
论文链接:https://arxiv.org/pdf/2111.12294.pdf
代码链接1:https: //github.com/huawei-noah/CV-Backbones/tree/master/wavemlp_pytorch
代码链接2:https://gitee.com/mindspore/models/tree/master/
research/cv/wave_mlp
1. 问题
最近的计算机视觉领域工作表明,一个主要由全连接层堆叠的纯MLP架构可以实现与CNN和transformer竞争的性能。这些工作通常将视觉MLP的输入图像分割成多个tokens(patches),然后,现有的MLP模型直接将token以固定的权重进行聚合,忽略了不同图像中token的语义信息的变化。
2. 主要贡献
本文提出一个新的视觉MLP架构——Wave-MLP,该架构主要目的是为了动态融合tokens。为了达到目的,将每个token表示为振幅和相位两个部分的波函数。其中,振幅是图像的原始特征(即,每个token内容的实值特征),而相位项是一个根据输入图像的语义内容变化的复杂值(即,调制MLP中token与固定权值之间关系的单位复值)。
3. 方法
类MLP模型是一种主要由全连接层和非线性激活函数组成的神经结构。对于视觉MLP,它首先将图像分割成多个patch(也称为token),然后提取它们的特征,这两个组件分别是channel-FC和token-FC,如下所示。
表示包含 n n n个标记的中间特征 Z = [ z 1 , z 2 , ⋅ ⋅ ⋅ , z n ] Z = [z_1, z_2,···,z_n] Z=[z1,z2,⋅⋅⋅,zn],其中每个标记 z j z_j zj是一个 d d d维向量。channel-FC定义为:
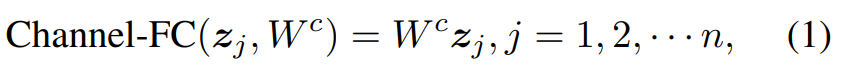
其中 W c W^c Wc是具有可学习参数的权值。channel-FC独立地对每个token进行操作以提取它们的特征。为了增强通道的转换能力,通常将多个channel-FC层与非线性激活函数叠加在一起,构造了一个channelmixing MLP。
为了聚合不同token的信息,需要进行token-FC操作,即:

其中 W t W^t Wt是token混合权值,⊙表示元素乘法,下标 j j j表示第 j j j个输出token。token-FC操作试图通过混合来自不同token的特征来捕获空间信息。在现有的类MLP模型(如MLPMixer、ResMLP)中,token混合MLP也是通过堆叠token-FC层和激活函数来构建的。这种简单的权值固定的token混合MLP忽略了来自不同输入图像的token语义内容的变化,这是限制类MLP体系结构表示能力的瓶颈。
3.1 Phase-Aware Token Mixing
为了在MLP中动态调整token与固定权值之间的关系,从而更恰当地聚合token,作者将每个token视为一个既有振幅又有相位的波。这里首先讨论token的波状表示,然后提出用于聚合token的相位感知token混合模块(PATM)。
-
Wave-like representation
