paper: https://arxiv.org/abs/2103.14030
code: https://github.com/microsoft/Swin-Transformer
前言
本文介绍了一种称为Swin Transformer的新型transformer,通过引入CNN中常用的层次化构建方式构建层次化Transformer以及引入locality思想解决transformer迁移至CV上的scale和分辨率的问题。该方法屠榜各大CV任务,代码已公布。
最近Transformer的文章眼花缭乱,但是精度和速度相较于CNN而言还是差点意思,直到Swin Transformer的出现,让人感觉到了一丝丝激动,Swin Transformer可能是CNN的完美替代方案。
作者分析表明,Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:1. 两个领域涉及的scale不同,NLP的scale是标准固定的,而CV的scale变化范围非常大。2. CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。
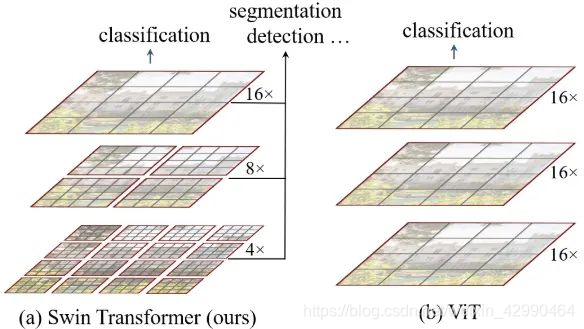
相比于ViT,Swin Transfomer计算复杂度大幅度降低,具有输入图像大小线性计算复杂度。Swin Transformer随着深度加深,逐渐合并图像块来构建层次化Transformer,可以作为通用的视觉骨干网络,应用于图像分类、目标检测和语义分割等任务。
Swin Transformer
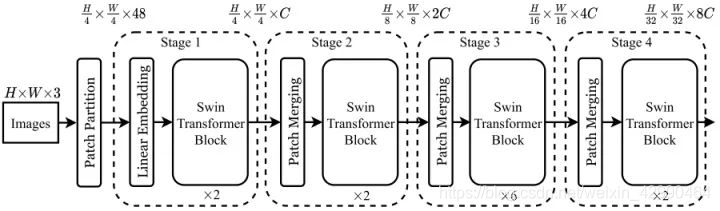
整个Swin Transformer架构,和CNN架构非常相似,构建了4个stage,每个stage中都是类似的重复单元。和ViT类似,通过patch partition将输入图片HxWx3划分为不重合的patch集合,其中每个patch尺寸为4x4,那么每个patch的特征维度为4x4x3=48,patch块的数量为H/4 x W/4;stage1部分,先通过一个linear embedding将输划分后的patch特征维度变成C,然后送入Swin Transformer Block;stage2-stage4操作相同,先通过一个patch merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,这个地方文章写的不清楚,猜测是跟stage1一样使用linear embedding将4C压缩成2C,然后送入Swin Transformer Block。
另外有一个细节,Swin Transformer和ViT划分patch的方式略有不同,ViT是先确定patch的数量,然后计算确定每个patch的尺寸,而Swin Transformer是先确定每个patch的大小,然后计算确定patch数量。这个设计猜测是为了方便Swin Transformer的层级构建。
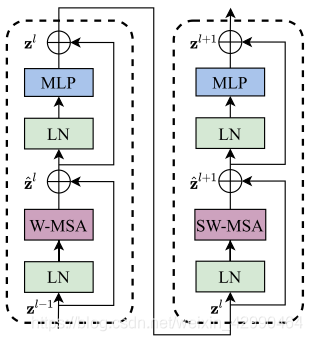
