Embedding层
根据ViT的模型结构,第一步需要将图片划分为多个Patches,并且将其铺平。如下图所示。
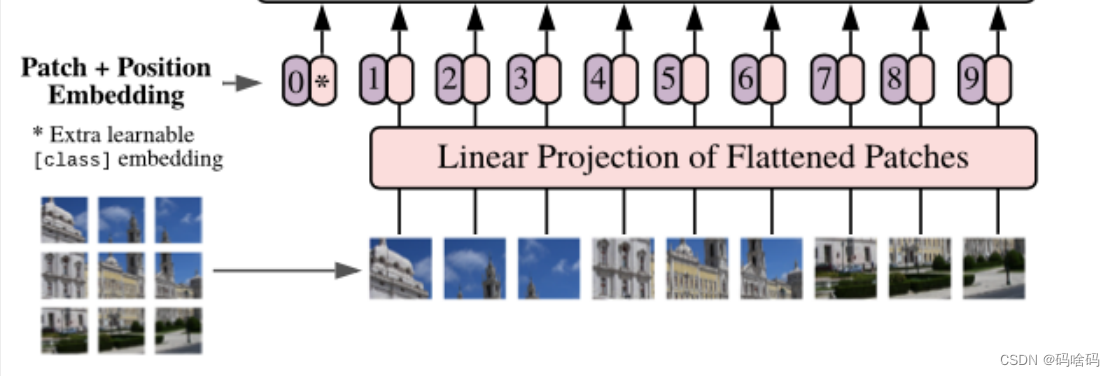
实际查看原作者的代码,他并没有使用线性映射层来做这件事,出于效率考虑,作者使用了Conv2d层来实现相同的功能。这是通过设置卷积核大小和步长均为patch_size来实现的。直观上来看,卷积操作是分别应用在每个patch上的。所以,我们可以先应用一个卷积层,然后再对结果进行铺平。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
'''
按文章的意思线性映射得到patch
将原始图像切分为16*16的patch并把它们拉平
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),
注意这里的隐层大小设置的也是768,可以配置
nn.Linear(patch_size * patch_size * in_channels, emb_size)线性层
'''
# 改进:使用一个卷积层而不是一个线性层 -> 性能增加
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
# 将分好的patch铺平
Rearrange('b e (h) (w) -> b (h w) e'),
)
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# 将cls token在维度1扩展到输入上
x = torch.cat([cls_tokens, x], dim=1)
# 添加位置编码
print(x.shape, self.positions.shape)
x += self.positions
return x
PatchEmbedding()(x).shape
#得到的输出
torch.Size([1, 197, 768])
加入CLS TOKEN
下一步是对映射后的patches添加上cls token以及position Embedding位置编码信息。cls token是一个随机初始化的torch Parameter对象,在forward方法中它需要被拷贝b次(b是batch的数量),然后使用torch.cat函数添加到patch前面。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
'''
按文章的意思线性映射得到patch
将原始图像切分为16*16的patch并把它们拉平
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),
注意这里的隐层大小设置的也是768,可以配置
nn.Linear(patch_size * patch_size * in_channels, emb_size)
'''
# 改进:使用一个卷积层而不是一个线性层 -> 性能增加
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
# 将分好的patch铺平
Rearrange('b e (h) (w) -> b (h w) e'),
)
# 生成一个维度为emb_size的向量当做cls_token
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# 将cls token在维度1扩展到输入上
x = torch.cat([cls_tokens, x], dim=1)
# 添加位置编码
print(x.shape, self.positions.shape)
x += self.positions
return x
PatchEmbedding()(x).shape
position Embedding
加入位置编码信息
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
'''
按文章的意思线性映射得到patch
将原始图像切分为16*16的patch并把它们拉平
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),
注意这里的隐层大小设置的也是768,可以配置
nn.Linear(patch_size * patch_size * in_channels, emb_size)
'''
# 改进:使用一个卷积层而不是一个线性层 -> 性能增加
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
# 将分好的patch铺平
Rearrange('b e (h) (w) -> b (h w) e'),
)
# 生成一个维度为emb_size的向量当做cls_token
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
# 位置编码信息,一共有(img_size // patch_size)**2 + 1(cls token)个位置向量
self.positions = nn.Parameter(torch.randn((img_size // patch_size)**2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# 将cls token在维度1扩展到输入上
x = torch.cat([cls_tokens, x], dim=1)
# 添加位置编码
print(x.shape, self.positions.shape)
x += self.positions
return x
PatchEmbedding()(x).shape
Transformer Encoder
attention部分有三个输入,分别是queries,keys,values矩阵,首先使用queries,keys矩阵去计算注意力矩阵,经softmax后与values矩阵相乘,得到对应的输出。在下图中,multi-head注意力机制表示将输入划分成n份,然后将计算分到n个head上去。
