An End-to-End Multitask Learning Transformer
论文:https://arxiv.org/pdf/2205.08303.pdf
code:https://github.com/IVRL/MulT
project: https://ivrl.github.io/MulT/

1.摘要
该文提出了一个端到端的多任务学习transformer框架,即 MulT,该框架可以同时学习对各高级视觉任务,包括深度估计,语义分割,reshading重着色,表面法线估计,2D关键点检测和边缘检测。基于swin-transformer模型,我们的框架将图像编码为共享表示,并使用基于特定任务的transformer解码器头对每个视觉任务进行预测。方法的核心是通过共享注意力机制对任务间的依赖关系进行建模。
通过在几个多任务基准上评估,本文提出的MulT的性能优于现有最先进的多任务卷积神经网络模型和所有各自的单任务transformer模型。
本章的实验进一步强调了在所有任务中共享注意力的好处,并证明MulT模型是稳健的,并且可以很好地泛化到新领域。
2.网络结构

如上图,Mult 模型基于swin-transformer backbone(绿色部分),通过共享注意力机制(左下蓝色部分)对任务间的依赖关系进行建模。首先图像经encoder 编码模块(绿色部分)嵌入一个共享表示,然后通过transformer decoder解码模块(右端蓝色部分)对各个独立的任务进行解码。注意:transformer decoders具有相同的结构但接的是不同的任务头。整个模型通过监督方式采用各个任务的加权损失联合训练。
3.共享注意力机制

为了说明任务间的依赖是在共享编码参数之外,我们设计了共享注意力机制,融合编码特征到解码流中。接下来通过一个特定的解码阶段来说明这个共享注意力机制是如何起作用的。注意在所有的解码阶段该注意力流程都有参与。
对于任务t和特定的解码阶段, 表示为前一阶段的上采样输出,
是同一分辨率下encode 阶段的输出。然后decoder将
和
作为输入。标准方式来计算task t 自注意力是仅从decoder的输出
获得key,query和value 向量。
i而共享注意力,我们只利用一个任务流来计算注意力,也即,我们利用特定推理任务的解码器的linear layers 从来自于encoder的
计算一个query
和key
,尽管如此,为了反映解码器的输出任务t应与此特定任务相关,我们计算value
利用前一阶段任务t的输出
。因此,我们计算从推理任务r 计算attention values :
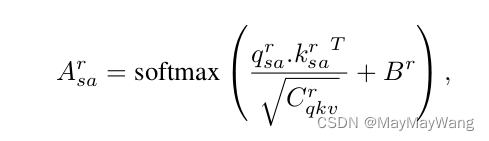
式中 是通道数,
是偏置。对于任务t,我们计算
=
。这里
后面被自注意力头
用来计算
,这里
是任务t学习到的注意力权重,
是第 i 通道。
注意这个方程表示自注意力的第i个实例,重复M次获得任务t的交叉注意力,根据这个我们计算
通过线性投影
输出,最后计算
如下:

这里W表示多头注意力权重。从经验上看,我们发现注意力来自表面法向量的任务流有利于我们6任务的MulT模型,因此我们将该任务作为参考任务r,其注意力是跨任务共享。如上图所示,表示为前一阶段参考任务的特定编码器的上采样输出,此处作为曲面法线预测。
4.任务头和损失函数
来自transformer解码器模块的特征map被输入到不同的特定任务头,以进行后续预测。每个任务头包括一个线性层,以输出一个H×W×1的,map,其中H、W是输入图像尺寸。我们采用基于加权和的任务特定损失来联合训练网络,其中损失在每个任务的groundtruth和最终预测之间计算。对于分割,旋转,深度任务我们使用交叉熵损失,对于表面法线,2D关键点,2D边和重着色任务使用L1损失。另外,使用这些损失来保持与基线的一致性。
5.数据集
使用以下数据集评估MulT:
Taskonomy被用作我们的主要训练数据集。它包含400万幅真实的室内场景图像,每个图像的多任务注释。实验使用以下6项任务执行:语义分割(S)、深度(zbuffer)(D)、表面法线(N),2D关键点(K)、2D(Sobel)纹理边(E)和重着色(R)。选择的任务包括2D、3D和语义域,具有基于传感器/语义基础的GT。
Replica 包含1227张图像,高分辨率3D地面实况并且能够对细粒度进行更可靠的评估细节。我们在副本图像上测试了所有网络。
NYU包含1449 张来自464个不同的室内场景。
CocoDoom包含来自《末日》视频游戏的合成图像。我们将其用作未经训练的分布数据集。
6 测试效果
