1. 课程介绍
1.1 ChatGPT 相关术语
LLM:Large Language Model,大语言模型
Instruction Tuned LLM:经过指令微调的大语言模型
Prompt:提示词
RLHF:Reinforcement Learning from Human Feedback,人类反馈强化学习
Completion:补全
Temperature:其范围是0到1,它用于控制模型响应的多样性,可以将其视为模型的探索程度或随机性。
1.2 Instruction Tuned LLM 训练流程
Instruction Tuned LLM 训练流程:已经有在大量语料上进行预训练的模型 Base LLM,然后使用输入和输出格式的指令数据集进行微调,让模型更好的遵循这些指令,然后使用 RLHF 的技术进一步优化,让模型能够更好地遵循指令。最终,模型可以根据提示词生成有用的,诚实的和无害的文本。

在使用 Instruction Tuned LLM 时,可以将其视为给一个聪明但不知道具体任务的人提供指令。因此,当LLM的效果不尽如人意时,有可能是因为提供的指令不够清晰。
2. 编写提示词指南
2.1 OpenAI API 使用
安装 OpenAI 的库
pip install openai
设置密钥
import openai
import os
from dotenv import load_dotenv, find_dotenv
# 读取本地 .env 文件
_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv("OPENAI_API_LEY")
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{
"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(model=model, messages=messages, temperature=0)
return response.choices[0].message["content"]
2.2 原则1:编写明确和具体的指令
这样做的目的是让模型生成更详细和更相关的内容。
1)使用分隔符清楚地知识输入的不同部分
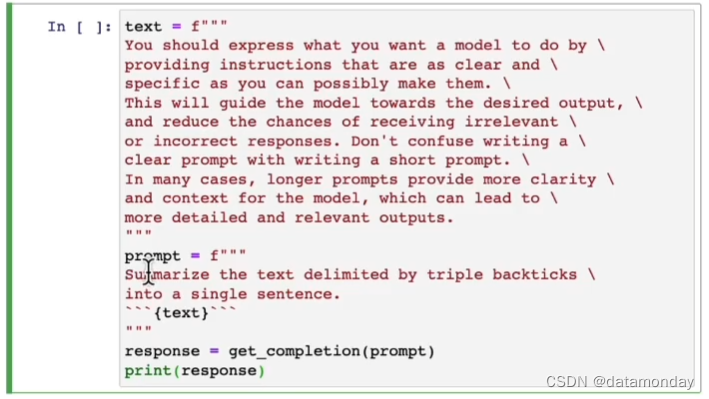
```{text}```指明了让模型需要总结的文本段落。这样做的目的是将提示词的其余部分与该部分文本明确地分隔开,防止无关的内容影响模型的输出结果。下面这些分隔符的作用在当前例子中是等价的。

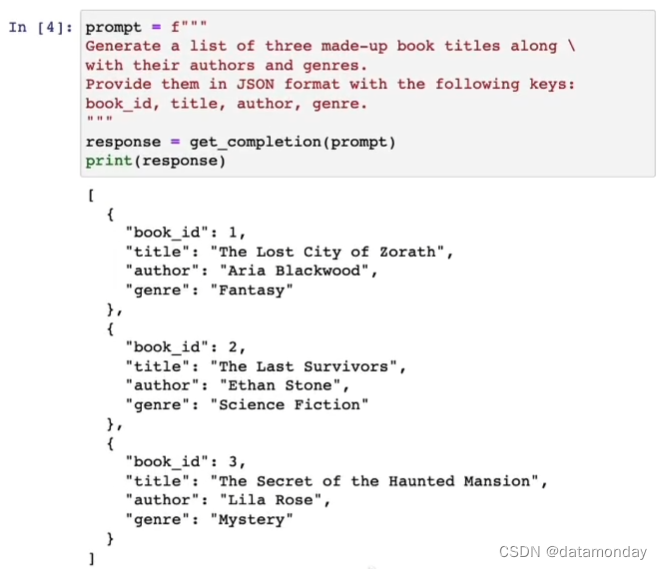
2)要求模型的输出格式化为 JSON/HTML 类型
具体的Prompt:
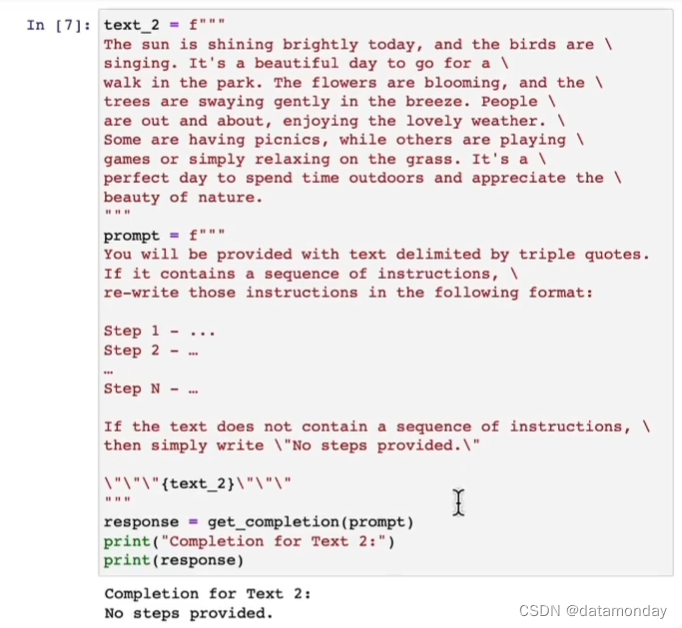
3)要求模型检查是否满足某些条件
要求模型先检查是否满足某些条件,并让模型分别按照不同情况处理。

4)为模型提供少量提示
此举旨在要求模型执行任务之前,在Prompt中提供少量成功执行任务的示例,以让模型学会示例中的风格。

2.3 原则2:给模型思考的时间
如果模型急于给出回复而导致生成的内容出现推理错误,作为调用方,在模型提供最终答案之前,我们应该尝试重新构建查询请求相关推理的链或序列。
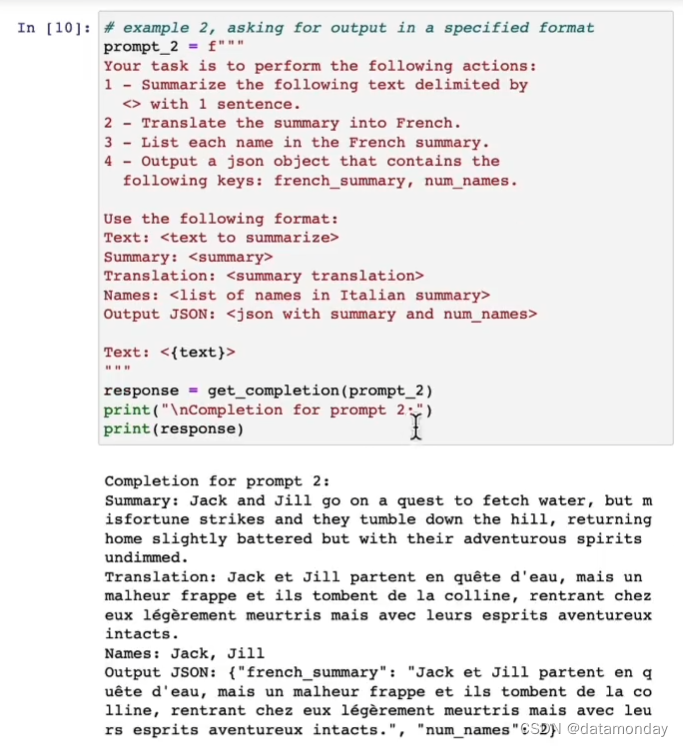
1)指定完成任务所需的步骤

2)要求模型在输出结果之前思考解决方案
如果在提示词中,人为规定了处理逻辑,那么默认情况下ChatGPT只会按照提示词中的逻辑处理,如果出错则报错,不会再自行计算。如果想为了规避人为指定处理逻辑出错的问题,可以添加提示词,让ChatGPT在按照人为指定计算逻辑计算出错时,返回ChatGPT按照自己的逻辑的计算结果。