在wave-MLP中,token表示为一个波 z ~ j \tilde{z}_j z~j,具有振幅和相位信息,即
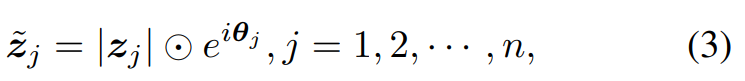
其中 i i i是满足 i 2 = − 1 i^2 = -1 i2=−1的虚单位。 ∣ ⋅ ∣ \left | \cdot \right | ∣⋅∣为绝对值运算,⊙ 是逐元素乘法。振幅 ∣ z j ∣ \left | z_j \right | ∣zj∣是表示每个token内容的实值特征。 e i θ j e^{i \theta_j} eiθj是一个周期函数,其元素总是具有单位范数。 θ j θ_j θj表示相位,是token在一个波周期内的当前位置。同时考虑振幅和相位,每个token z j z_j zj在复值域中表示。
当聚合不同token时,相位项 θ j θ_j θj调制它们的叠加模式。假设 z ~ r = z ~ 1 + z ~ 2 \tilde{z}_r = \tilde{z}_1 + \tilde{z}_2 z~r=z~1+z~2是类波token z ~ 1 , z ~ 2 \tilde{z}_1, \tilde{z}_2 z~1,z~2的聚合结果,其振幅 ∣ z r ∣ \left | z_r \right | ∣zr∣和相位 θ r θ_r θr可计算如下:
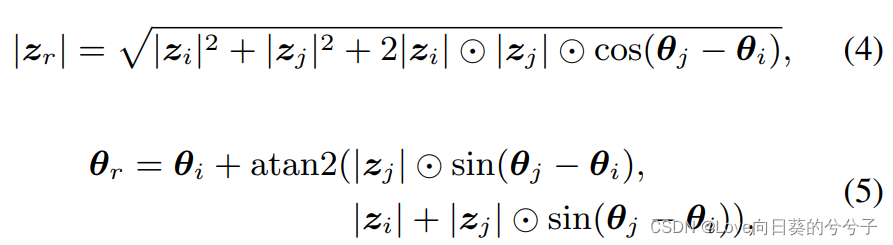
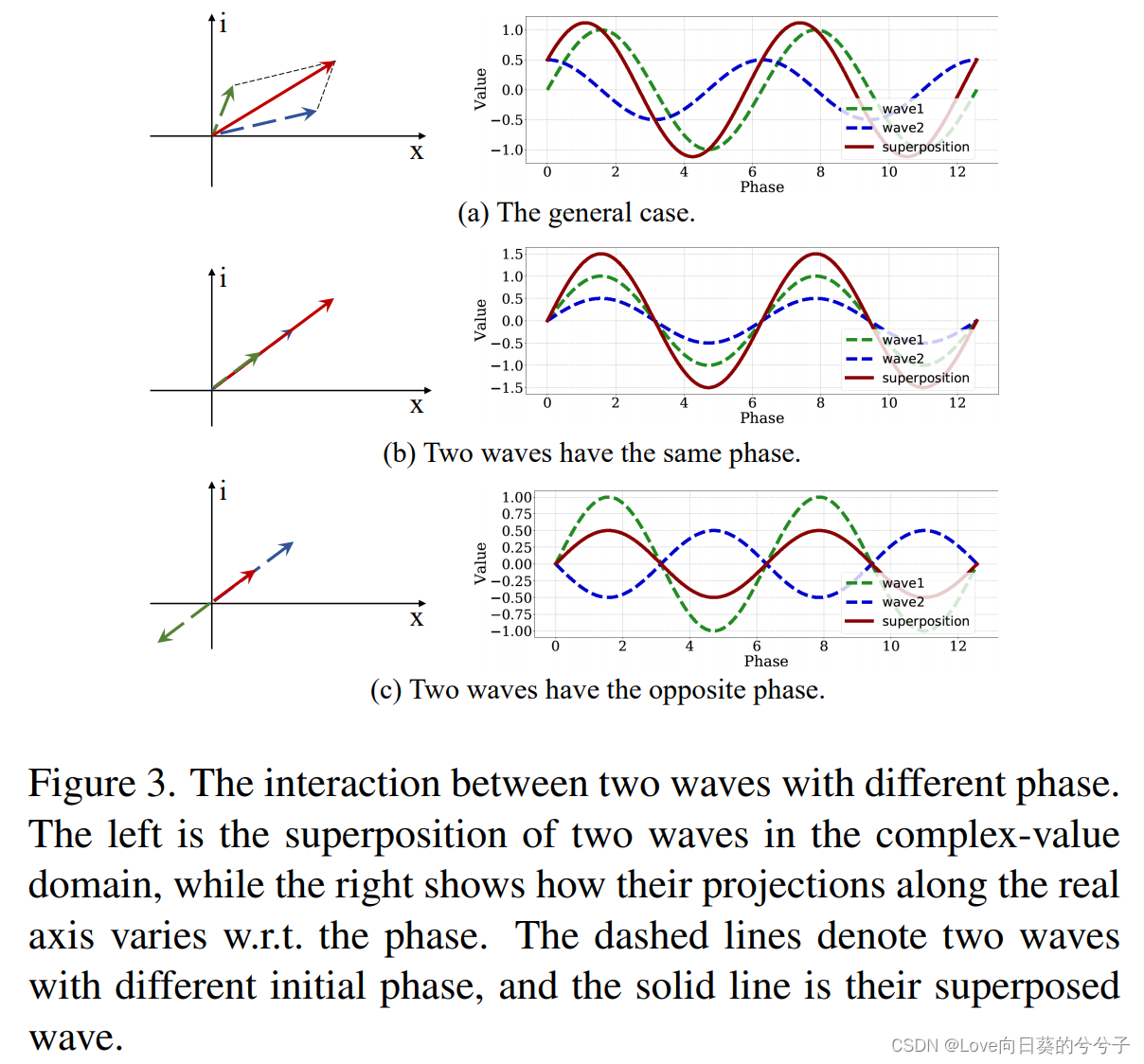
其中 a t a n 2 ( x , y ) atan2(x, y) atan2(x,y)是双参数反正切函数。由上式可知,两个记号之间的相位差 ∣ θ j − θ i ∣ |θ_j - θ_i | ∣θj−θi∣对聚集结果 z r z_r zr的振幅影响较大,如下图3显示了一个直观的图表。左边是两个波在复值域的叠加,而右边显示了它们沿着实轴的投影随相位的变化。当两个token具有相同相位时( θ j = θ i + 2 π ∗ m , m ∈ [ 0 , ± 2 , ± 4 , ⋅ ⋅ ⋅ ] θ_j = θ_i + 2π \ast m, m \in [0, \pm{2}, \pm{4},···] θj=θi+2π∗m,m∈[0,±2,±4,⋅⋅⋅]),它们会相互增强,即 ∣ z r ∣ = ∣ z i ∣ + ∣ z j ∣ |z_r| = |z_i | + |z_j | ∣zr∣=∣zi∣+∣zj∣(图3 (b))。对相反相位( θ j = θ i + π ∗ m , m ∈ [ ± 1 , ± 3 , ⋅ ⋅ ⋅ ] θ_j = θ_i+π \ast m, m \in [\pm{1}, \pm{3},···] θj=θi+π∗m,m∈[±1,±3,⋅⋅⋅]),合成波减弱( ∣ z r ∣ = ∣ ∣ z i ∣ ∣ z j ∣ ∣ |z_r| = ||z_i || z_j || ∣zr∣=∣∣zi∣∣zj∣∣)。在其他情况下,它们的相互作用更为复杂,但它们的增强或减弱也取决于相位差(图3 (a))。注意,只有实值特征的经典表示策略是Eq 3的一种特例,其相位 θ j θ_j θj仅为π的整数倍.
