【动手学深度学习】—0x04:多层感知机
1)隐藏层
再神经网络中除了输出层和输入层的层
多层感知层的层数为隐藏层加输出层(输入层不涉及计算)
隐藏层中的神经元和输入层中各个输入完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接,所以多层感知机中的隐藏层和输出层都是全连接层。
2)激活函数
全连接层只是对数据做仿射变换
ReLU函数
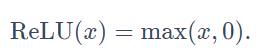


sigmoid函数
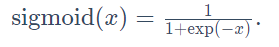


tanh函数
tanh(双曲正切)函数可以将元素的值变换到-1和1之间:



3)多层感知机从零实现
import torch
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
# 读取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 定义模型参数
# Fashion-MNIST数据集中图像形状为 28×28 = 784
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float)
b1 = torch.zeros(num_hiddens, dtype=torch.float)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_outputs)), dtype=torch.float)
b2 = torch.zeros(num_outputs, dtype=torch.float)
params = [W1, b1, W2, b2]
for param in params:
param.requires_grad_(requires_grad=True)
# 定义激活函数
def relu(X):
return torch.max(input=X, other=torch.tensor(0.0))
# 定义模型
def net(X):
X = X.view((-1, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b2
# 定义损失函数
loss = torch.nn.CrossEntropyLoss()
# 训练模型
num_epochs, lr = 5, 100.0
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
4)多层感知机的简洁实现
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
# 定义模型
num_inputs, num_outputs, num_hiddens = 784, 10, 256
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
for params in net.parameters():
init.normal_(params, mean=0, std=0.01)
# 读取数据并训练模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
参考资料
https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter03_DL-basics/3.10_mlp-pytorch