上一节中从数学角度证明了PLA在Data是处于linear separable的状态下在运行一段时间之后是一定能够停下来的。本节介绍了一种在不确定data是否处于linear separable的状态下的一种PLA的变体方法。
从上节知道,PLA能够halt表现在以下两个方面:
1、wf和wt的内积越来越大,且增长速度很快(说明向量wf和向量wt越来越接近);
2、wt的增长很缓慢(说明wt在不断变化)
使用PLA的好处在于实现简单,用HT Lin的话来说如果不加上演示部分代码的话实现代码不超过20行;
坏处在于使用PLA且能够halt的条件是Data必须处于linear separable的状态下,但是在我们获得data的时候是不知道它的状态的,因为wf是不可达的。所以要使用PLA必须先知道wf,而PLA的作用就是要求出与wf最接近的wt,这就陷入了一个循环论证的问题。再者说就算知道data是linear separable的,也不能确定PLA什么时候能够halt,最终将不能确定得到一条满足要求的线。
问题:如果data不是linear separable的呢?

考虑这样一种情况,有没有可能因为一些不可预知的错误(比如银行人员误发了信用卡)使得某些少部分的data不遵循wf的规则得到了错误的结果,造成了data不是linear separable的。这些结果称为Noisy Data。但是从实际情况上来看,这些Noisy Data应该实际上只占了整个data set很少的一部分。于是,我们求出的假设g如果能够在大部分的data上表现与f一致,那么g就可能成为最接近f的假设。也就是说,在所有的H集合中如果g的表现最好,那么g就可以成为最佳假设。
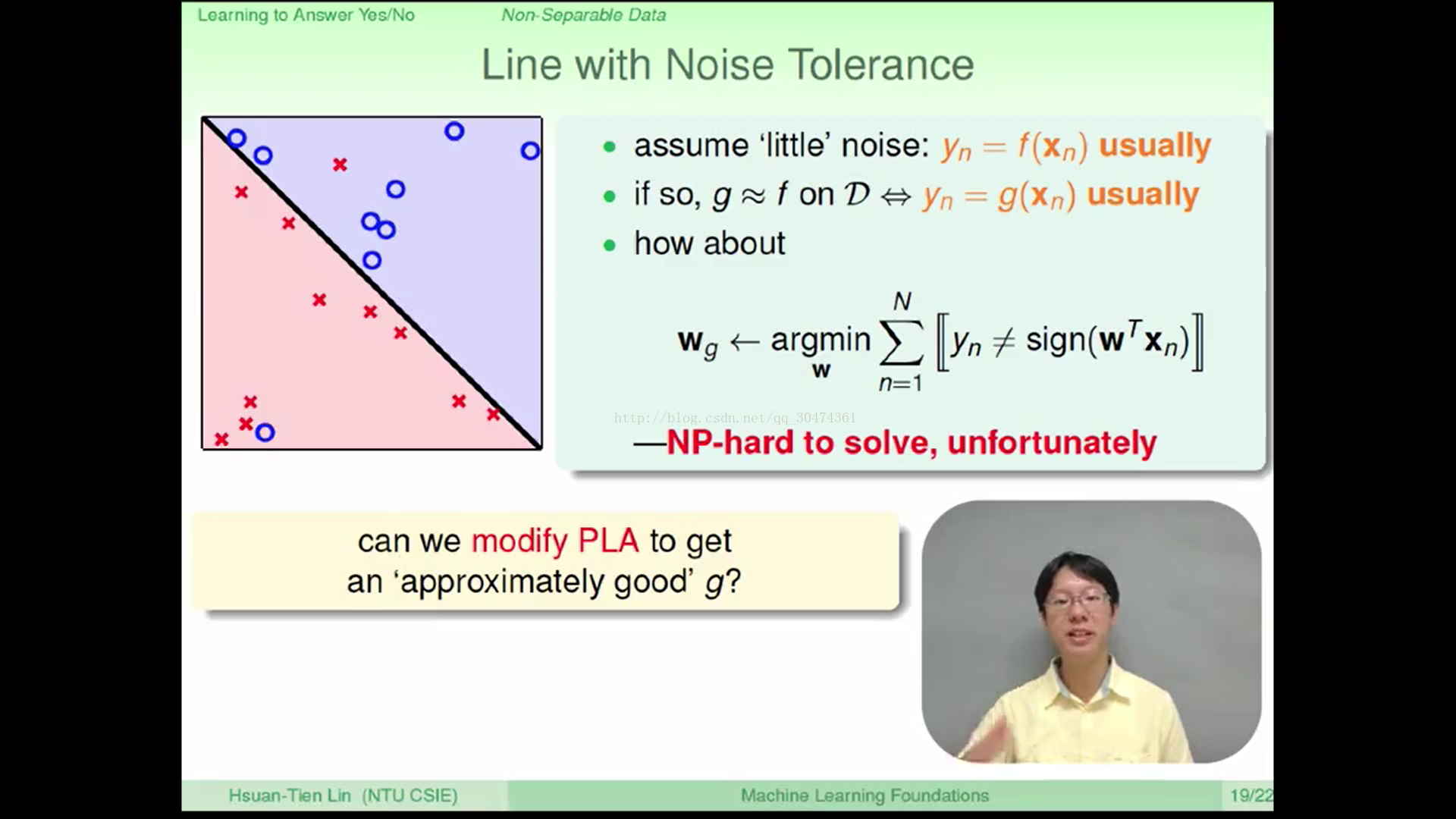
但是这个如何求出g是一个NP问题,不可解决,因此可以采用PLA的一个变体——Pocket Algorithm(译为贪心算法)。
PA的算法思想与PLA大致是一样的,但是有一点不同的是PA每找到一条线,就要与当前表现最好的一条线做比较。而且由于data可能是non linear separable的,因此PA可能会停不下来,这个时候可以采用规定迭代次数的方法人为地让PA停下来。

PA对比PLA:
好处:能够在不知道data是否linear separable的情况下进行,而且能够人工地设定迭代次数;
坏处:需要运行的时间和空间代价相对于PLA大;不一定能得到最好的结果;设定的迭代次数没有标准,不知道如何设定一个比较好的迭代次数。