-
振幅
要得到公式(3)中的类波符号,需要振幅和相位信息。除了绝对运算外,振幅 ∣ z i ∣ |z_i| ∣zi∣与传统模型中的实值特征相似。实际上,element-wisely的绝对运算可以被吸收到相项中,即 如 果 z j , t > 0 如果z_{j,t}>0 如果zj,t>0,则 ∣ z j , t ∣ e i θ j , t = z j , t e i θ j , t |z_{j,t}|e^{iθ_{j,t}} = z_{j,t}e^{iθ_{j,t}} ∣zj,t∣eiθj,t=zj,teiθj,t;否则, ∣ z j , t ∣ e i θ j , t = z j , t e i ( θ j , t + π ) |z_{j,t}|e^{iθ_{j,t}} = z_{j,t}e^{i(θ_{j,t}+π)} ∣zj,t∣eiθj,t=zj,tei(θj,t+π)。其中 z j , t z_{j,t} zj,t和 θ j , t θ_{j,t} θj,t表示 z j z_j zj和 θ j θ_j θj中的第 t t t个元素。因此,为了简单起见,我们在实际实现中去掉了绝对操作,表示 X = [ x 1 , x 2 , … , x n ] X = [x_1, x_2,…, x_n] X=[x1,x2,…,xn]作为一个块的输入,我们通过一个plain channel-FC操作得到token的振幅 z j z_j zj,即
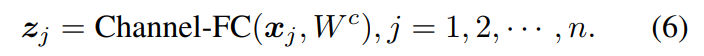
-
相位
回顾相位表示token在一波周期内的当前位置,作者讨论了不同的生成相位的策略如下:最简单的策略(“静态相位”)是用固定参数表示每个token的相位 θ j θ_j θj,可以在训练中学习的过程。静态相位虽然可以区分不同的token,但也忽略了不同输入图像的多样性.
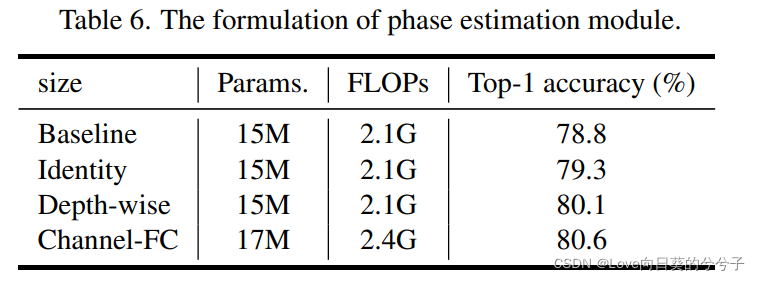
