
论文链接:https://arxiv.org/pdf/2201.03545.pdf
代码链接:https://github.com/facebookresearch/ConvNeXt
摘要:
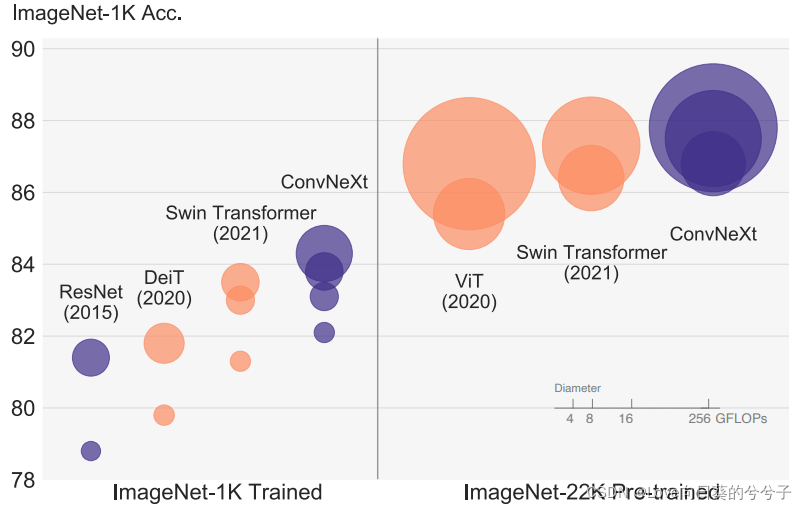
ViT伴随着视觉的“20年代”咆哮而来,迅速的碾压了ConvNet成为主流的研究方向。然而,当应用于广义CV任务(如目标检测、语义分割)时,常规的ViT面临着极大挑战。因此,分层Transformer(如Swin Transformer)重新引入了ConvNet先验信息,使得Transformer成实际可行的骨干网络并在不同视觉任务上取得了非凡的性能。然而,这种混合方法的有效性仍然很大程度上归根于Transformer的内在优越性,而非卷积固有归纳偏置。
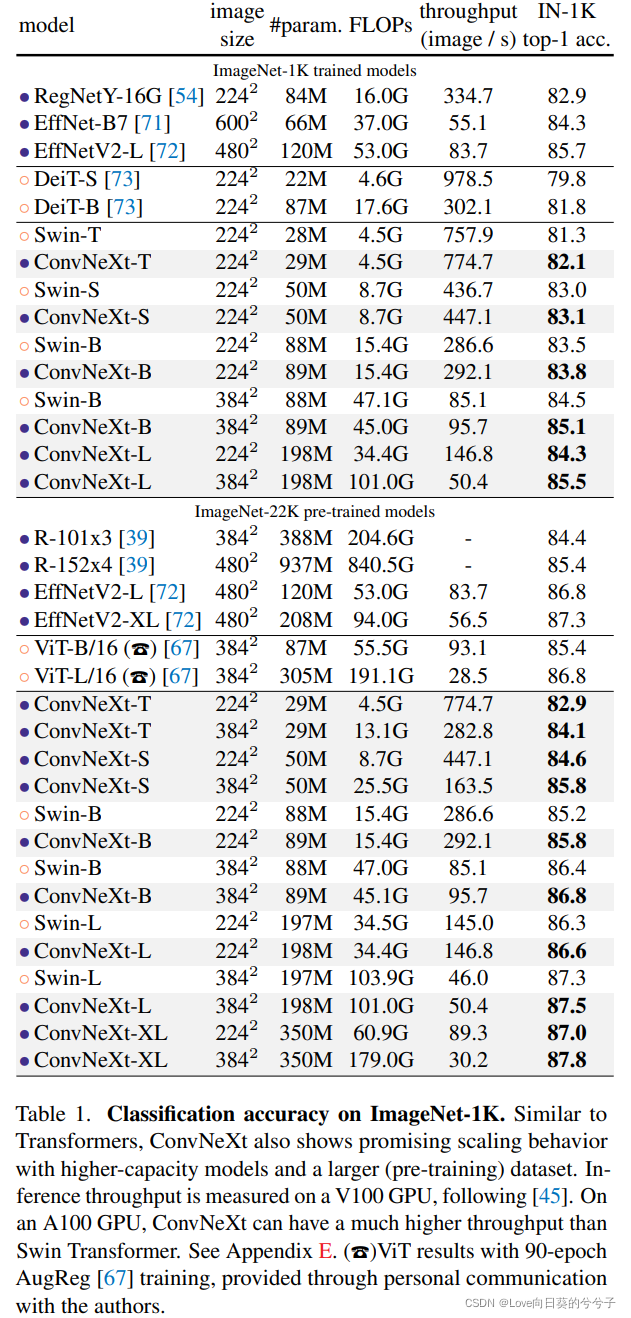
本文对该设计空间进行了重新审视并测试了ConvNet所能达到的极限。我们将标准卷积朝ViT的设计方向进行逐步“现代化”调整,并发现了几种影响性能的关键成分。由于该探索是纯ConvNet架构,故将其称之为ConvNeXt。完全标准ConvNet模块构建的ConvNeXt取得了优于Transformer的精度87.8%,在COCO检测与ADE20K分割任务上超越了SwinTransformer,同时保持了ConvNet的简单性与高效性。
更多讲解可参见(非常详细哟(^U^)ノ):“文艺复兴” ConvNet卷土重来,压过Transformer!FAIR重新设计纯卷积新架构