mask
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wWbK5FMV-1678526687227)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311102821820.png)]](https://img-blog.csdnimg.cn/009a96f053cf49a6894f3ab2b9654f6c.png)
首先就是生成 img_mask的代码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xxi26das-1678526687227)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311104503057.png)]](https://img-blog.csdnimg.cn/0d9cd93dc6434cf2826edbdc2ffec7b7.png)
我们使用 window_size大小,然后slice进行划分,第一个h 从(0, -window_size),w从(0, -window_size),就把第一个window切出来,进而切下一个,w变为(-window_size,-shift_size),就把1 切出来了,经过这样操作之后,就把图中彩色部分变为黑白部分。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PHtQMq4k-1678526687227)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311104621420.png)]](https://img-blog.csdnimg.cn/4699a4b3e2464323b0d8e8909c902a52.png)
接下来就要做window_partition,按照十字刀来切,要对每一个四方格块来算,而每个块中的不统一,我们要经过mask来得到自己想要的部分,但第一步还是进行切分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4jM9PD5r-1678526687227)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311105056427.png)]](https://img-blog.csdnimg.cn/858092ed274941109b1b81c6f68fc7c6.png)
切分后,给他把每一个window 拉平,把[1,H,W,1]的最后一维去掉,然后把H和W拉平
attn_mask = windows_mask.unsqueeze(1) - windows_mask.unsqueeze(2)
# [n,1, ws*ws] - [n, ws*ws, 1]
此时我们进行相减,在做什么呢?在Numpy中如果有一个4行一列的向量和一行三列的向量做加法,最终得到的是四行三列的矩阵,他会对于维度进行扩充,这就叫broadcasting
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DQFzFr3e-1678526687228)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311105834339.png)]](https://img-blog.csdnimg.cn/86d1764b6d4d4a26ac3e5ac039af8fb7.png)
那我们相减操作在干什么呢?我们将展开的4578,扩充为列向量和行向量之后,进行相减,得到的是0的部分,我们可以将不是0的部分设置为255,图中是蓝色区域这就是我们要的atten_mask,将其返回即可
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GmTgL0io-1678526687228)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311110054751.png)]](https://img-blog.csdnimg.cn/88abd3bce90d4f389ae265b3d612066a.png)
代码如下
# TODO: generate attn mask
def generate_mask(window_size=4, shift_size=2, input_resolution=(8,8)):
H,W = input_resolution
img_mask = torch.zeros([1, H, W, 1])
h_slices = [slice(0, -window_size), #a[slice(..)] = a[0: -window_size]
slice(-window_size,-shift_size),
slice(-shift_size,None)]
w_slices = [slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None)]
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w,:] = cnt
cnt += 1
windows_mask = windows_partition(img_mask, window_size= window_size)
# 考虑尺寸需要reshape,拉平
windows_mask = windows_mask.reshape([-1, window_size*windows_mask])
attn_mask = windows_mask.unsqueeze(1) - windows_mask.unsqueeze(2) # [n,1, ws*ws] - [n, ws*ws, 1]
attn_mask = torch.where(attn_mask!=0,
torch.ones_like(attn_mask)*255,
torch.zeros_like(attn_mask)) #如果是0,不管,不是0,设置为255
return attn_mask
在main函数里调用,来输出展示
def main():
# TODO: main
mask = generate_mask()
print(mask.shape)
mask = mask.cpu().numpy().astype('uint8')
for i in range(4): #4个子window
for j in range(16): # 16*16的尺寸
for k in range(16):
print(mask[i,j,k], end='\t')
print()
im = Image.fromarray(mask[i, :, :])
im.save(f'{
i}.png')
print()
print()
print()
2. 实现shift window self window
从上一节课的main 出发,新建一个Swin_Transformer_add_shift,加入swin_block_sw_msa,对于SwinBlock进行一个修改,它做的其实就是图中的流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LlbDv4DE-1678526687228)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311113726626.png)]](https://img-blog.csdnimg.cn/68b2a3d4128f4634857b74d6eac1a25c.png)
这里做了两次变换,第一次是 循环移位,第二次是循环移位后,切window,展开token做注意力,做完之后将其reverse,再将窗口复原回去。
SwinBlock中 forward代码如下
class SwinBlock(nn.Module):
def forward(self,x):
H, W = self.reolution
B, N, C =x.shape
h = x
s = self.attn_norm(x)