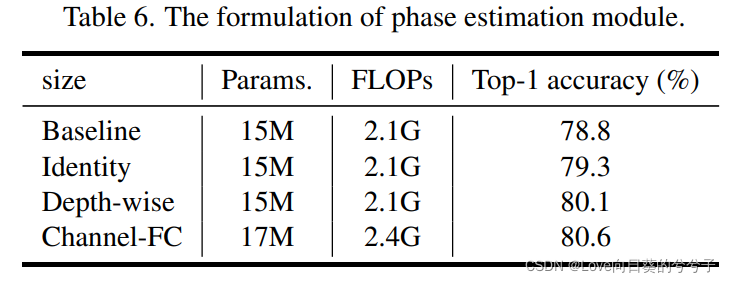
为了分别捕获每个输入的特定属性,我们使用一个估计模块 Θ Θ Θ根据输入特征 x j x_j xj生成相位信息,即 θ j = Θ ( x j , W θ ) θ_j = Θ(x_j, W^θ) θj=Θ(xj,Wθ),其中 W θ W^θ Wθ为可学参数。考虑到简单性是类似mlp的体系结构的一个重要特征,复杂的操作是不可取的。因此,作者也采用Eq. 1中的简单channel-FC作为相位估计模块。估计模块也可以用其他公式构建,其对模型性能的影响如下表6中进行了实证研究。
-
Token融合
在公式3中,类波符号在复域中表示。为了将其嵌入到一般的类mlp体系结构中,作者用欧拉公式展开它,并用实部和虚部表示它:
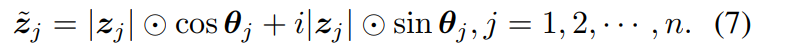
在上式中,复值token表示为两个实值向量,分别表示实部和虚部。不同的令牌 z ~ j \tilde{z}_j z~j,然后通过token-fc操作(式2)进行聚合,即:
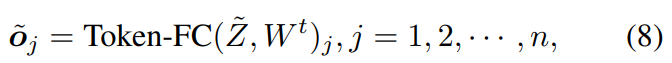
其中 Z ~ = [ z ~ 1 , z ~ 2 , ⋅ ⋅ ⋅ , z ~ n ] \tilde{Z} = [\tilde{z}_1, \tilde{z}_2,···,\tilde{z}_n] Z~=[z~1,z~2,⋅⋅⋅,z~n]表示一层中所有的波状符号。在式8中,考虑到振幅和相位信息,不同的token相互作用。输出的 o ~ j \tilde{o}_j o~j是聚合的特征的复数值表示。按照常用的量子测量方法,将一个具有复值表示的量子状态投射到实值可观测值上,我们通过将 o ~ j \tilde{o}_j o~j的实部和虚部与权值相加得到实值输出 o j o_j oj。结合式8,可以得到输出 o j o_j oj为:

其中 W t W^t Wt和 W i W^i Wi都是可学权值。在上式中,相位 θ k θ_k θk根据输入数据的语义内容进行动态调整。除了固定的权值外,相位还调节不同符号的聚合过程。
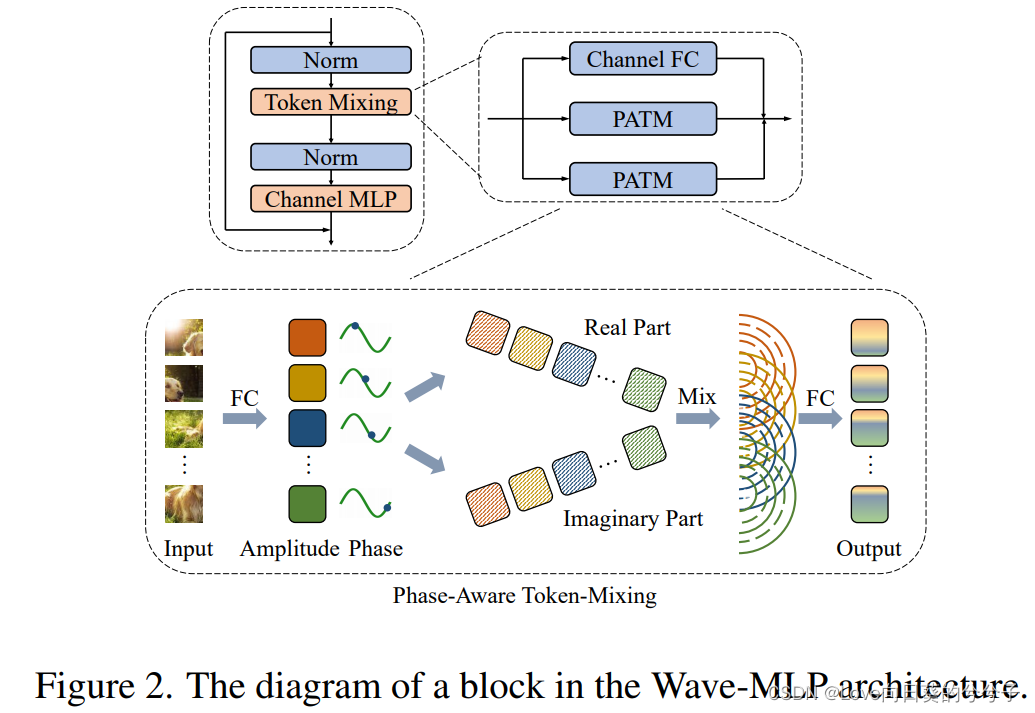
在视觉MLP中,我们构造了一个相位感知token混合模块(PATM)来执行上述token聚合过程,如图2所示,在给定输入特征 x j x_j xj的情况下,通过channel-FC和相位估计模块分别产生幅值 z j z_j zj和相位 θ j θ_j θj。然后利用Eq. 7展开类波token z ~ j \tilde{z}_j z~j并聚合得到输出特征 o j o_j oj (Eq. 9),通过将 o j o_j oj与另一个channel-FC进行变换得到最终的模块输出,以增强表示能力。
3.2 Wave-MLP Block
在提出的Wave-MLP中,一个基本单元主要包含两个块,channel-mixing MLP和phase-aware tokenmixing block(如上图2)。channel-mixing MLP由两个channel-FC层(Eq. 1)和非线性激活函数叠加,它们提取每个token的特征。token混合块由所提出的PATM模块组成,通过考虑振幅和相位信息来聚合不同的token.
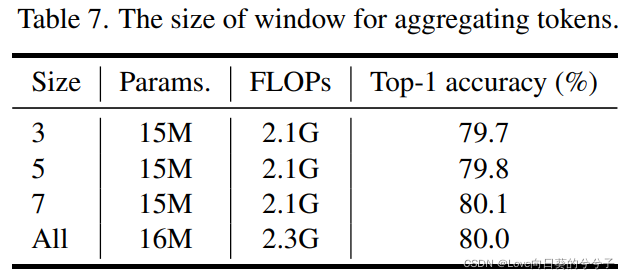
为了更好地兼容计算机视觉任务,作者采用形状为 H × W × C H \times W \times C H×W×C的特征映射来保持输入图像的二维空间形状, H 、 W 、 C H、W、C H、W、C分别为高度、宽度和通道数。这是一个成功的实践,在最近的视觉transoformer架构中被广泛使用(如,PVT, Swin-Transformer)。有两个并行的PATM模块,它们分别沿高维和宽维聚合空间信息。类似于Cycle-MLP,不同的分支用一个重加权模块求和。