一、简介
之前从没接触过多模态方向,这次和在字节的师兄一起参加了一个VQA相关的比赛,发现基于图像-文本的预训练是一个很火热的领域,比如BLIP,LAVT等。在此基础上,针对VQA Grounding任务不光需要回答问题、还需要进行视觉分割的特点设计了一种双流的视觉-语言交互方法,最终在CVPR2022的VizWiz VQA Grounding赛道取得了第一名的成绩,详细介绍链接如下:
Video:ByteDance&Tianjin University --- Aurora
论文链接: Tell Me the Evidence? Dual Visual-Linguistic Interaction for Answer Grounding
二、比赛介绍
「视觉问答」是通向多模人工智能的一项基础挑战。
一个自然的应用就是帮助视障人群克服他们日常生活中的视觉挑战,如视障群体通过手机镜头捕获视觉内容,再通过语言对镜头中的内容发起提问。AI算法需要识别和描述物体或场景,并以自然语言的方式进行回答。
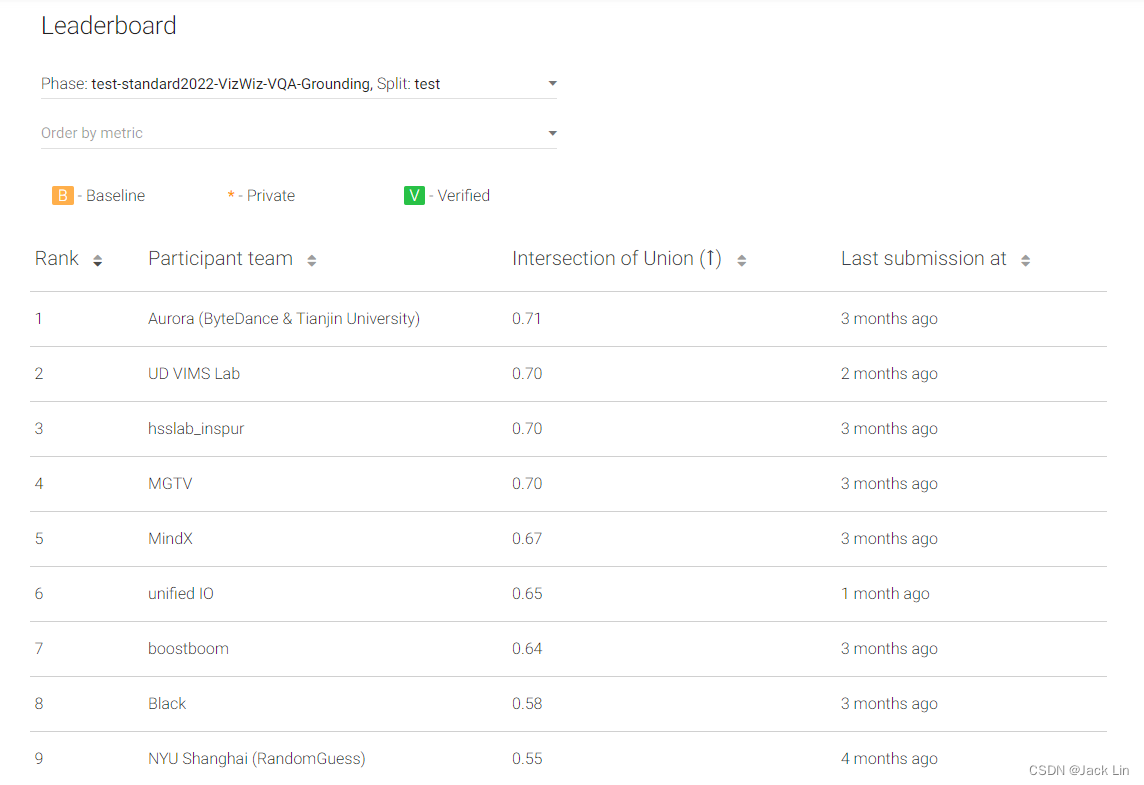
在CVPR 2022上,权威视觉问答竞赛VizWiz提出了新的挑战:AI在回答(Talk)有关的视觉问题时,必须精确地高亮出(Show)相应的视觉证据。

凭借端到端的DaVI(Dual Visual-Linguistic Interaction)视觉语言交互新范式,Aurora团队成功拿下VizWiz 2022 Answer Grounding竞赛的第1名。
本届竞赛中,Aurora与来自国内外知名研究机构和高校的60+团队同台竞技,包括Google DeepMind、纽约大学、浪潮国家重点实验室、西安电子科技大学和特拉华大学等。
夺冠方案的精度相比基线算法提升43.14%,领先在多模领域深耕已久的DeepMind团队3.65%。
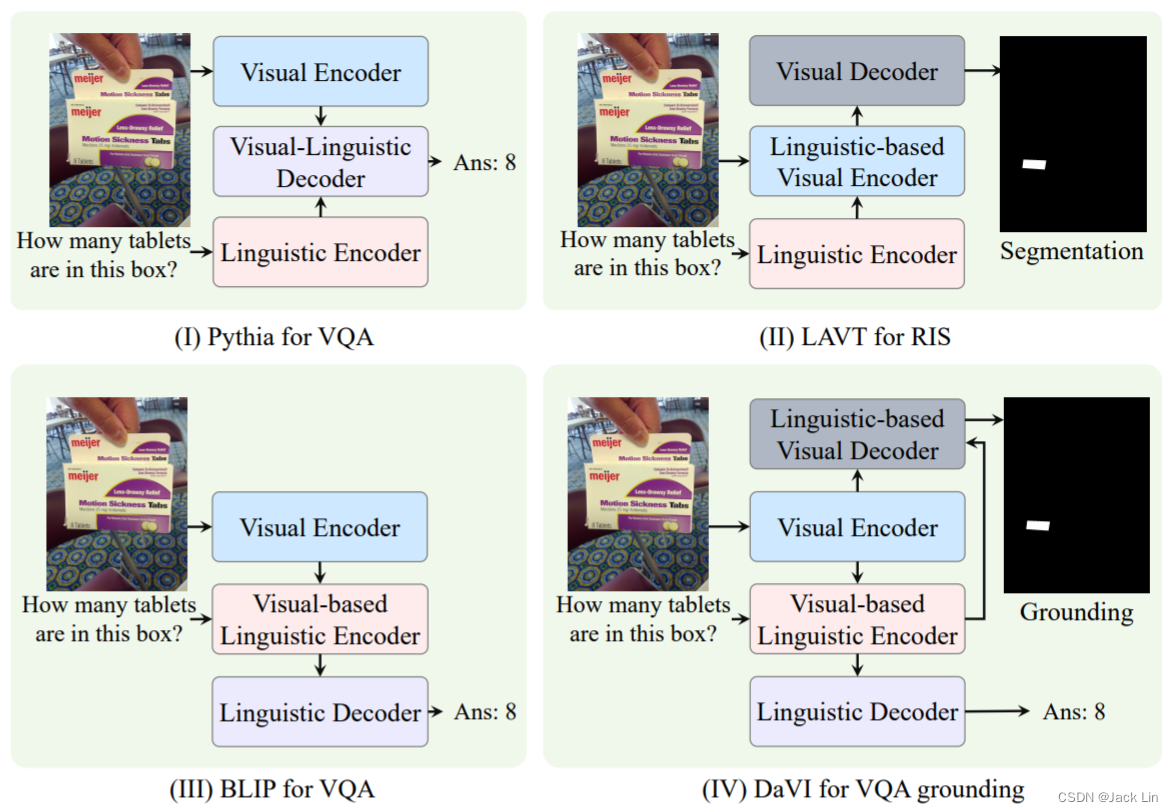
三、DaVI Framework
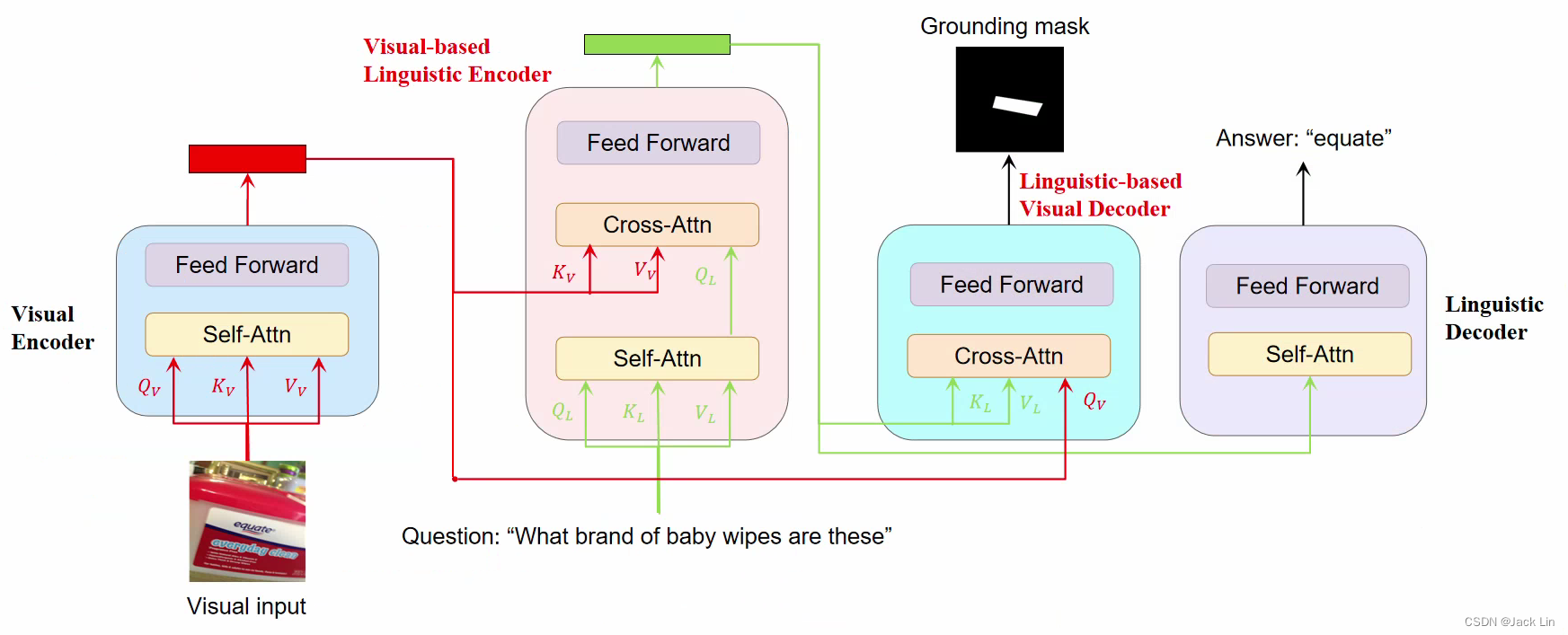
VLE: (Visual-based Linguistic Encoder) understands questions incorporated with visual features and produces linguistic-oriented evidence for answer decoding.
LVD: (Linguistic-based Visual Decoder) focuses visual features on the evidence-related regions for answer grounding.
四、结果