#切 window
x = x.reshape([B, H, W, C])
##### Begin
# TODO: shift window
if self.shift_size > 0:
# 先向右再往下挪
shifted_x = torch.roll(x, shifts=(-self.shift_size,-self.shift_size), axis=(1,2))
else:
shifted_x = x
# TODO: compute window attn
# 切方块
x_windows = windows_partition(shifted_x, self.window_size)
# 将其展开序列
x_windows = x_windows.reshape([-1, self.window_size*self.window_size,C])
attn_windows = self.attn(x_windows, mask=self.attn_mask)
attn_windows = attn_windows.reshape([-1, self.window_size, self.window_size,C])
shifted_x = windows_reverse(attn_windows, self.window_size)
# TODO: shift back
if self.shift_size > 0:
# 先向右再往下挪
x = torch.roll(shifted_x, shifts=(self.shift_size,self.shift_size), axis=(1,2))
else:
x = shifted_x
##### End
x_windows = windows_partition(x, self.window_size)
# [B * num_patches, ws, ws, c]
x_windows = x_windows.reshape([-1,self.window_size*self.window_size, C])
attn_windows = self.attn(x_windows)
# 做完attention 将它复原
attn_windows = attn_windows.reshape([-1, self.window_size, self.window_size, C])
x = windows_reverse(attn_windows, self.window_size, H, W)
# [B, H ,W ,C]
# 但是做mlp中 输入不是它
x = x.reshape([B, H*W, C])
x = h + x
h = x
x = self.mlp_norm(x)
x = self.mlp(x)
x = h + x
return x
这里我们调用了attn_mask,所以在 init中初始化,代码如下:
def __init__(self, dim, input_reslution, num_heads, window_size,shift_size):
super().__init__()
self.dim = dim
self.reolution = input_reslution
self.window_size =window_size
self.shift_size = shift_size
self.attn_norm = nn.LayerNorm(dim)
self.attn = WindowAttention(dim, window_size,num_heads)
self.mlp_norm = nn.LayerNorm(dim)
self.mlp = Mlp(dim)
# TODO: generate mask and register buffer
if self.shift_size > 0:
attn_mask = generate_mask(self.window_size, self.shift_size, self.reolution)
else:
attn_mask = None
self.register_buffer('attn_mask', attn_mask)
最后一部分,我们在WindowAttention内,我们将mask传入了,要将mask加进去,来做attention
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YKr7dSrE-1678526687228)(C:\Users\qiaoqiang\AppData\Roaming\Typora\typora-user-images\image-20230311160326285.png)]](https://img-blog.csdnimg.cn/ceabbed441fe4e2abf263e724bf31f4a.png)
我们要将Mask加到原图中,来算attn,其中最重要的就是attn与mask维度不一致,需要进行变换reshape,unsqueeze等等
class WindowAttention(nn.Module):
def forward(self,x,mask=None):
# x: [B, num_patches, embed_dim]
B, N, C = x.shape
print('xshape=', x.shape)
qkv = self.qkv(x).chunk(3, -1)
q, k, v = map(self.tranpose_multi_head, qkv)
q = q * self.scale
attn = torch.matmul(q, k.transpose(-1,-2))
# [B * num_windows, num_heads, num_patches, num_patches]
print('attn shape=',attn.shape)
##### Begin: Mask
# TODO: reshape and add mask if mask is not none
if mask is None:
attn = self.softmax(attn)
else:
# mask : [num_windows, num_patches, num_patches]
# attn: [B * num_windows, num_heads, num_patches, num_patches]
attn = attn.reshape([B//mask.shape[0],mask.shape[0],self.num_heads, mask.shape[1], mask.shape[1]])
# attn: [B, num_windows, num_heads, num_patches, num_patches]
# mask : [ num_windows, 1, num_patches, num_patches]
attn = attn+ mask.unsqueeze(1).unsqueeze(0)
# mask : [1, num_windows, 1, num_patches, num_patches]
attn = attn.reshape([-1,self.num_heads,mask.shape[1],mask.shape[1]])
# attn: [B * num_windows, num_heads, num_patches, num_patches]
##### End: Mask
out = torch.matmul(attn, v) # [B, num_heads, num_patches, dim_head]
out = out.permute([0, 2, 1, 3])
# # [B, num_patches, num_heads, dim_head] num_heads * dim_head= embed_dim
out = out.reshape([B, N, C])
out = self.proj(out)
return out
运行结果如下:
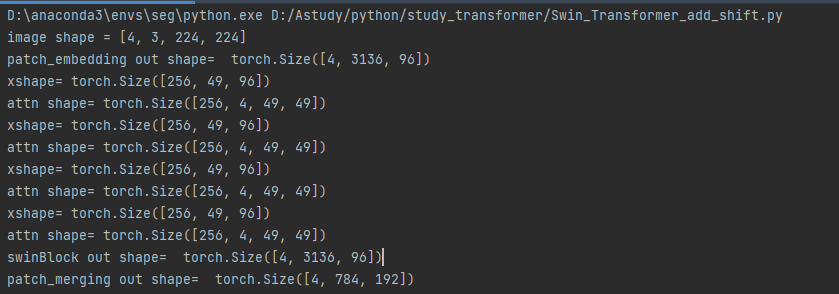
完整代码之后会加入资源中,目前没有实现 Relative Position Bias,其他全部实现了!