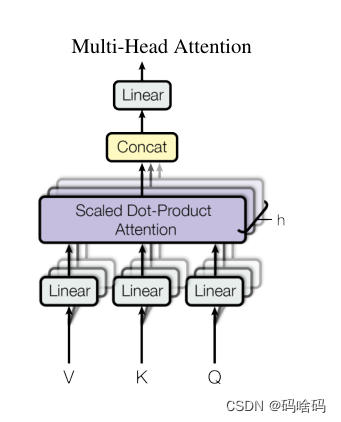
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads)
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
残差网络连接
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
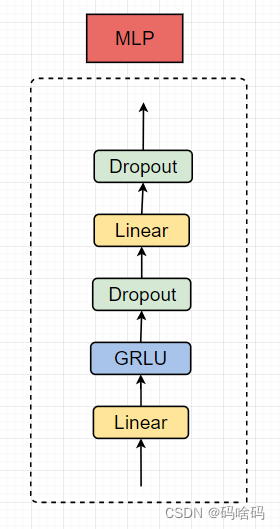
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
nn.Dropout(drop_p)
)
得到完整的Transformer Block
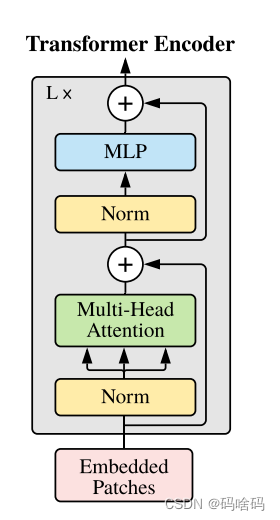
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
在ViT中只使用了原始Transformer中的Encoder部分(其实和原始Transformer中的Encoder是有区别的)。Encoder一共包含L个block,我们使用参数depth来指定,代码如下
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
MLP Head
ViT的最后一层就是一个简单的全连接层,输出分类的概率值。它对整个序列执行一个mean操作。
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
ViT
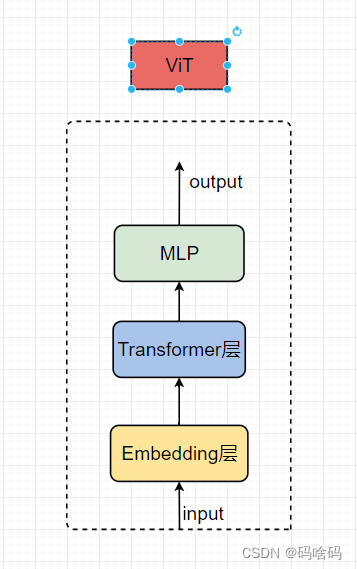
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
计算参数量
使用torchsummary函数来计算参数量,输出如下:
model = ViT()
summary(model, input_size=[(3, 224, 224)], batch_size=1, device="cpu")
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
PatchEmbedding-3 [-1, 197, 768] 0
LayerNorm-4 [-1, 197, 768] 1,536
Linear-5 [-1, 197, 768] 590,592
Linear-6 [-1, 197, 768] 590,592
Linear-7 [-1, 197, 768] 590,592
Dropout-8 [-1, 8, 197, 197] 0
Linear-9 [-1, 197, 768] 590,592
MultiHeadAttention-10 [-1, 197, 768] 0
Dropout-11 [-1, 197, 768] 0
ResidualAdd-12 [-1, 197, 768] 0
LayerNorm-13 [-1, 197, 768] 1,536
Linear-14 [-1, 197, 3072] 2,362,368
GELU-15 [-1, 197, 3072] 0
Dropout-16 [-1, 197, 3072] 0
Linear-17 [-1, 197, 768] 2,360,064
Dropout-18 [-1, 197, 768] 0
Dropout-19 [-1, 197, 768] 0
ResidualAdd-20 [-1, 197, 768] 0
LayerNorm-21 [-1, 197, 768] 1,536
Linear-22 [-1, 197, 768] 590,592
Linear-23 [-1, 197, 768] 590,592
Linear-24 [-1, 197, 768] 590,592
Dropout-25 [-1, 8, 197, 197] 0
Linear-26 [-1, 197, 768] 590,592
MultiHeadAttention-27 [-1, 197, 768] 0
Dropout-28 [-1, 197, 768] 0
ResidualAdd-29 [-1, 197, 768] 0
LayerNorm-30 [-1, 197, 768] 1,536
Linear-31 [-1, 197, 3072] 2,362,368
GELU-32 [-1, 197, 3072] 0
Dropout-33 [-1, 197, 3072] 0
Linear-34 [-1, 197, 768] 2,360,064
Dropout-35 [-1, 197, 768] 0
Dropout-36 [-1, 197, 768] 0
ResidualAdd-37 [-1, 197, 768] 0
LayerNorm-38 [-1, 197, 768] 1,536
Linear-39 [-1, 197, 768] 590,592
Linear-40 [-1, 197, 768] 590,592
Linear-41 [-1, 197, 768] 590,592
Dropout-42 [-1, 8, 197, 197] 0
Linear-43 [-1, 197, 768] 590,592
MultiHeadAttention-44 [-1, 197, 768] 0
Dropout-45 [-1, 197, 768] 0
ResidualAdd-46 [-1, 197, 768] 0
LayerNorm-47 [-1, 197, 768] 1,536
Linear-48 [-1, 197, 3072] 2,362,368
GELU-49 [-1, 197, 3072] 0
Dropout-50 [-1, 197, 3072] 0
Linear-51 [-1, 197, 768] 2,360,064
Dropout-52 [-1, 197, 768] 0
Dropout-53 [-1, 197, 768] 0
