动手学深度学习(三、深度学习基础--多层感知机、基础知识)
1.隐藏层
2.激活函数
- ReLU函数
- sigmoid函数
- tanh函数
一、多层感知机的从零开始实现
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。多层感知机的层数和各隐藏层中隐藏单元个数都是超参数。
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("F:\数据\MRC\动手学深度学习\Dive-into-DL-PyTorch-master\code")
import d2lzh_pytorch as d2l
#1.获取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize = None, root = 'F:\数据\MRC\dataset')
#2.定义模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype = torch.float)
b1 = torch.zeros(num_hiddens, dtype = torch.float)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_outputs)), dtype = torch.float)
b2 = torch.zeros(num_outputs, dtype = torch.float)
params = [W1, b1, W2, b2]
for param in params:
param.requires_grad_(requires_grad = True)
#3.定义激活函数
def relu(X):
return torch.max(input = X, other = torch.tensor(0.0))
#4.定义模型
def net(X):
X = X.view((-1, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b2
#5.定义损失函数
#使用Pytorch提供的包括softmax运算和交叉熵损失计算的函数
loss = torch.nn.CrossEntropyLoss()
#6.训练模型
num_epochs, lr = 5, 100.0
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
多层感知机区别于线性回归, 定义的模型参数较多, 添加激活函数, 模型多一层结构
epoch 1, loss 0.0030, train acc 0.711, test acc 0.793
epoch 2, loss 0.0019, train acc 0.821, test acc 0.829
epoch 3, loss 0.0017, train acc 0.845, test acc 0.842
epoch 4, loss 0.0015, train acc 0.857, test acc 0.844
epoch 5, loss 0.0014, train acc 0.864, test acc 0.845二、多层感知机的简洁实现
对于参数矩阵还不是特别了解(对于参数矩阵的行以及列混淆不清)
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("F:\数据\MRC\动手学深度学习\Dive-into-DL-PyTorch-master\code")
import d2lzh_pytorch as d2l
#1.定义模型
num_inputs, num_outputs, num_hiddens = 784, 10, 100
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
print(net.parameters())
for params in net.parameters():
print(params.shape)
for params in net.parameters():
init.normal_(params, mean = 0, std = 0.01)
#2.读取数据并训练模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr = 0.5)
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
<generator object Module.parameters at 0x000001A38440FBA0>
torch.Size([100, 784])
torch.Size([100])
torch.Size([10, 100])
torch.Size([10])
epoch 1, loss 0.0033, train acc 0.687, test acc 0.741
epoch 2, loss 0.0020, train acc 0.815, test acc 0.834
epoch 3, loss 0.0017, train acc 0.839, test acc 0.764
epoch 4, loss 0.0016, train acc 0.852, test acc 0.814
epoch 5, loss 0.0015, train acc 0.860, test acc 0.837三、模型选择、欠拟合和过拟合
我们需要区分训练误差(training error)和泛化误差(generalization error)。训练误差的期望小于或等于泛化误差。也就是说,一般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。机器学习模型应关注降低泛化误差。
在机器学习中,通常需要评估若干候选模型的表现并从中选择模型。这一过程称为模型选择(model selection)。
- 验证数据集
- K折交叉验证
欠拟合和过拟合
模型复杂度
给定训练数据集,模型复杂度和误差之间的关系通常如图3.4所示。给定训练数据集,如果模型的复杂度过低,很容易出现欠拟合;如果模型复杂度过高,很容易出现过拟合。应对欠拟合和过拟合的一个办法是针对数据集选择合适复杂度的模型。

训练数据集大小
一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
- 由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。机器学习模型应关注降低泛化误差。
- 可以使用验证数据集来进行模型选择。
- 欠拟合指模型无法得到较低的训练误差,过拟合指模型的训练误差远小于它在测试数据集上的误差。
- 应选择复杂度合适的模型并避免使用过少的训练样本。
四、权重衰减
- 正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。
- 权重衰减等价于L2L_2L2范数正则化,通常会使学到的权重参数的元素较接近0。
- 权重衰减可以通过优化器中的
weight_decay超参数来指定。 - 可以定义多个优化器实例对不同的模型参数使用不同的迭代方法。
对过拟合问题的常用方法:权重衰减(weight decay)。
权重衰减等价于 L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述L2范数正则化,再解释它为何又称权重衰减。
L2范数正则化在模型原损失函数基础上添加L2范数惩罚项,从而得到训练所需要最小化的函数。L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。
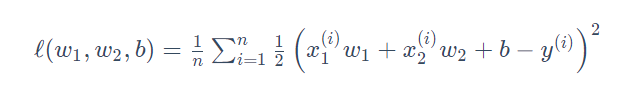
其中w1,w2是权重参数,b是偏差参数, 样本数为n。将权重参数用向量w=[w1,w2]表示,带有L2范数惩罚项的新损失函数为

