Lesson 5 机器学习模型,Growth Function
+这章节的内容是Why can machines learn? 通过三节Lesson 来引入“VC维”这个概念,来证明机器学习的模型在处理训练集数据,一定存在模型并且模型是正确的。+
Growth Function \(m_{_\mathcal{H}}\)
基于上一课学到的Hoeffding 不等式,在数据集上有出现\(E_{in}(\mathcal{h})\)和\(E_{out}(\mathcal{h})\)差别过大的情况时,一般数据集空间\(\mathcal{D}\)上还会有其他子空间\(D_i\)对其他(参数不同)模型\(\mathcal{h_i}\)出现此类情况。所以会有PPT第7页的内容,将所有这些子空间上训练而出现较大偏差的\(\mathcal{h}\)的Hoeffding不等式相加,不等式右边会非常大——原因并不难,因为不等式左边各项有很多部分重复相加了。到此,暂时可以说还不能证明对于假设空间\(\mathcal{H}\)无穷大的情况,一定可以从训练集上学到一个准确的模型\(\mathcal{g}\)。
接着以上,改变Hoeffding 不等式右边上限无穷:将假设空间中的假设\(\mathcal{h}\)进行分类,力图把在不等式右边的\(M\)换为\(m_{_\mathcal{H}}\)。
先是以平面上线段划分:


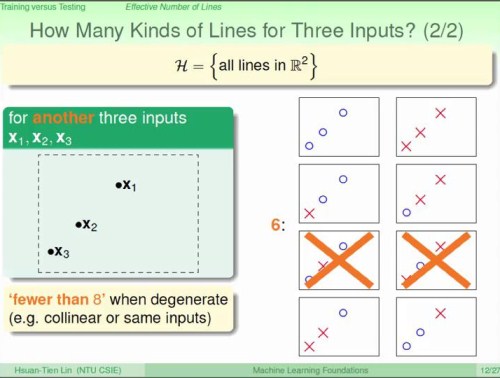

各种情况,都是以训练集中的点分布最不规则的情形下,计数分类的线。
以上思路是,由训练集的有限规模\(\mathcal{n}\)(样本数),将假设空间中的假设集合\(\mathcal{H}\)做出分类,不同的类个数用\(m_{_\mathcal{H}}\)表示。
在各种情况中,可以看到\(m_{_\mathcal{H}}\)存在上限,上限随训练集样本的个数增长而增长。
+上面的实验结果表明,\(\mathcal{H}\)内\(\mathcal{h}\)的差异性,对于特定的训练集来说,是有限的。+

到这里,阶段性地说,替换为\(m_{_\mathcal{H}}\)上面Hoeffding不等式右边上限无穷已经不是无穷大,目前是趋于0的。
在这里,为了在分析\(\mathcal{H}\)的\(m_{_\mathcal{H}}\)时不受\(\mathcal{D}\)的影响,定义
\(m_{_\mathcal{H}}(N) = \underset{\mathsf{x_{_1}, x_{_2}, \ldots, x_{_N}}\in \mathcal{X}}{max} \vert\mathcal{H}(\mathsf{x_1, x_2, \ldots, x_N})\vert\)(这其实是对上面0/1/2/3/4个样例点情况的推广)。对于\(\mathcal{H}\)中特殊的模型——二分类模型(dichtomy),经过分析,\(m_{_\mathcal{H}}(N)\) 的上限是\(2^N\)。




这里在LaTeX中使用了mathsf字体。
Break Point
如果没有任何一个包含\(k\)个实例的集合,可以被\(\mathcal{H}\) shatter,那么称\(k\)为break point。
这里,shatter的意思是,\(k\)个实例在二分类情景下有\(2^k\)中二分类结果,但是\(\mathcal{H}\)应用在\(\mathcal{D}\)上只能得到其中\(m_{_\mathcal{H}}\)种分类结果,那么说\(\mathcal{H}\)不能覆盖\(\mathcal{D}\)。