在传统的MLP-Mixer中,每个token-FC层将所有token连接在一起,其尺寸取决于特定的输入大小。因此,它不适合输入图像大小不同的密集预测任务(如目标检测和语义分割)。为了解决这个问题,作者使用一个简单的策略来限制FC层只连接本地窗口中的token。窗口大小的实证研究如下表7所示。除了PATM模块外,还使用另一个直接连接输入输出的channel-FC来保存原始信息。块的最终输出是这三个分支的总和。
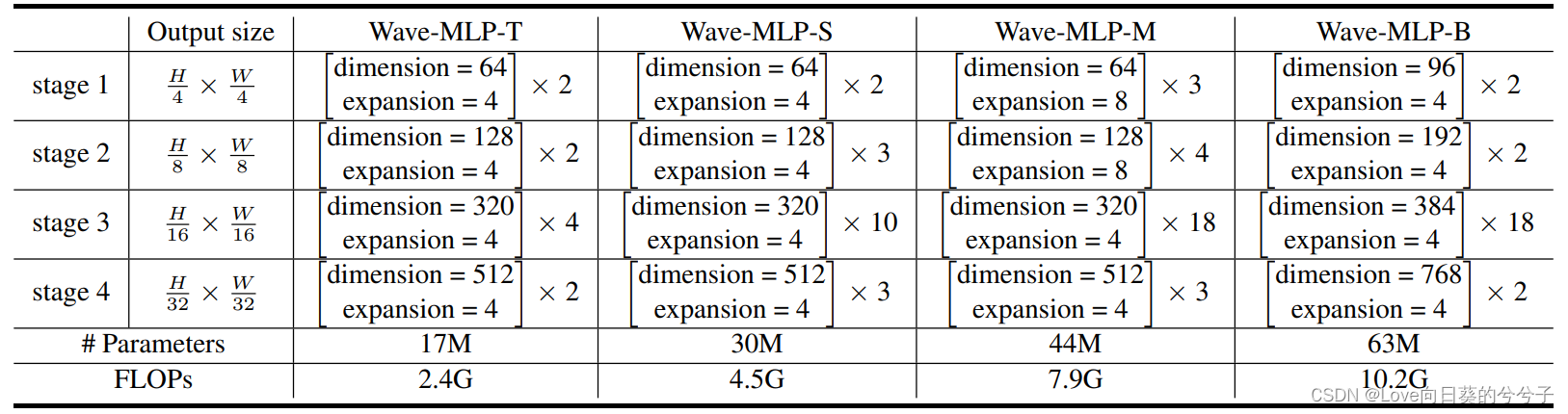
整个模型由相位感知token混合块、通道混合MLPs和归一化层交替叠加而成。为了生成分层特征,作者将体系结构分为4个阶段,这就减少了特征图的大小,并逐步增加了通道的数量。通过改变模型的宽度和深度,本文开发了4个具有不同参数和计算代价的模型,依次表示为Wave-MLP-T, Wave-MLP-S, WaveMLP-M, Wave-MLP-B,这些模型的详细配置如下所示:
4. 部分实验结果
4.1 ImageNet图像分类结果
- 与SOTA的MLP-like框架性能对比
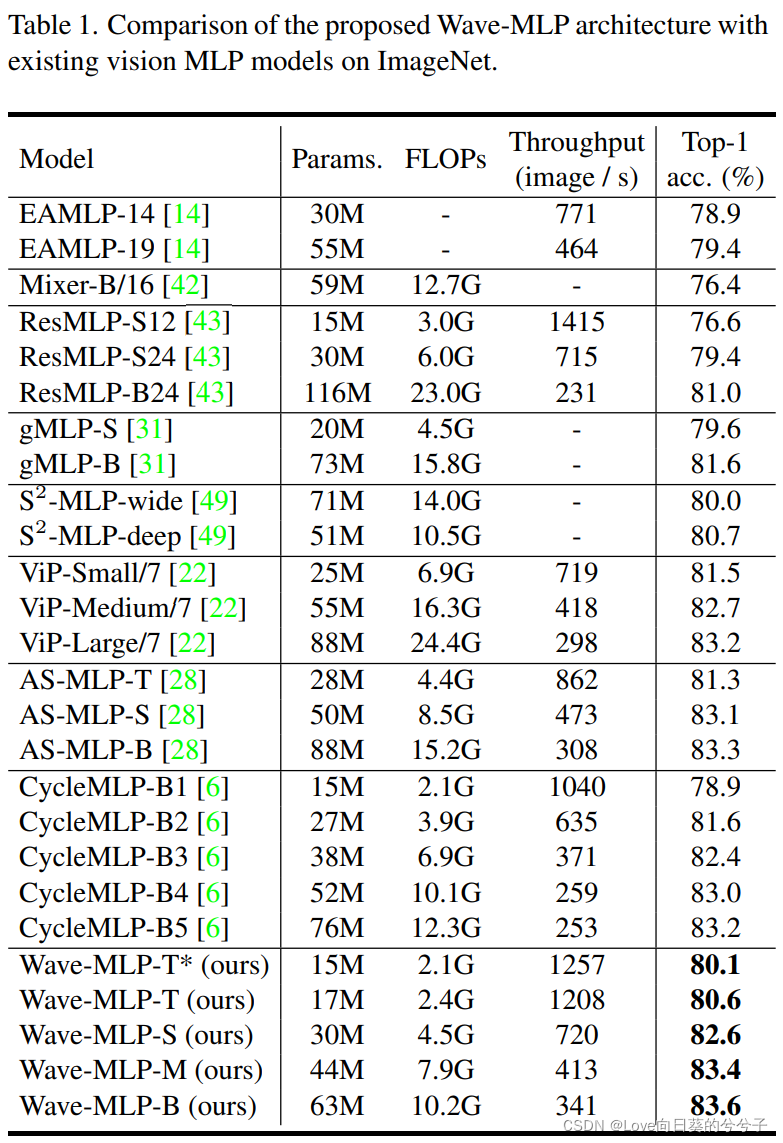
1)与现有的算法相比,Wave-MLP模型系列在计算成本和精度之间取得了更好的平衡
2)结果表明,为每个token配置相位信息可以很好地捕捉到不同token与固定权值之间的关系,从而提高MLP体系结构的性能
- 与SOTA的方法性能对比
Wave-MLP-S 在计算成本和准确性之间的权衡也媲美典型的CNN架构,如RegNetY和ResNet18。Wave-MLP的优越性表明,简单的MLP结构具有很大的潜力,通过调制具有相位项的token聚合过程可以充分利用它。
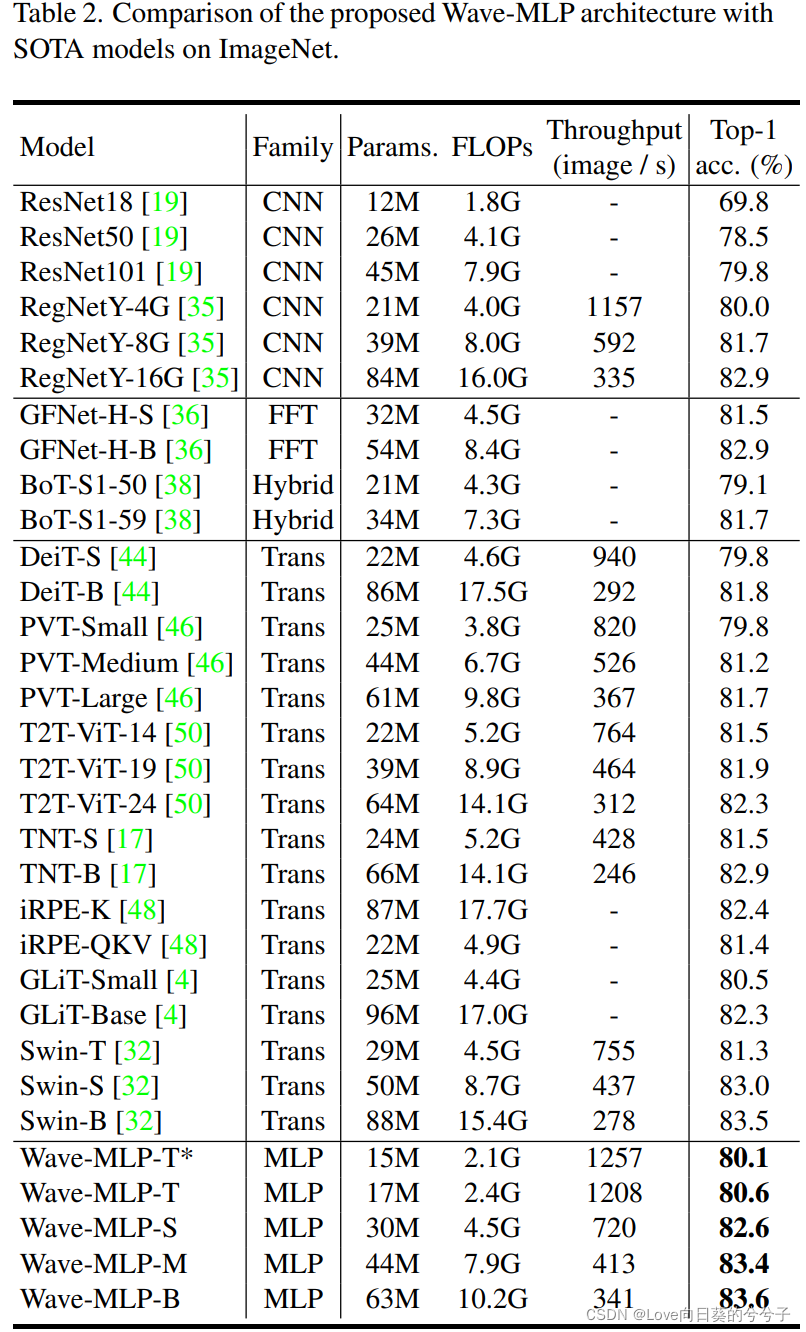
4.2 COCO目标检测结果
Wave-MLP-S以更少的参数和更低的计算成本实现了更高的性能!!!
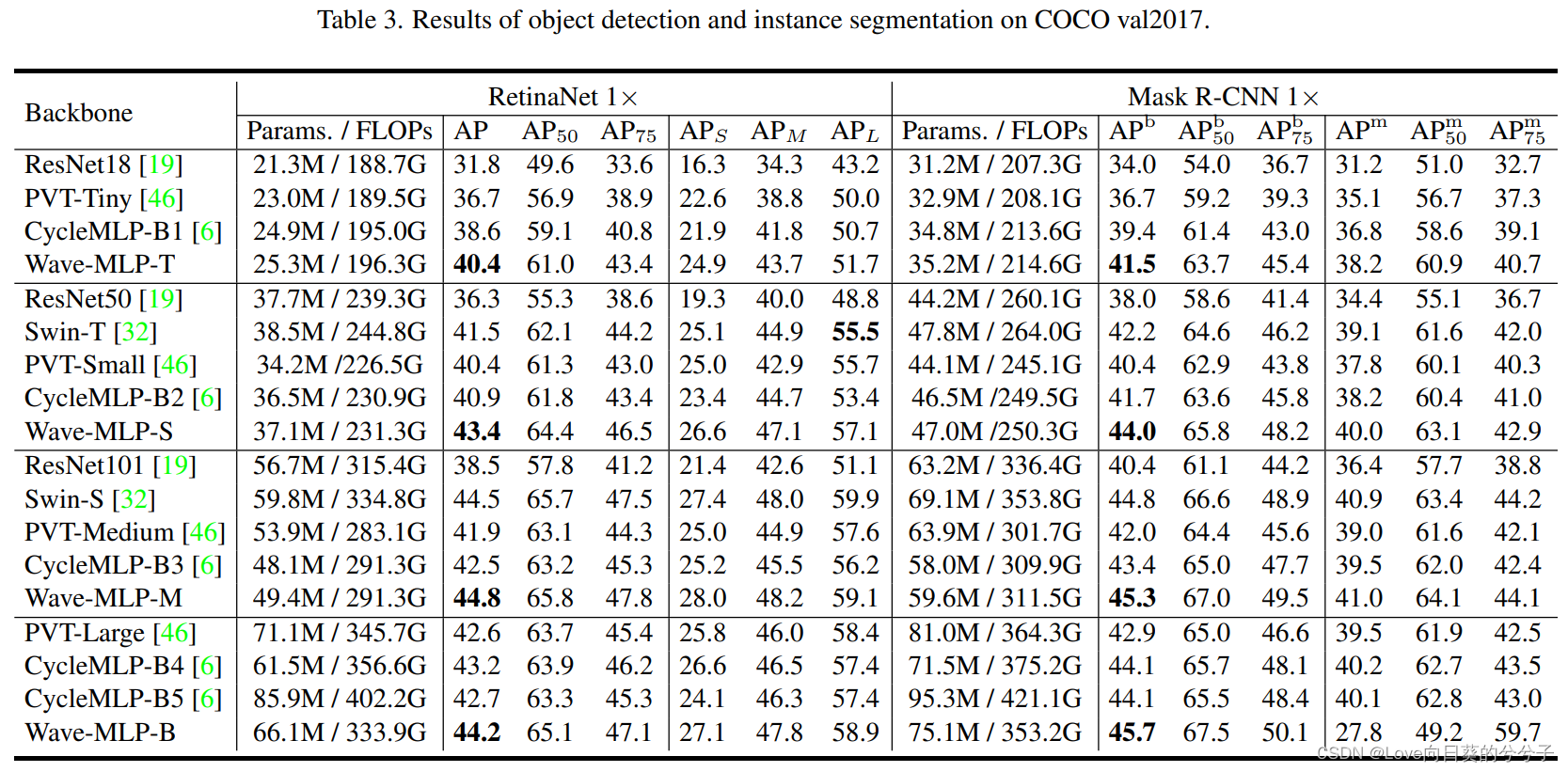
4.3 ADE20K语义分割结果
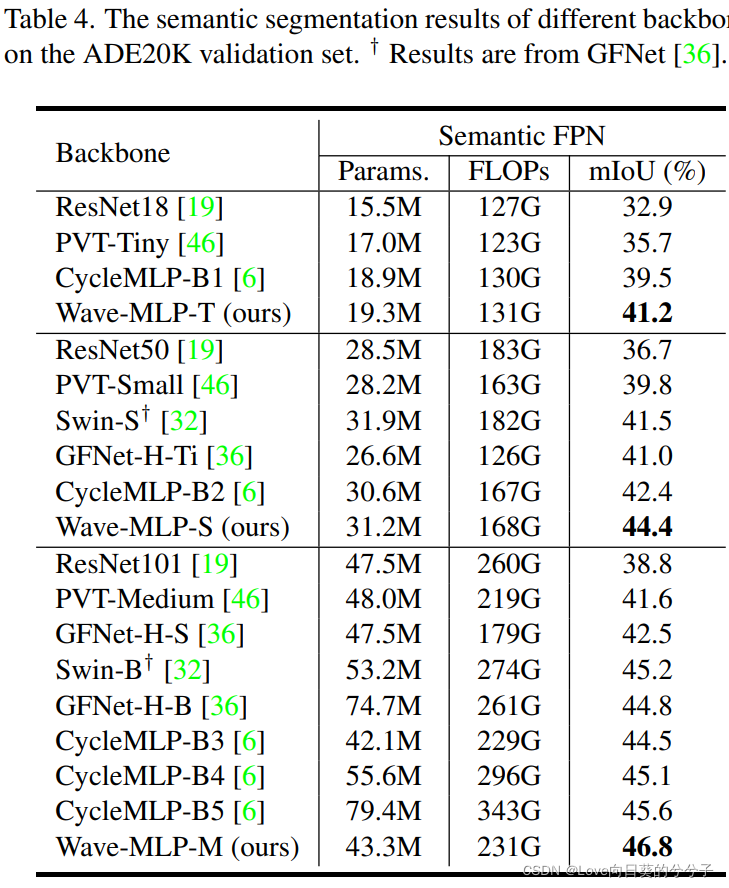
4.4 消融实验
- 相位信息的有效性
如下表5所示,在没有相位信息(No phase)的情况下,模型的性能明显低于其他模型,top1精度仅为78.8%。所提出的动态相位可以针对每个输入实例灵活地生成阶段和调整聚合过程,从而获得了更好的性能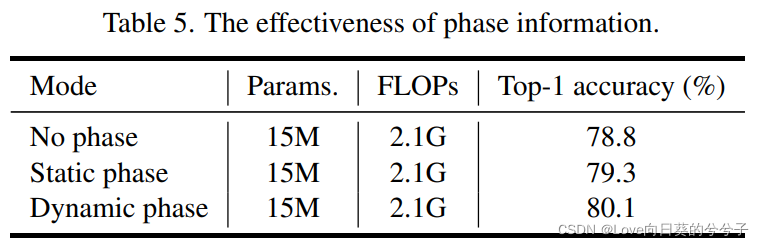
- 相位估计模块的形式
相位估计模块为不同的输入生成相位,可以用不同的公式来实现。本文研究三个简单的公式:深度卷积,通道FC和恒等映射。
1)恒等映射直接复制输入特征,而不是估计相位,导致较差的性能。
2)与基线相比,深度卷积和通道FC可以实现较高的精度提高,这意味着它们可以很好地捕获相位信息来聚合token。使用通道FC比深度卷积获得更高的性能,但也略微增加了计算开销