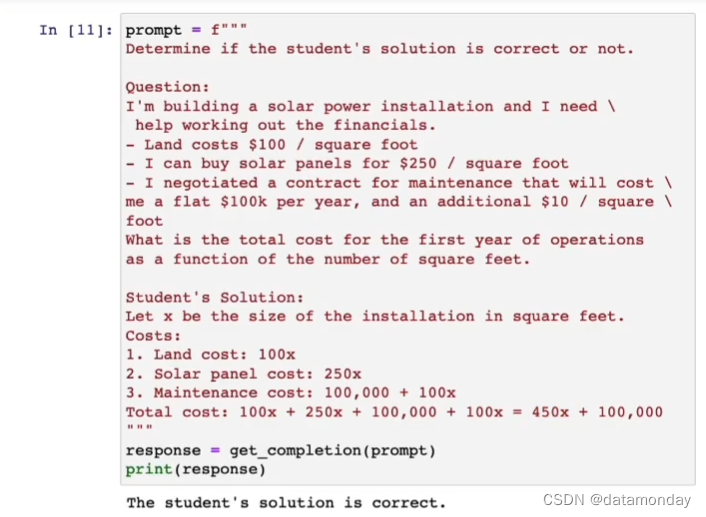
修正之后的提示词:让模型按照规定的步骤(子任务)去执行。

上面的提示词说明了:让模型给出自己的解决方案,然后将其与提示词中的方案对比,并评估提示词中的方案是否正确。
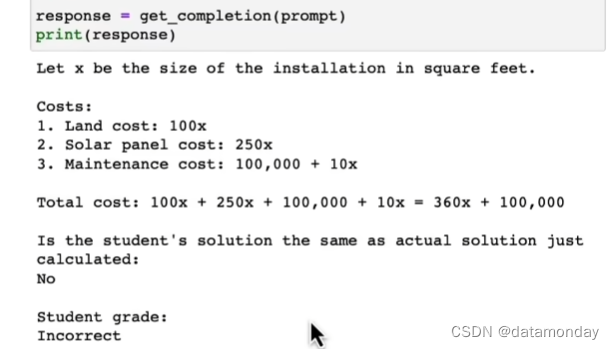
2.4 模型的局限性
1)模型的幻觉
即使使用了大量的知识来训练模型,但它并没有完全记住这些信息。因此,它并不是非常了解其知识的边界,这导致的后果是当模型在尝试回答一些晦涩难懂的问题时,他可能会编造听起来合理但是不正确的内容。这称之为幻觉(Hallucination)。
一个关于牙刷的例子:模型输出了一个不存在的产品的描述。

2)应对策略
减少这种幻觉的策略是:要求模型首先从文本中找到任何相关的引用,然后要求它使用这些引用来回答问题。加上生成这些答案的引用也有助于减少幻觉。
3. 迭代演进提示词
以让模型总结一张椅子说明书为例
第一个prompt

上述提示模型生成的结果太长,不适合放到购物网站的介绍里。所以下一步的优化提示的思路是让模型编写简短的介绍。

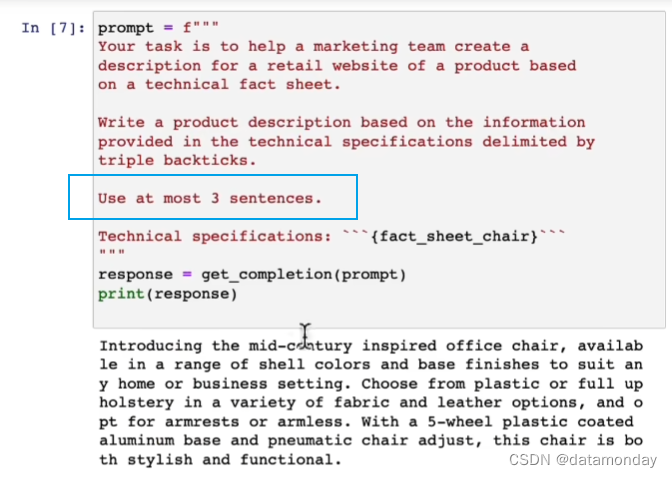
更进一步,要求模型生成最多三句话的描述。
如果仔细阅读总结可以发现,其面向的对象更可能是面向消费者的,如果要是面向椅子的经销商,他们可能更关注技术细节和材料。所以更进一步,可以要求模型生成更精确地描述技术细节的总结。
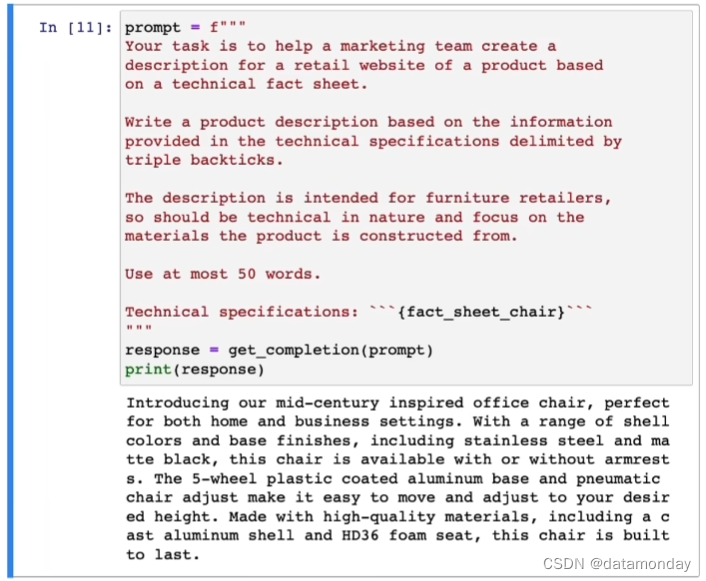
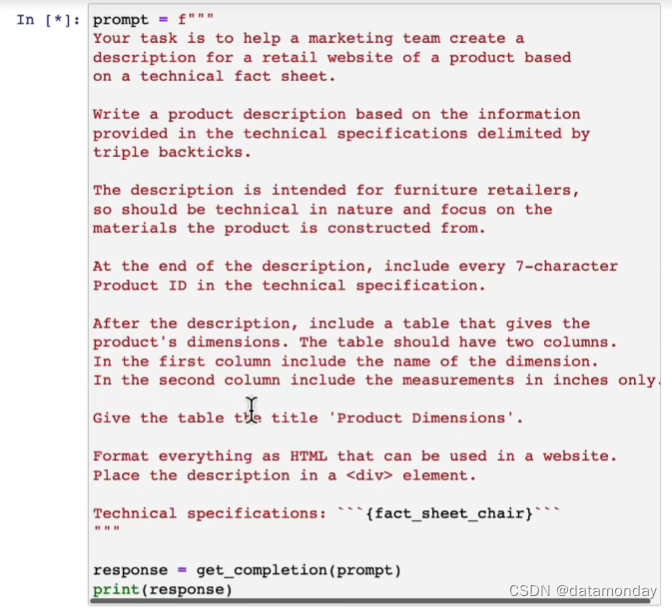
更进一步,让模型生成的结果中包含说明书中的产品型号


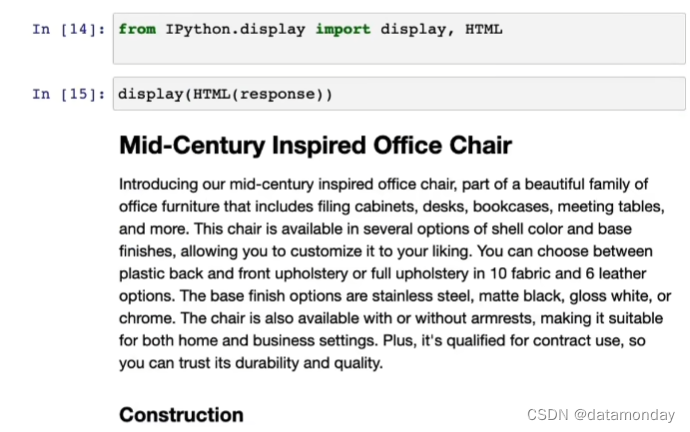
指明模型的输出格式为 HTML
4. 使用LLM总结文本
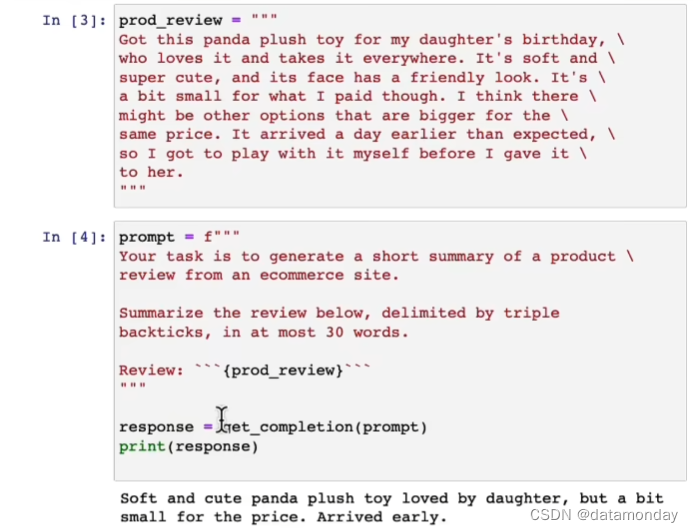
第一个例子,总结电商网站商品评论,限制30个单词。
为运输部分生成评论摘要:

生成的结果中可以看出,模型会更关注这些特定部门的相关信息。
为多条评论生成总结:

5. 使用LLM推理文本
以一个灯的评论为例,让模型推断这个评论的情感类型:
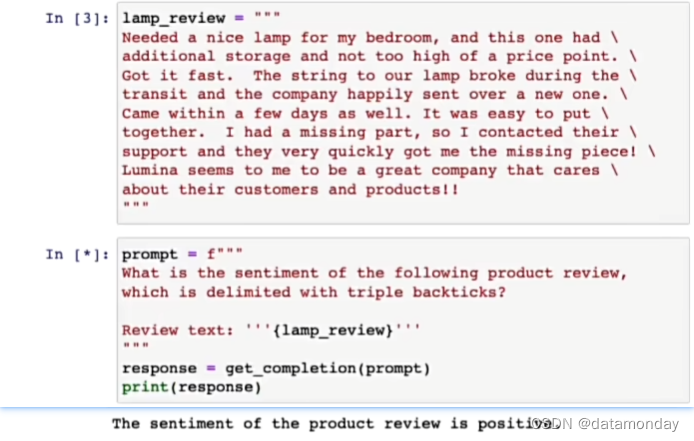
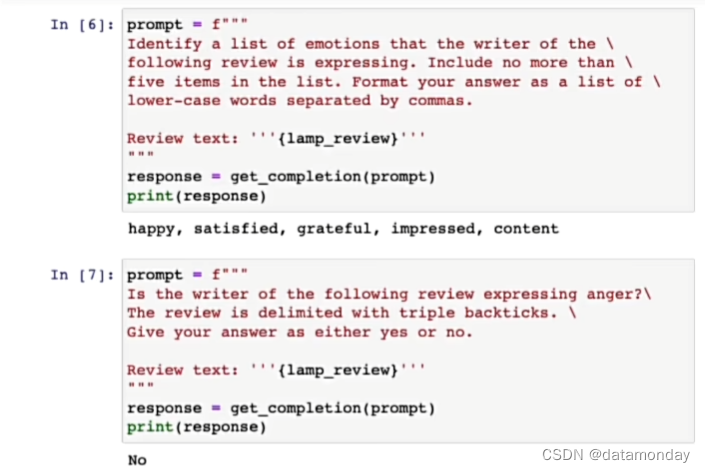
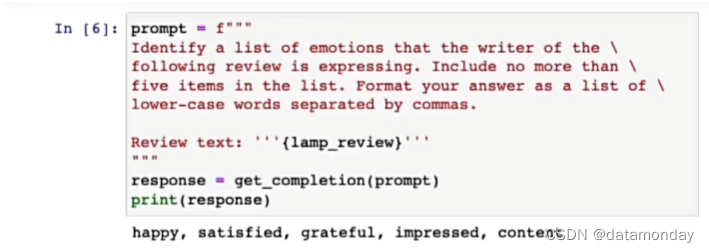
提取评论的情感:
给出是或否的回答:

将多个提示汇总到一个提示中,让模型统一给出结果:
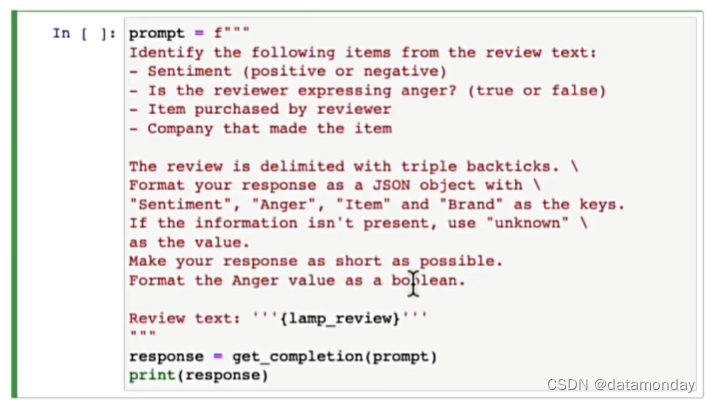
找出一篇文档属于哪个主题:
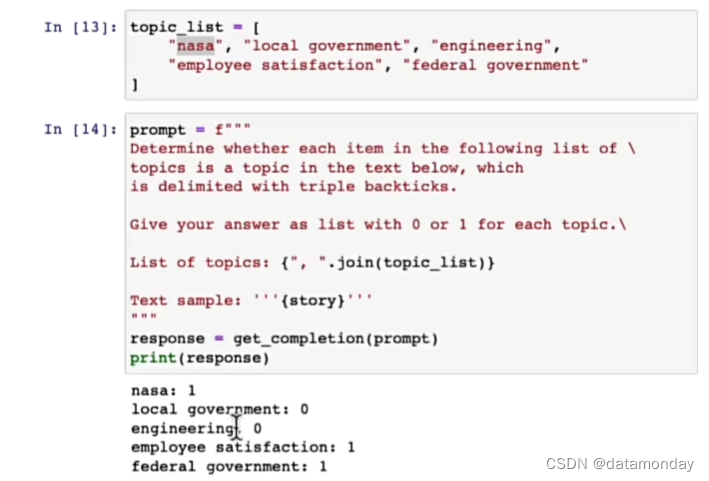
其背后的实现是零样本学习算法。
基于上述的提示,可以制作一个新闻提醒的下游应用,当有新的主题文档发布时,可以通知订阅了某些主题的用户。

6. 使用LLM转换文本
一些文本转换的例子:文本翻译,json转html,word转pdf,csv转excel等等。
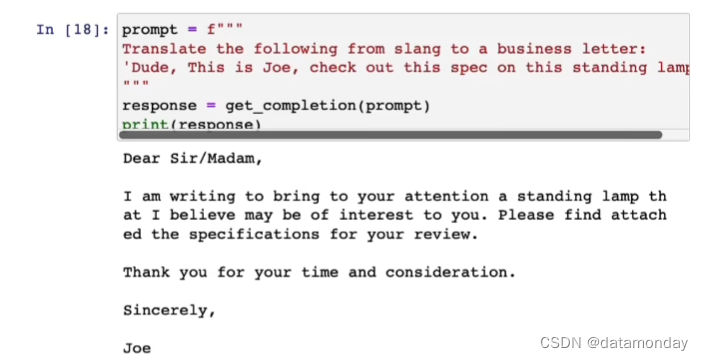
文本翻译:

推断语言:

翻译成多种语言:

根据不同的场合进行转换:

根据不同的语气进行转换:
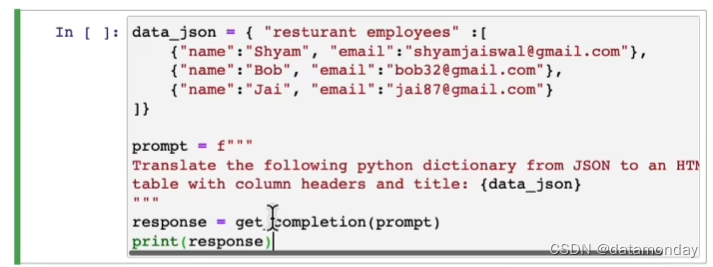
json转html:
修正语法错误:
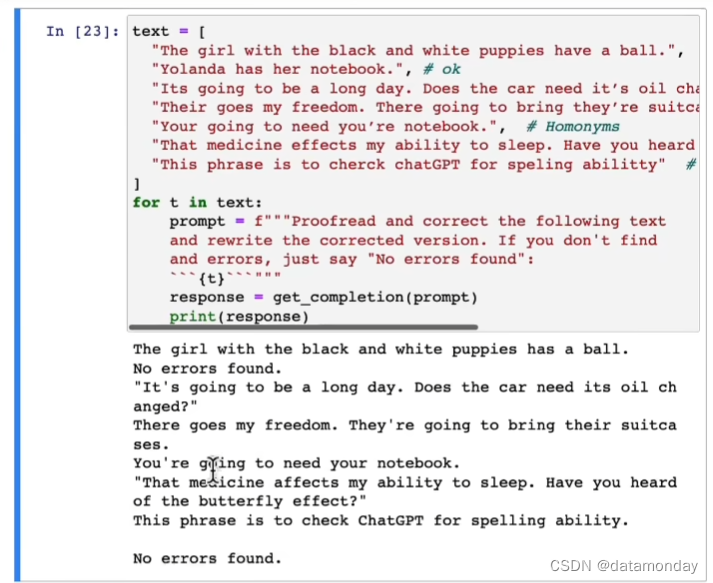
修正文本:

获得原始文本与修正之前文本的差异:

7. 使用LLM扩展文本
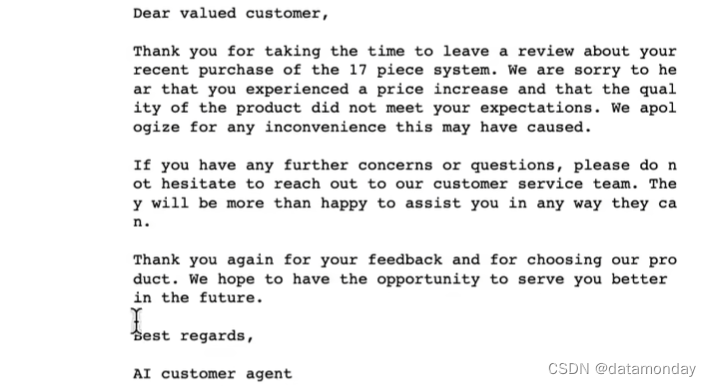
扩展文本旨在将短文本(一组说明或主体列表)通过大语言模型转换成更长的文本(比如一封电子邮件或者关于某个主体的文章)。
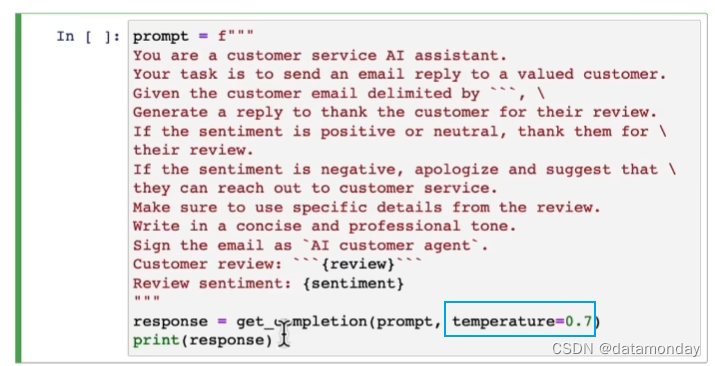
本小节将演示使用LLM生成个性化的电子邮件。

在使用LLM时,经常碰到的一个参数是温度(Temperature),其范围是0到1,它用于控制模型响应的多样性,可以将其视为模型的探索程度或随机性。
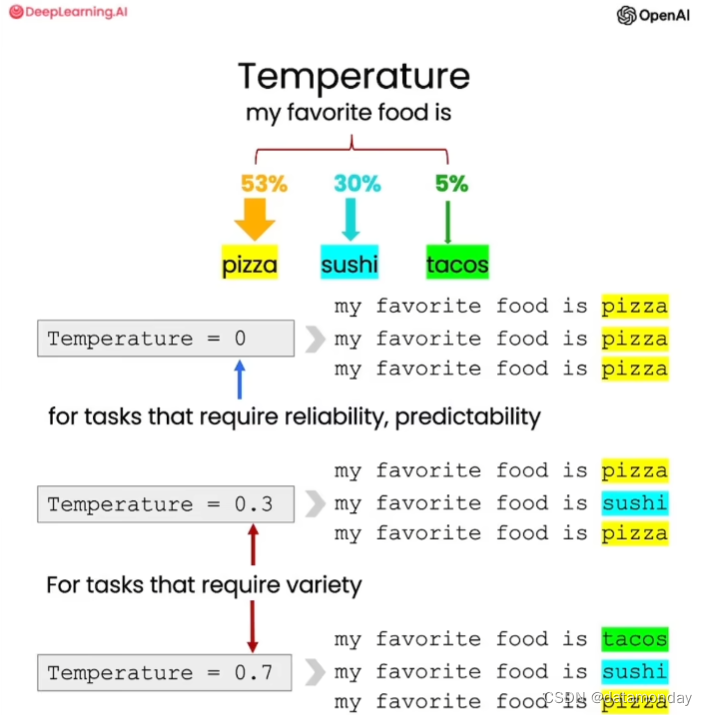
如果想让模型的响应更有多样性,则可以尝试提高温度值。如果想让模型的响应更稳定和更可预测,则可以将温度值设为0。
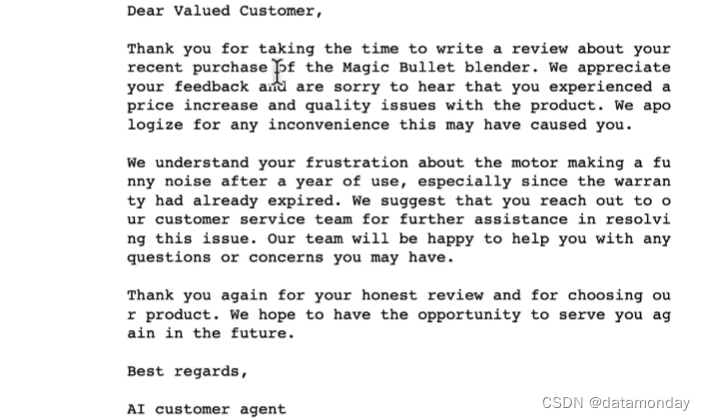
8. 使用LLM构建聊天机器人

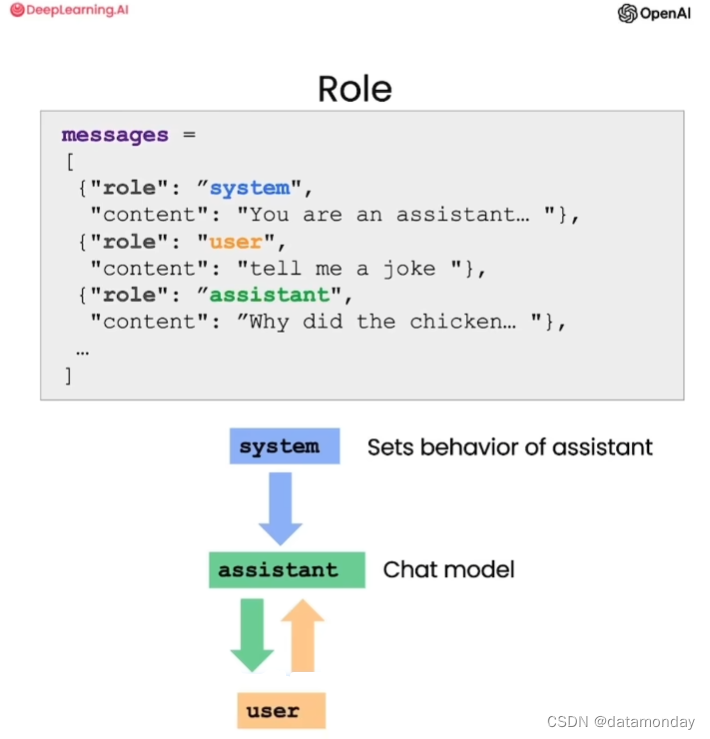
