CVPR2022 | ZeroCap:零样本图像到文本生成的视觉语义算法
【写在前面】
最近的文本到图像匹配模型将对比学习应用于大量未经管理的图像和句子对。虽然此类模型可以为匹配和后续的zero-shot任务提供强大的分数,但它们无法在给定图像的情况下生成标题。在这项工作中,作者重新利用这些模型来在推理时生成给定图像的描述性文本,而无需任何进一步的训练或调整步骤。这是通过将视觉语义模型与大型语言模型相结合来完成的,受益于这两种网络规模模型中的知识。由此产生的字幕比通过监督字幕方法获得的字幕限制要少得多。此外,作为一种零样本学习方法,它非常灵活,展示了它执行图像运算的能力,其中输入可以是图像或文本,输出是一个句子。这实现了新颖的高级视觉功能,例如比较两个图像或解决视觉类比测试。
1. 论文和代码地址

ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
论文地址:https://arxiv.org/abs/2111.14447
代码地址:https://github.com/YoadTew/zero-shot-image-to-text
2. 动机
深度学习至少导致了计算机视觉的三大革命:(1)机器在多个领域中比预期更早地实现了被认为是人类水平的性能,(2)有效的迁移学习,支持新领域的快速建模,以及(3)通过使用对抗性和自监督学习实现无监督学习的飞跃。
当前正在发生的第四次革命是零样本学习。 OpenAI 的一项开创性工作提出了基于变压器的GPT-3 模型。该模型在非常大的文本语料库上进行训练,然后可以根据提示生成文本。如果提示包含指令,GTP-3 通常可以执行它。例如,给定提示“将英语翻译成法语:typical → typique→house → . . .”会生成“maison”这个词。
后来 OpenAI 在计算机视觉中也展示了令人印象深刻的零样本能力。虽然最先进的计算机视觉模型通常被训练为推断固定数量标签的任务特定模型,但 Radford 等人提出了 CLIP 图像-文本Transformer模型,该模型可以执行数十个下游任务,无需进一步训练,其准确性可与现有技术相媲美。这是通过在给定图像的情况下从“这是 X 的图像”形式的句子中选择最佳匹配来完成的。
在这项工作中,作者使用 CLIP 来执行 DALL-E 的逆任务,即零样本图像字幕。给定一张图像,作者使用 CLIP 和 GPT-2 语言模型(无法访问 GPT-3)来生成输入图像的文本描述。除了 Radford 等人展示的固定提示零样本学习之外,这为 CLIP 添加了新的图像分析功能。
作为一种零样本方法,本文的方法不涉及任何训练。有人可以争辩说,底层 CLIP 模型是用与图像字幕方法训练的完全相同类型的监督来训练的,即成对的匹配图像和字幕。然而,图像字幕方法是从精选来源训练的,例如 MSCOCO 或 Visual Genome,而 CLIP 是在 Web Image Text (WIT) 上训练的,这是一个自动收集的网络规模数据集。以前在 WIT 上训练字幕模型的尝试导致在识别图像中的对象方面表现不佳。

