前言
李沐大神源代码是用Jupyter写的,笔者想用Pycharm实现并仅作为学习笔记,如有侵权,请联系笔者删除。
一、简介
多层感知机跟前面的线性回归模型很像,只不过多了隐藏层,并且隐藏层在输出的时候添加了非线性激活函数(非线性激活函数本质上是为了避免层数塌陷,否则层再多也等价与一层,这里用公式很容易就能推出来)。对于多层感知机的模型建立,理论上一般可以选择两种模式,一是只有一层,一层有很多很多神经元;二是有很多层,每层神经元个数大致从多到少。这两种模型的复杂度是相当的,但是实际情况中第一种不太好训练,容易过拟合,所以一般选择第二种。
二、多层感知机代码
python版本:3.8.6
torch版本:1.11.0
d2l版本:0.17.5
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Flatten(), # flatten: 展平层,将输入数据展平,这里只保留第0维度
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def init_weights(m): # m: 当前layer
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
# m.weight 默认为0,这一行的意思就是说把当前layer层的参数初始化成均值为0,标准差为0.01
net.apply(init_weights) # 每一层的权值都进行初始化
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none') # 交叉熵损失函数
trainer = torch.optim.SGD(net.parameters(), lr=lr) # 优化器选择随机梯度下降
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
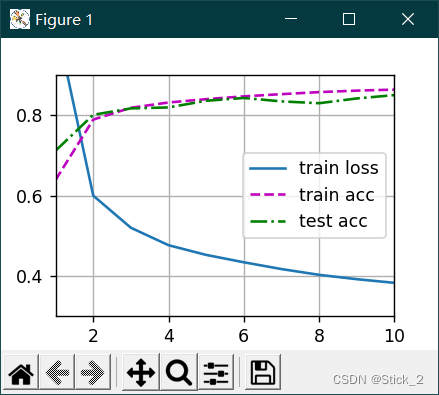
三、运行结果如下