ResidualAdd-54 [-1, 197, 768] 0
LayerNorm-55 [-1, 197, 768] 1,536
Linear-56 [-1, 197, 768] 590,592
Linear-57 [-1, 197, 768] 590,592
Linear-58 [-1, 197, 768] 590,592
Dropout-59 [-1, 8, 197, 197] 0
Linear-60 [-1, 197, 768] 590,592
MultiHeadAttention-61 [-1, 197, 768] 0
Dropout-62 [-1, 197, 768] 0
ResidualAdd-63 [-1, 197, 768] 0
LayerNorm-64 [-1, 197, 768] 1,536
Linear-65 [-1, 197, 3072] 2,362,368
GELU-66 [-1, 197, 3072] 0
Dropout-67 [-1, 197, 3072] 0
Linear-68 [-1, 197, 768] 2,360,064
Dropout-69 [-1, 197, 768] 0
Dropout-70 [-1, 197, 768] 0
ResidualAdd-71 [-1, 197, 768] 0
LayerNorm-72 [-1, 197, 768] 1,536
Linear-73 [-1, 197, 768] 590,592
Linear-74 [-1, 197, 768] 590,592
Linear-75 [-1, 197, 768] 590,592
Dropout-76 [-1, 8, 197, 197] 0
Linear-77 [-1, 197, 768] 590,592
MultiHeadAttention-78 [-1, 197, 768] 0
Dropout-79 [-1, 197, 768] 0
ResidualAdd-80 [-1, 197, 768] 0
LayerNorm-81 [-1, 197, 768] 1,536
Linear-82 [-1, 197, 3072] 2,362,368
GELU-83 [-1, 197, 3072] 0
Dropout-84 [-1, 197, 3072] 0
Linear-85 [-1, 197, 768] 2,360,064
Dropout-86 [-1, 197, 768] 0
Dropout-87 [-1, 197, 768] 0
ResidualAdd-88 [-1, 197, 768] 0
LayerNorm-89 [-1, 197, 768] 1,536
Linear-90 [-1, 197, 768] 590,592
Linear-91 [-1, 197, 768] 590,592
Linear-92 [-1, 197, 768] 590,592
Dropout-93 [-1, 8, 197, 197] 0
Linear-94 [-1, 197, 768] 590,592
MultiHeadAttention-95 [-1, 197, 768] 0
Dropout-96 [-1, 197, 768] 0
ResidualAdd-97 [-1, 197, 768] 0
LayerNorm-98 [-1, 197, 768] 1,536
Linear-99 [-1, 197, 3072] 2,362,368
GELU-100 [-1, 197, 3072] 0
Dropout-101 [-1, 197, 3072] 0
Linear-102 [-1, 197, 768] 2,360,064
Dropout-103 [-1, 197, 768] 0
Dropout-104 [-1, 197, 768] 0
ResidualAdd-105 [-1, 197, 768] 0
LayerNorm-106 [-1, 197, 768] 1,536
Linear-107 [-1, 197, 768] 590,592
Linear-108 [-1, 197, 768] 590,592
Linear-109 [-1, 197, 768] 590,592
Dropout-110 [-1, 8, 197, 197] 0
Linear-111 [-1, 197, 768] 590,592
MultiHeadAttention-112 [-1, 197, 768] 0
Dropout-113 [-1, 197, 768] 0
ResidualAdd-114 [-1, 197, 768] 0
LayerNorm-115 [-1, 197, 768] 1,536
Linear-116 [-1, 197, 3072] 2,362,368
GELU-117 [-1, 197, 3072] 0
Dropout-118 [-1, 197, 3072] 0
Linear-119 [-1, 197, 768] 2,360,064
Dropout-120 [-1, 197, 768] 0
Dropout-121 [-1, 197, 768] 0
ResidualAdd-122 [-1, 197, 768] 0
LayerNorm-123 [-1, 197, 768] 1,536
Linear-124 [-1, 197, 768] 590,592
Linear-125 [-1, 197, 768] 590,592
Linear-126 [-1, 197, 768] 590,592
Dropout-127 [-1, 8, 197, 197] 0
Linear-128 [-1, 197, 768] 590,592
MultiHeadAttention-129 [-1, 197, 768] 0
Dropout-130 [-1, 197, 768] 0
ResidualAdd-131 [-1, 197, 768] 0
LayerNorm-132 [-1, 197, 768] 1,536
Linear-133 [-1, 197, 3072] 2,362,368
GELU-134 [-1, 197, 3072] 0
Dropout-135 [-1, 197, 3072] 0