由于方法和基础数据的差异,本文的方法产生的字幕与监督字幕方法获得的字幕非常不同。虽然监督方法可以模仿人类注释器并提供相似的句子,但就常规 NLP 指标(例如 BLEU )而言,本文的结果在视觉语义 CLIP 嵌入中表现出更大的自由度并更好地匹配图像空间。此外,合并到 CLIP 和 GPT-2 中的语义知识体现在生成的标题中,见上图。
除了获得的字幕的不同性质之外,本文的方法也更加灵活,因为所有计算都发生在推理时间。具体来说,作者展示了通过使用一种新的算术形式在图像空间中执行语义分析的能力。NLP 中概念算术的一个著名示例是检索词“queen”作为嵌入空间中最接近涉及与“king”、“man”和“woman”相关的嵌入向量的方程, 在从第一个减去第二个并添加第三个之后。作者展示了一种新颖的能力,仅使用图像而不是单词,因此结果生成为短句,而不仅仅是单词,见上图。
作为推论,例如,可以询问两个场景之间的区别是什么。这种在语义上比较两个图像的能力是一种新颖的计算机视觉能力,它进一步展示了零样本学习的力量。
3. 方法
视觉字幕是为图像生成描述性句子的过程。它可以形式化为给定输入图像 I 的序列生成问题,即作为句子的第 i 个单词 xi 的条件概率推断。
这通常以有监督的方式完成,通过优化权重来重现真实句子。然而,由于精心策划的数据集很小,并且无法充分描述所有图像,因此生成的句子通常描述场景中存在的对象的基本级别的内容,并且听起来很人工。使用网络规模的数据集可以缓解此类问题。作者提出了一种使用大规模文本图像对齐模型来引导大规模语言模型的零样本方法。
Overview