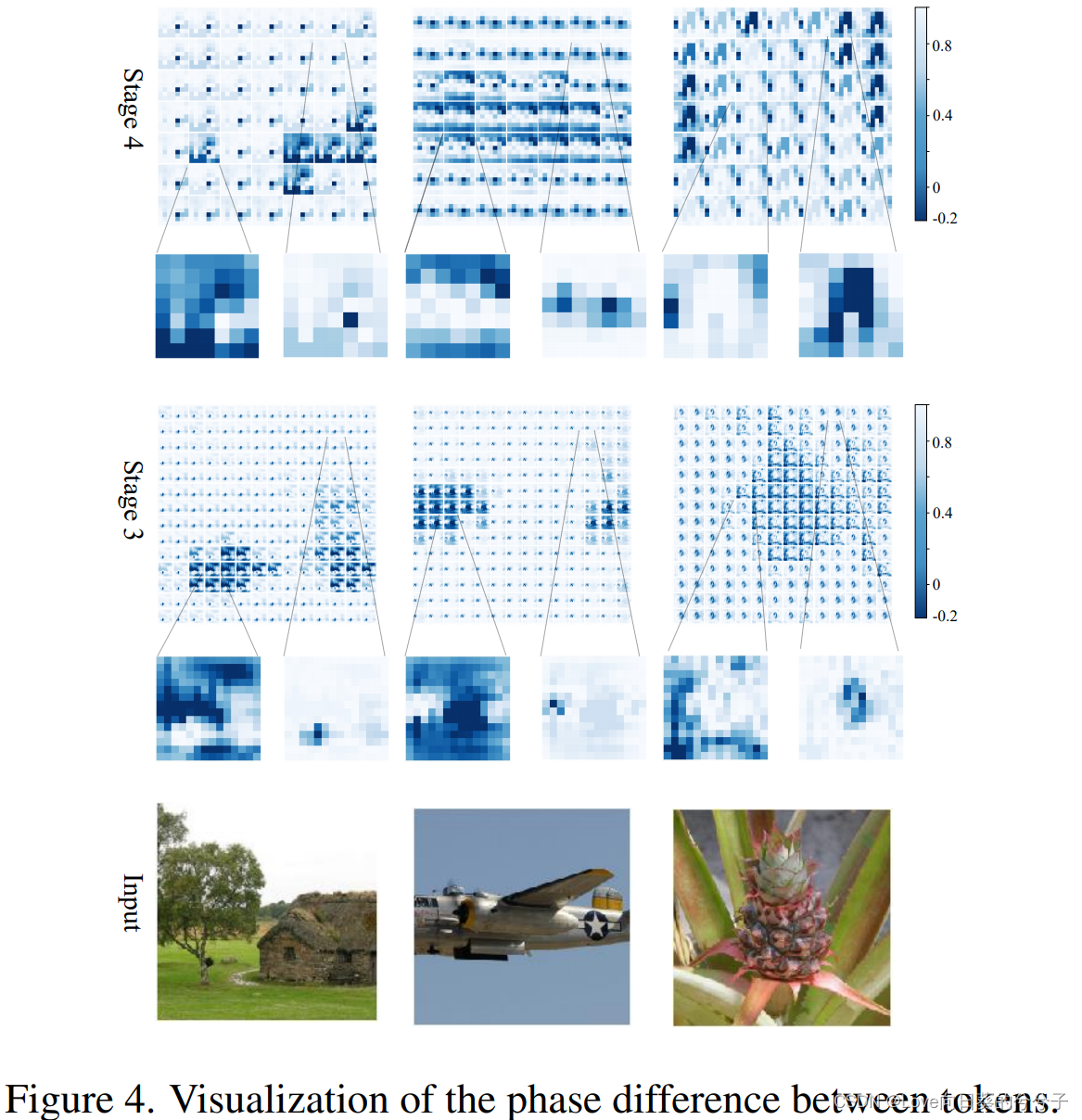
4.5 可视化
两个token( ∣ θ j − θ i ∣ |θ_j - θ_i | ∣θj−θi∣)的相位差直接影响上文中公式4、5中分析的聚集过程。为了直观理解,作者在下图4中将第三、第四阶段的相位差余弦值表示了出来。从图中可以看到,内容相似的token往往具有相近的阶段,然后相互增强。例如,在第一张图片中,描述房子的token与房子的另一个token的相位比天空的相位更近(图中放大的部分)。不同token的相位差也会随图像内容的不同而不同
5. 结论
本文提出了一种用于视觉任务的wave-mlp体系结构,该体系结构将每个token视为具有振幅和相位信息的波。在MLP中,振幅是原始的实值特征,相位调制是变化的符号与固定权值之间的关系。在动态生成阶段,根据来自不同输入图像的token的不同内容聚合token。大量实验表明,所提出的Wave-MLP抑制了现有的类mlp架构,也可以用作密集预测任务(如对象检测和语义分割)的强大骨干。