上图是两个连续的Swin Transformer Block。一个Swin Transformer Block由一个带两层MLP的shifted window based MSA组成。在每个MSA模块和每个MLP之前使用LayerNorm(LN)层,并在每个MSA和MLP之后使用残差连接。
Shifted Window based MSA

上图中红色区域是window,灰色区域是patch。W-MSA将输入图片划分成不重合的windows,然后在不同的window内进行self-attention计算。假设一个图片有hxw的patches,每个window包含MxM个patches,那么MSA和W-MSA的计算复杂度分别为:

由于window的patch数量远小于图片patch数量,W-MSA的计算复杂度和图像尺寸呈线性关系。
另外W-MSA虽然降低了计算复杂度,但是不重合的window之间缺乏信息交流,于是作者进一步引入shifted window partition来解决不同window的信息交流问题,在两个连续的Swin Transformer Block中交替使用W-MSA和SW-MSA。以上图为例,将前一层Swin Transformer Block的8x8尺寸feature map划分成2x2个patch,每个patch尺寸为4x4,然后将下一层Swin Transformer Block的window位置进行移动,得到3x3个不重合的patch。移动window的划分方式使上一层相邻的不重合window之间引入连接,大大的增加了感受野。
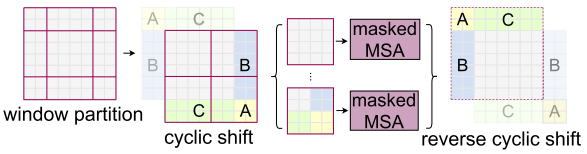
但是shifted window划分方式还引入了另外一个问题,就是会产生更多的windows,并且其中一部分window小于普通的window,比如2x2个patch -> 3x3个patch,windows数量增加了一倍多。于是作者提出了通过沿着左上方向cyclic shift的方式来解决这个问题,移动后,一个batched window由几个特征不相邻的sub-windows组成,因此使用masking mechanism来限制self-attention在sub-window内进行计算。cyclic shift之后,batched window和regular window数量保持一致,极大提高了Swin Transformer的计算效率。这一部分比较抽象复杂,不好理解,等代码开源了再补上。
实验结果
放一些实验结果,感受一下Swin Transformer对之前SOTA的降维打击。
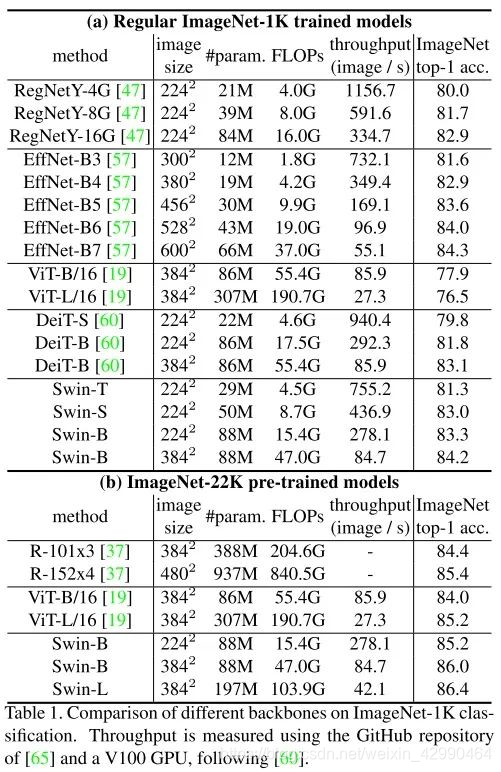
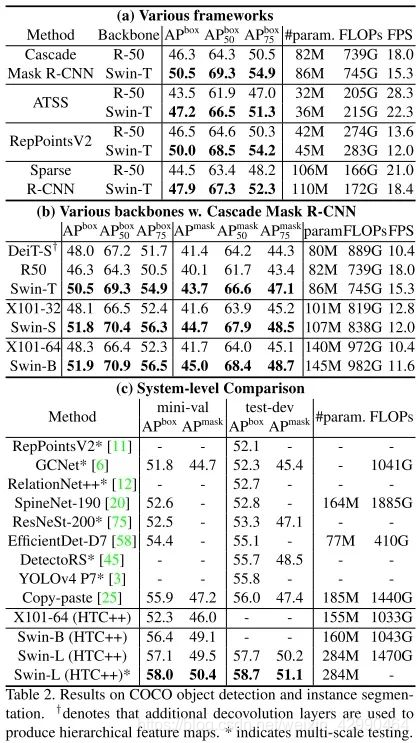
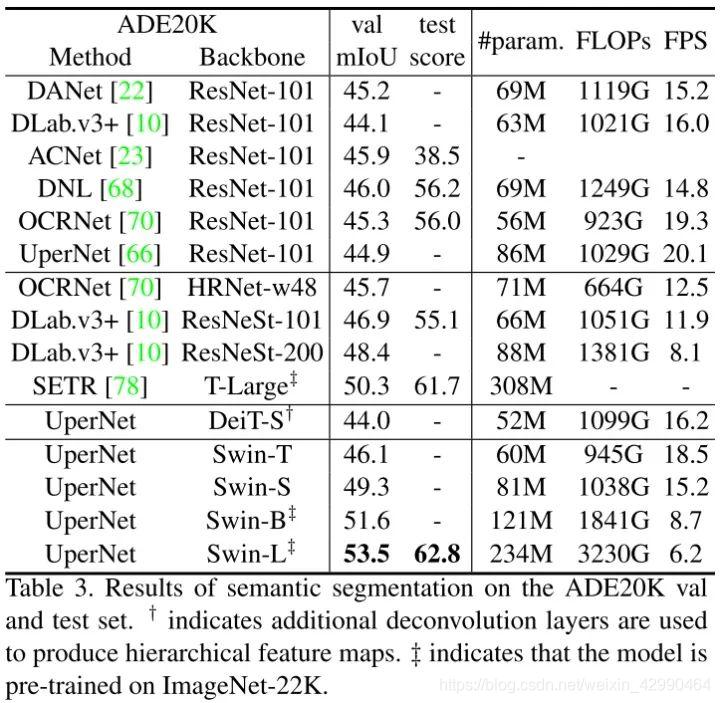
总结
Swin Transformer改进思路还是源于CNN,Transformer站在巨人的肩膀上又迎来了一次巨大的飞跃,未来Transformer会接过CNN手中的接力棒,把locality、translation invariance和hierarchical等思想继续发扬光大。