其中超参数λ>0。当权重参数均为0时,惩罚项最小。当λ较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当λ设为0时,惩罚项完全不起作用。上式中L2范数平方展开后得到
。可见,L2范数正则化令权重w1和w2先自乘小于1的数,再减去不含惩罚项的梯度。因此,L2范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,我们有时也在惩罚项中添加偏差元素的平方和。
权重衰减从零开始实现
#权重衰减
import torch
import torch.nn as nn
import numpy as np
from IPython import display
from matplotlib import pyplot as plt
import sys
sys.path.append("F:\数据\MRC\动手学深度学习\Dive-into-DL-PyTorch-master\code")
import d2lzh_pytorch as d2l
#数据构造
n_train, n_test, num_inputs = 20, 100, 20
true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05
features = torch.randn((n_train + n_test, num_inputs))
labels = torch.matmul(features, true_w) + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
train_features, test_features = features[:n_train, :], features[n_train:, :]
train_labels, test_labels = labels[:n_train], labels[n_train:]
print(train_labels[0])
#初始化模型参数
def init_params():
w = torch.randn((num_inputs, 1), requires_grad = True)
b = torch.zeros(1, requires_grad = True)
return [w, b]
#定义L2范数惩罚项
def l2_penalty(w):
return (w ** 2).sum() / 2
def linreg(X, w, b):
return torch.mm(X, w) + b
#注意这里返回的是向量,另外,pytorch里的MSELoss并没有除以2
def squared_loss(y_hat, y):
return ((y_hat - y.view(y_hat.size())) ** 2) / 2
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size
batch_size, num_epochs, lr = 1, 100, 0.003
net, loss = linreg, squared_loss
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle = True)
#绘图操作
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
def use_svg_display():
"""Use svg format to display plot in jupyter"""
display.set_matplotlib_formats('svg')
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
set_figsize(figsize)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
plt.semilogy(x2_vals, y2_vals, linestyle=':')
plt.legend(legend)
# plt.show()
def fit_and_plot(lambd):
w, b = init_params()
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
#添加L2范数惩罚项
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
l = l.sum()
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
sgd([w, b], lr, batch_size)
train_ls.append(loss(net(train_features, w, b), train_labels).mean().item())
test_ls.append(loss(net(test_features, w, b), test_labels).mean().item())
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', w.norm().item())
fit_and_plot(lambd = 3)

对于lambd中参数数值的不同。当lambd = 0时,无权重衰减,易出现过拟合现象。当lambd = 3时,有效减轻了过拟合的情况。
权重衰减简洁实现
def fit_and_plot_pytorch(wd):
net = nn.Linear(num_inputs, 1)
nn.init.normal_(net.weight, mean = 0, std = 1)
nn.init.normal_(net.bias, mean = 0, std = 1)
optimizer_w = torch.optim.SGD(params = [net.weight], lr = lr, weight_decay = wd)#对权重参数衰减
optimizer_b = torch.optim.SGD(params = [net.bias], lr = lr)#不对偏差参数衰减
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y).mean()
optimizer_w.zero_grad()
optimizer_b.zero_grad()
l.backward()
# 对两个optimizer实例分别调用step函数,从而分别更新权重和偏差
optimizer_w.step()
optimizer_b.step()
train_ls.append(loss(net(train_features), train_labels).mean().item())
test_ls.append(loss(net(test_features), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', net.weight.data.norm().item())
fit_and_plot_pytorch(3)

五、丢弃法
- 我们可以通过使用丢弃法应对过拟合。
- 丢弃法只在训练模型时使用。
深度学习模型常常使用丢弃法(dropout)来应对过拟合问题。丢弃法有一些不同的变体。倒置丢弃法(inverted dropout)。dropout出自该篇[1] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. JMLR
当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为p,那么有p的概率hi会被清零,有1−p的概率hi会除以1−p做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量为0和1的概率分别为p和1−p。使用丢弃法时我们计算新的隐藏单元hi′
丢弃法不改变其输入的期望值, 在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,一般不使用丢弃法。
从零开始丢弃法实现
用函数方法实现了dropout函数功能
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("F:\数据\MRC\动手学深度学习\Dive-into-DL-PyTorch-master\code")
import d2lzh_pytorch as d2l
def dropout(X, drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
if keep_prob == 0:
return torch.zeros_like(X)
mask = (torch.rand(X.shape) < keep_prob).float()
#print(mask)
return mask * X / keep_prob
X = torch.arange(16).view(2, 8)
#print(X)
ans = dropout(X, 0.5)
print(ans)
#定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
W1 = torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens1)), dtype=torch.float, requires_grad=True)
b1 = torch.zeros(num_hiddens1, requires_grad=True)
W2 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens1, num_hiddens2)), dtype=torch.float, requires_grad=True)
b2 = torch.zeros(num_hiddens2, requires_grad=True)
W3 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens2, num_outputs)), dtype=torch.float, requires_grad=True)
b3 = torch.zeros(num_outputs, requires_grad=True)
params = [W1, b1, W2, b2, W3, b3]
#定义模型
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X, is_training = True):
X = X.view(-1, num_inputs)
H1 = (torch.matmul(X, W1) + b1).relu()
if is_training:
H1 = dropout(H1, drop_prob1)
H2 = (torch.matmul(H1, W2) + b2).relu()
if is_training:
H2 = dropout(H2, drop_prob2)
return torch.matmul(H2, W3) + b3
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else: # 自定义的模型
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
#训练和测试模型
num_epochs, lr, batch_size = 5, 100.0, 256
loss = torch.nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)丢弃法简洁实现
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("F:\数据\MRC\动手学深度学习\Dive-into-DL-PyTorch-master\code")
import d2lzh_pytorch as d2l
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
drop_prob1, drop_prob2 = 0.2, 0.5
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens2, 10)
)
for param in net.parameters():
nn.init.normal_(param, mean = 0, std = 0.01)
optimizer = torch.optim.SGD(net.parameters(), lr = 0.5)
num_epochs, lr, batch_size = 5, 100.0, 256
loss = torch.nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)#输出结果:
epoch 1, loss 0.0047, train acc 0.536, test acc 0.730
epoch 2, loss 0.0023, train acc 0.784, test acc 0.791
epoch 3, loss 0.0019, train acc 0.818, test acc 0.787
epoch 4, loss 0.0018, train acc 0.836, test acc 0.821
epoch 5, loss 0.0016, train acc 0.847, test acc 0.848六、正向传播、反向传播、计算图、数值稳定性、模型初始化
正则化其实是一种策略,以增大训练误差为代价来减少测试误差的所有策略我们都可以称作为正则化。换句话说就是正则化是为了防止模型过拟合。L2范数就是最常用的正则化方法之一。
- 正向传播沿着从输入层到输出层的顺序,依次计算并存储神经网络的中间变量。
- 反向传播沿着从输出层到输入层的顺序,依次计算并存储神经网络中间变量和参数的梯度。
- 在训练深度学习模型时,正向传播和反向传播相互依赖。
在模型参数初始化完成后,我们交替地进行正向传播和反向传播,并根据反向传播计算的梯度迭代模型参数。既然我们在反向传播中使用了正向传播中计算得到的中间变量来避免重复计算,那么这个复用也导致正向传播结束后不能立即释放中间变量内存。这也是训练要比预测占用更多内存的一个重要原因。另外需要指出的是,这些中间变量的个数大体上与网络层数线性相关,每个变量的大小跟批量大小和输入个数也是线性相关的,它们是导致较深的神经网络使用较大批量训练时更容易超内存的主要原因。
- 深度模型有关数值稳定性的典型问题是衰减和爆炸。当神经网络的层数较多时,模型的数值稳定性容易变差。
- 我们通常需要随机初始化神经网络的模型参数,如权重参数。
深度模型有关数值稳定性的典型问题是衰减(vanishing)和爆炸(explosion)。
当神经网络的层数较多时,模型的数值稳定性容易变差。类似地,当层数较多时,梯度的计算也更容易出现衰减或爆炸。
在神经网络中,通常需要随机初始化模型参数。我们通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
随机初始化模型参数的方法有很多。我们使用torch.nn.init.normal_()使模型net的权重参数采用正态分布的随机初始化方式。不过,PyTorch中nn.Module的模块参数都采取了较为合理的初始化策略(不同类型的layer具体采样的哪一种初始化方法的可参考源代码),因此一般不用我们考虑。
还有一种比较常用的随机初始化方法叫作Xavier随机初始化。 假设某全连接层的输入个数为a,输出个数为b,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布。它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。