Lesson 6 Break Point
主要结论:二分类模型\(\mathcal{H}\)的break point是多项式级的,因而Hoeffding不等式右边趋于0。
\(m_{_\mathcal{H}}\) is restricted by break point
通过二分类模型\(\mathcal{H}\)的break point的规律,表达出求\(m_{_\mathcal{H}}\)上界的思路,是用break point。


bounding function
定义bounding function \(B(n,k)\),任何\(\mathcal{H}\),当\(m_{_\mathcal{H}}\)小于\(2^k\)时,\(B(n,k) = max m_{_\mathcal{H}}\)。如下:


对于上面表格中左下角的空格,有:
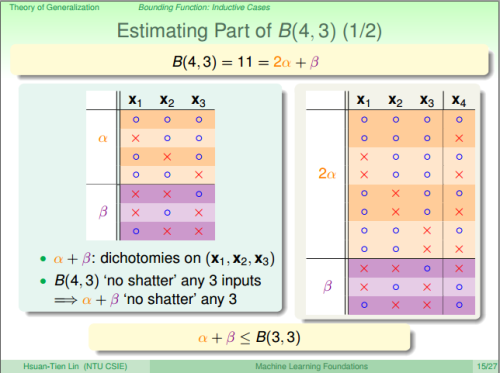


这里,有一个潜在的思路是,如果可以shatter \(k\)个数据实例,那么\(k-1\)个数据实例就没法shatter了(有点像线性代数的基向量,所有分量中的一部分是线性相关的,全部分量组成的向量才是线性无关的)。
根据以上的表格,可以推算出\(B(n,k)\)是\(N^{k-1}\)多项式级的(VC维的公式证明过程省略)。
Lesson 7 VC dimension
VC维的理解:一个\(\mathcal{H}\)是满足有限的VC 维,那么\(\mathcal{A}\)在\(\mathcal{D}\)上训练后选择的\(\mathcal{h}\),是从有限的\(\mathcal{h_i}\)中选择了一个,这个\(\mathcal{h}\)的\(E_{in}\)和\(E_{out}\)相差不会太大(Hoeffding 不等式);VC维使得\(\mathcal{H}\)不会因为数据集\(N\)的规模而无限增长,在\(\mathcal{A}\)选择\(\mathcal{h}\)的时候选择了一个较好的。相反,如果\(\mathcal{H}\)的VC维是无限的,那么可能在训练集上和训练集加测试集上,会有新的\(\mathcal{h_j}\)表现更好(原\(\mathcal{h}\)在\(E_{out}\)上表现较差)。
VC维的定义和使用过程中,要考虑到一般性,有时\(\mathcal{D_i}\)会因为自身实例的原因不能被\(\mathcal{h}\)所shatter,这不影响\(\mathcal{h}\)的VC-dimension。所以,要证明\(d_{VC} \ge d, d=1,2,\ldots, i\),需要找到某个\(\mathcal{D_j}\),可以被\(\mathcal{h}\)shatter。
VC 维for perception
通过推导,可以证明,感知机(perception)的\(d_{VC}= d+1\),\(d\)是特征的维度。
VC维的引申含义
感知机的模型参数\(W\)的维度正好是\(d+1\),值和VC维的\(d+1\)相同。\(W\)的维度表示模型的自由度,或者说模型有多少个参数可以调节。
VC维\(d+1\)不能直观地表示有多少个不同的\(d+1\)模型下的分类结果——\(N^{k-1}\)。可以直观地表示,对最多多少条数据,每条数据的分类结果都是不相关的。
(VC维的定义,对感知机来说,是同一组参数\(w_0, w_1, w_2, \ldots, w_{d}\)(其中\(w_0\)是常数)组成\(W\)所代表的\(\mathcal{h}\),最多可以给\(d+1\)个数据实例进行二分类,对\(d+2\)个数据实例就不能shatter了。类似,线性代数中,\(d+1\)个基向量的坐标系中,任意\(d+2\)个向量是线性相关的。)
VC维对模型选择的参考

模型参数(模型自由度)需要适中。