系统(system)消息提供了整体的指导方针,通常用于设定助手的行为和人设,引导LLM模型生成内容。其好处是为开发者提供了一种在不将请求体本身作为对话一部分的情况下,引导助手生成更贴近用户意图的输出。
用户(user)消息是用户的输入。
助手(assistant)消息是LLM模型的输出。
聊天机器人构建依赖于另一个API,其传入的不再是单个提示,而是个消息列表。这个列表中包含了多种不同角色的多轮对话的消息。
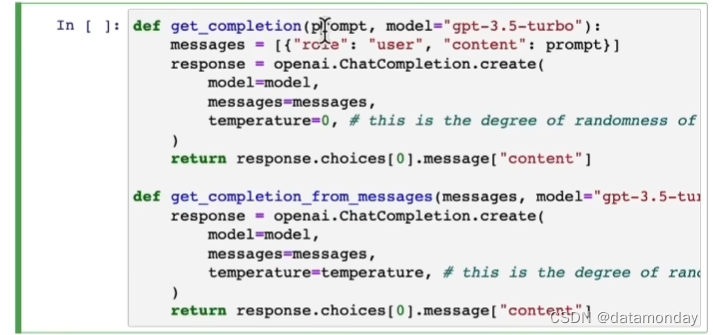

OpenAI 的 API 是无状态的,即不会保存聊天的上下文,所以如果要基于ChatGPT构建聊天机器人需要每次调用API前将用户的历史会话放到message列表里一起丢给ChatGPT,这样才可以让其具备上下文的记忆能力。
基于ChatGPT构建OrderBot的示例:

UI设置:
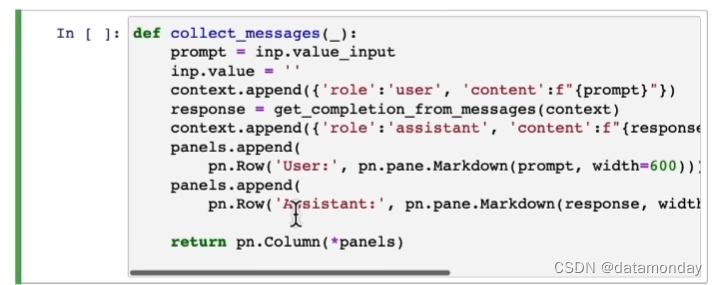


UI界面:
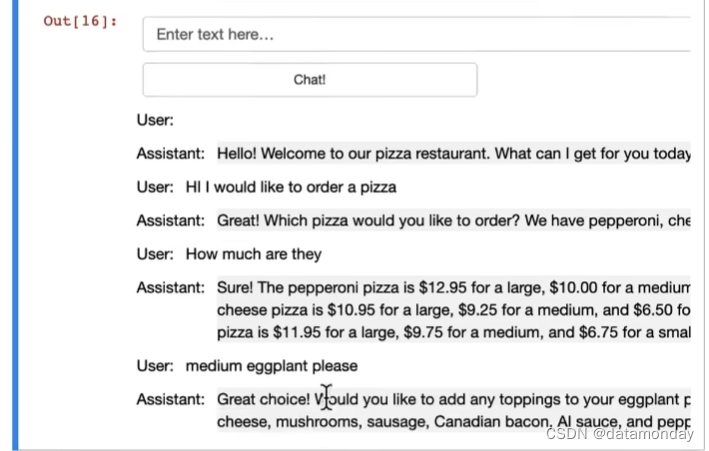
系统角色消息的编写:

结果:
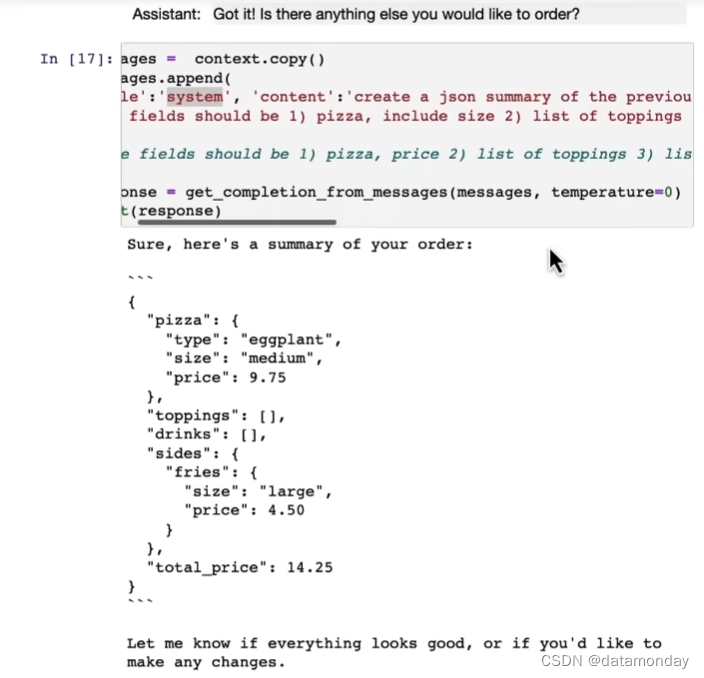
9. 总结