本文的方法使用基于Transformer的 LM(例如 GPT-2)从初始提示中推断下一个单词,例如“a 的图像”,如上图所示。为了将图像相关知识纳入自回归过程,校准的 CLIP 损失 L CLIP \mathcal{L}_{\text {CLIP }} LCLIP 会刺激模型生成描述给定图像的句子。一个额外的损失项 L C E \mathcal{L}_{\mathrm{CE}} LCE 用于维护类似于原始语言模型的下一个token分布。
此外,本文方法的灵活性能够通过 CLIP 嵌入空间中的视觉线索的简单算术来捕获语义关系。最后,将多模态编码器与本文的方法相结合,可以以一种在文本和图像之间混合的新方式提取知识。
Language models
近年来,LM 有了显着提高,并且越来越接近 AI 完备的能力,包括广泛的外部知识和在有限监督下解决各种各样的任务。基于 Transformer 的 LM 通常在每个时间步对生成的token和过去的token之间的交互进行建模。
transformer 块具有三个嵌入函数 K、Q、V 。前两个,K,Q,学习决定 V 分布的token交互。注意力机制基于查询和键之间的相似性来汇集值。具体来说,每个token i 的池化值取决于与此token Q i Q_{i} Qi关联的查询,该查询是使用函数 Q 在此token的当前嵌入上计算的。基于 Q i Q_{i} Qi和与所有token $ K_{j} $关联的键之间的余弦相似度,作为值向量的加权平均值获得结果。
虽然 K 和 V 是函数,但在生成文本时会重复使用获得的键和值 $ K_j $和 V j V_j Vj,一次一个词。因此,$ K_j $和 V j V_j Vj可以存储在所谓的上下文缓存中,以便跟踪 K 和 V 的过去嵌入输出。
其中 X i \mathcal{X}_{i} Xi 是生成句子的第 i 个词, K j l , V j l K_{j}^{l}, V_{j}^{l} Kjl,Vjl是上下文Transformer的第 j 个标记的键和值,l 表示Transformer层的索引,总共 L 层。本文的方法采用 GPT-2,它有 L = 24 层。
接下来描述如何将本文的 LM 与输入图像对齐。通过在推理过程中修改上下文缓存的值来保持 LM 不变。
CLIP-Guided language modelling
本文的目标是在每一代步骤中引导 LM 朝着期望的视觉方向前进。提出的指导有两个主要目标:(i)与给定图像对齐; (ii) 维护语言属性。第一个目标是通过 CLIP 获得的,CLIP 用于评估token与图像的相关性并相应地调整模型(或者更确切地说,缓存)。对于第二个目标,将目标规范化为与原始目标输出相似,即在修改之前。
求解的优化问题在每个时间点调整上下文缓存 C i C_{i} Ci并正式定义为 :
arg min C i L C L I P ( L M ( x i , C i ) , I ) + λ L C E ( LM ( x i , C i ) , x ^ i + 1 ) \begin{aligned} \arg \min _{C_{i}} \mathcal{L}_{\mathrm{CLIP}}(\mathrm{LM}&\left.\left(x_{i}, C_{i}\right), I\right) \\ &+\lambda \mathcal{L}_{\mathrm{CE}}\left(\operatorname{LM}\left(x_{i}, C_{i}\right), \hat{x}_{i+1}\right) \end{aligned} argCiminLCLIP(LM(xi,Ci),I)+λLCE(LM(xi,Ci),x^i+1)
其中 x ^ i + 1 \hat{x}_{i+1} x^i+1是使用原始的、未修改的上下文缓存获得的token分布。第二项使用 CE 损失来确保具有修改上下文的单词之间的概率分布接近原始 LM 的概率分布。超参数 λ 平衡了两个损失项。它在开发过程的早期被设置为 0.2,此后未修改。接下来,解释如何计算 CLIP 损失项。
CLIP loss
作者在时间 i 计算可能标记的图像相关性。计算前 512 个token候选者的潜力并将其余的潜力设置为零以提高效率就足够了。为此,将第 k 个候选token的相应候选语句 s i k = ( x 1 , … , x i − 1 , x i k ) s_{i}^{k}=\left(x_{1}, \ldots, x_{i-1}, x_{i}^{k}\right) sik=(x1,…,xi−1,xik)与图像 I 进行匹配。
第 k 个token的CLIP潜力计算为:
p i k ∝ exp ( D C L I P ( E Text ( s i k ) , E Image ( I ) ) / τ c ) ) , \left.p_{i}^{k} \propto \exp \left(\mathrm{D}_{\mathrm{CLIP}}\left(E_{\text {Text }}\left(s_{i}^{k}\right), E_{\text {Image }}(I)\right) / \tau_{c}\right)\right), pik∝exp(DCLIP(EText (sik),EImage (I))/τc)),