Linear-136 [-1, 197, 768] 2,360,064
Dropout-137 [-1, 197, 768] 0
Dropout-138 [-1, 197, 768] 0
ResidualAdd-139 [-1, 197, 768] 0
LayerNorm-140 [-1, 197, 768] 1,536
Linear-141 [-1, 197, 768] 590,592
Linear-142 [-1, 197, 768] 590,592
Linear-143 [-1, 197, 768] 590,592
Dropout-144 [-1, 8, 197, 197] 0
Linear-145 [-1, 197, 768] 590,592
MultiHeadAttention-146 [-1, 197, 768] 0
Dropout-147 [-1, 197, 768] 0
ResidualAdd-148 [-1, 197, 768] 0
LayerNorm-149 [-1, 197, 768] 1,536
Linear-150 [-1, 197, 3072] 2,362,368
GELU-151 [-1, 197, 3072] 0
Dropout-152 [-1, 197, 3072] 0
Linear-153 [-1, 197, 768] 2,360,064
Dropout-154 [-1, 197, 768] 0
Dropout-155 [-1, 197, 768] 0
ResidualAdd-156 [-1, 197, 768] 0
LayerNorm-157 [-1, 197, 768] 1,536
Linear-158 [-1, 197, 768] 590,592
Linear-159 [-1, 197, 768] 590,592
Linear-160 [-1, 197, 768] 590,592
Dropout-161 [-1, 8, 197, 197] 0
Linear-162 [-1, 197, 768] 590,592
MultiHeadAttention-163 [-1, 197, 768] 0
Dropout-164 [-1, 197, 768] 0
ResidualAdd-165 [-1, 197, 768] 0
LayerNorm-166 [-1, 197, 768] 1,536
Linear-167 [-1, 197, 3072] 2,362,368
GELU-168 [-1, 197, 3072] 0
Dropout-169 [-1, 197, 3072] 0
Linear-170 [-1, 197, 768] 2,360,064
Dropout-171 [-1, 197, 768] 0
Dropout-172 [-1, 197, 768] 0
ResidualAdd-173 [-1, 197, 768] 0
LayerNorm-174 [-1, 197, 768] 1,536
Linear-175 [-1, 197, 768] 590,592
Linear-176 [-1, 197, 768] 590,592
Linear-177 [-1, 197, 768] 590,592
Dropout-178 [-1, 8, 197, 197] 0
Linear-179 [-1, 197, 768] 590,592
MultiHeadAttention-180 [-1, 197, 768] 0
Dropout-181 [-1, 197, 768] 0
ResidualAdd-182 [-1, 197, 768] 0
LayerNorm-183 [-1, 197, 768] 1,536
Linear-184 [-1, 197, 3072] 2,362,368
GELU-185 [-1, 197, 3072] 0
Dropout-186 [-1, 197, 3072] 0
Linear-187 [-1, 197, 768] 2,360,064
Dropout-188 [-1, 197, 768] 0
Dropout-189 [-1, 197, 768] 0
ResidualAdd-190 [-1, 197, 768] 0
LayerNorm-191 [-1, 197, 768] 1,536
Linear-192 [-1, 197, 768] 590,592
Linear-193 [-1, 197, 768] 590,592
Linear-194 [-1, 197, 768] 590,592
Dropout-195 [-1, 8, 197, 197] 0
Linear-196 [-1, 197, 768] 590,592
MultiHeadAttention-197 [-1, 197, 768] 0
Dropout-198 [-1, 197, 768] 0
ResidualAdd-199 [-1, 197, 768] 0
LayerNorm-200 [-1, 197, 768] 1,536
Linear-201 [-1, 197, 3072] 2,362,368
GELU-202 [-1, 197, 3072] 0
Dropout-203 [-1, 197, 3072] 0
Linear-204 [-1, 197, 768] 2,360,064
Dropout-205 [-1, 197, 768] 0
Dropout-206 [-1, 197, 768] 0
ResidualAdd-207 [-1, 197, 768] 0
Reduce-208 [-1, 768] 0
LayerNorm-209 [-1, 768] 1,536
Linear-210 [-1, 1000] 769,000
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 378.18
Params size (MB): 329.65
Estimated Total Size (MB): 708.41
----------------------------------------------------------------
None