其中 D CLIP D_{\text {CLIP }} DCLIP 是 CLIP 嵌入文本(即 E Text E_{\text {Text }} EText )和图像(即 E Image E_{\text {Image }} EImage )之间的余弦距离, τ c > 0 \tau_{c}>0 τc>0是控制目标分布清晰度的温度超参数。在所有的实验中,作者将 τc 设置为 0.01。
CLIP loss定义为语言模型得到的下一个token x i + 1 x_{i+1} xi+1的clip潜在分布与目标分布之间的交叉熵损失:
L CLIP = C E ( p i , x i + 1 ) . \mathcal{L}_{\text {CLIP }}=\mathrm{CE}\left(p_{i}, x_{i+1}\right) . LCLIP =CE(pi,xi+1).
这种损失鼓励了在图像和生成的句子之间导致更高 CLIP 匹配分数的单词。
Inference
作为零样本方法,不进行任何训练。在推理时,优化损失函数的问题,作者将其表示为 p ( x i + 1 ∣ C i ) p\left(x_{i+1} \mid C_{i}\right) p(xi+1∣Ci),通过执行五个梯度下降步骤,即,
C i ⟵ C i + α ∇ C i p ( x i + 1 ∣ C i ) ∥ ∇ C i p ( x i + 1 ∣ C i ) ∥ 2 . C_{i} \longleftarrow C_{i}+\alpha \frac{\nabla_{C_{i}} p\left(x_{i+1} \mid C_{i}\right)}{\left\|\nabla_{C_{i}} p\left(x_{i+1} \mid C_{i}\right)\right\|^{2}} . Ci⟵Ci+α∥∇Cip(xi+1∣Ci)∥2∇Cip(xi+1∣Ci).
为简洁起见,简化了此更新规则。对于每个新生成的token,都会重新进行优化。在本文的实现中,梯度在每一步之前使用欧几里得归一化进行归一化,分别针对每个Transformer层。将学习率 α 设置为 0.3。
Beam search
字节级标记器使用 256 个字节的基本token来表示存在的每个单词。任何单词也可以分成多个子词,例如,单词“zebra”被标记为“zeb”和“ra”。结果,作者发现斑马的图像被描述为条纹动物,因为没有选择标记“zeb”。束搜索推理通过使搜索以一种不那么近视的方式进行来帮助解决这个问题。
Visual-Semantic Arithmetic
最近的研究表明,CLIP 多模态表示具有详尽的概念分类法。按照这种直觉,作者发现本文的方法可以用文本的方式表达 CLIP 的嵌入。例如,在 CLIP 编码的图像之间进行减法并应用本文的方法可以转录两个图像之间的关系。此外,通过对向量求和,可以将生成的标题引向概念方向。
为了在 CLIP 的嵌入空间中执行算术,首先使用 CLIP 的图像/文本编码器对图像/文本进行编码。例如, I1、I2 表示两个图像。使用 CLIP 的编码器对图像进行编码,即 E image ( I 1 ) , E image ( I 2 ) E_{\text {image }}\left(I_{1}\right), E_{\text {image }}\left(I_{2}\right) Eimage (I1),Eimage (I2)。接下来,执行所需的算术,例如,与 E image ( I 1 ) + E image ( I 2 ) E_{\text {image }}\left(I_{1}\right)+E_{\text {image }}\left(I_{2}\right) Eimage (I1)+Eimage (I2) 相加。最后,使用获得的结果代替等式中的图像编码 E image ( I ) E_{\text {image }}(I) Eimage (I)引导生成的句子。
因此,可以通过在概念方向上移动来生成关于外部世界的详细知识。通过这种方式,本文的方法可以回答直观表达的问题,例如,“谁是德国的总统?”为了实现这一点,我们从“奥巴马”的图像中减去“美国国旗”,得到一个总统指示,然后我们可以添加第二个国家的国旗图像。
本文的方法不仅仅是视觉互动。利用CLIP的文本编码器,和自然语言的交互是可能。在本例中,在嵌入空间中执行算术运算,使表达式同时包含图像嵌入和文本嵌入。
4.实验
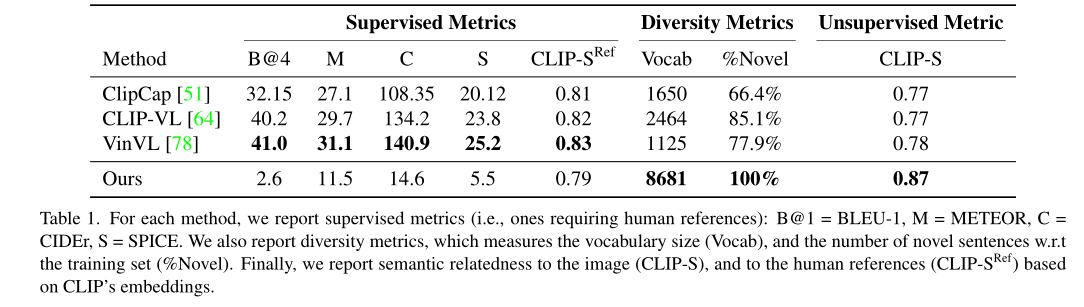
上表展示了Captioning任务上的定量实验结果。

本文方法和其他方法的caption生成结果。

OCR结果。

现实世界知识的例子。

通过从CLIP的嵌入空间中减去表示得到矢量方向的示例。

通过加法运算符对图像进行标题引导的示例。

兼有求和和减法的图像算法。

本文的方法不仅致力于视觉关系,而且它也允许图像和语言之间的算术。
5. 总结
语言模型和视觉语义匹配模型之间的结合是一个强大的结合,有可能提供零样本字幕,将现实世界文本中的可变性结合在一起,不受类别限制的识别能力,以及通过网络规模的数据集嵌入模型的现实世界知识。作者提出了一个零样本的方法来结合两个模型,它不涉及对模型的权重进行优化。相反,作者为所有层和注意头修改由语言模型生成的标记的键值对,直到每个推断步骤。
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading