大家好,我是阿潘 
之前 ”蚂蚁呀嘿“ 的算法 火的不行。今年的CVPR 2022 ,又有一个新算法,效果更加炸裂!相比之前,现在对于动漫头像的驱动效果也可以做到非常的逼真!
按照惯例,先看效果视频:
论文:Depth-Aware Generative Adversarial Network for Talking Head Video Generation
资料汇总:
https://arxiv.org/pdf/2203.06605.pdf https://github.com/harlanhong/CVPR2022-DaGAN https://harlanhong.github.io/publications/dagan.html
摘要
talking head 视频生成旨在生成合成人脸视频,其中包含分别来自给定源图像和驱动视频的身份和姿势信息。这项任务的现有工作严重依赖从输入图像中学习的 2D 表示(例如外观和运动)。然而,密集的 3D 面部几何(例如像素深度)对于这项任务非常重要,因为它对我们从本质上生成准确的 3D 面部结构并将噪声信息与可能杂乱的背景区分开来特别有益。然而,密集的 3D 几何标注对于视频来说成本高得令人望而却步,并且通常不适用于此视频生成任务。在本文中,我们首先介绍了一种自监督几何学习方法,可以自动从人脸视频中恢复密集的 3D 几何(即深度),而不需要任何昂贵的 3D 标注数据。基于学习到的密集深度图,我们进一步建议利用它们来估计捕捉人头关键运动的稀疏面部关键点。以更密集的方式,深度还用于学习 3D 感知的跨模态(即外观和深度)注意力,以指导生成运动场以扭曲源图像表示。所有这些贡献构成了一个新颖的深度感知生成对抗网络(DaGAN),用于talking head 生成。进行的大量实验表明,我们提出的方法可以生成高度逼真的人脸,并在看不见的人脸上取得显着效果
Talking Head Generation 是什么
Talking Head Generation 的目的是合成一个人脸视频,这个合成视频的身份和姿态信息分别来源一个给定的source图片和驱动视频
相关方法
Xface
FOMM(目前最流行的方法,之前爆火)
Face-vid2vid 等等
主要挑战
1、现有的工作严重依赖于 2D 表征
2、现有方法确实人脸细节
3、3D 几何标注不可用
然而密集的 3D 面部几何结构对于这项人物非常重要,因为它对我们生成准确的3D面部结果特别又帮助。密集的 3D 几何标注对于视频来说成本很高,并且通常不适用于此视频生成任务。
主要贡献:
1、引入自监督学习方法来从面部视频中恢复显式密集 3D 几何以生成说话头视频的方法
2、提出了一个与深度图合作的框架来解决说话头的生成问题
3、与现有方法相比,我们的方法可以产生更好的结果
模型框架
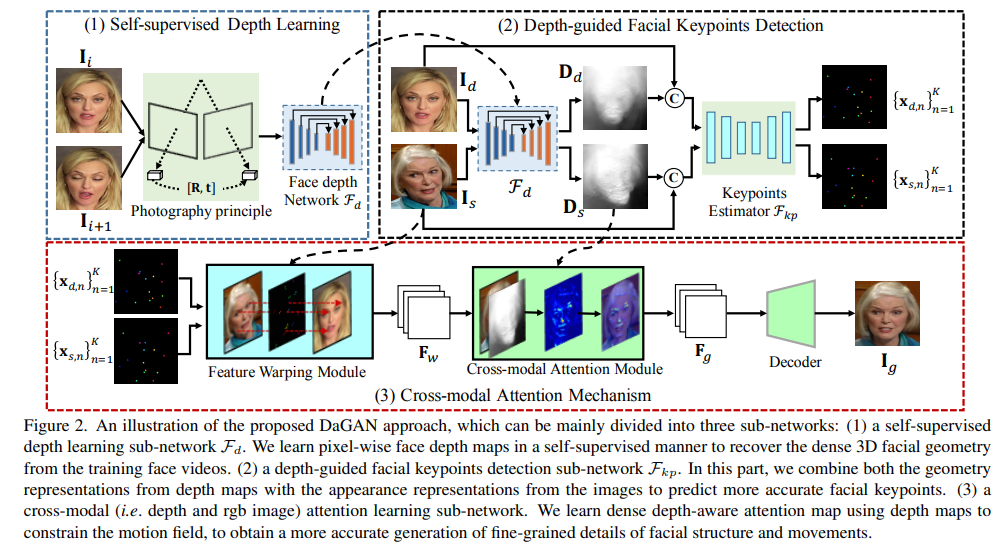
我们首先引入了一种自监督的几何学习方法,可以自动从人脸视频中恢复密集的 3D 几何,而不需要任何昂贵的 3D 标注数据。
基于学习到的密集深度图,进一步使用深度图来估计稀疏的面部关键点,以捕捉人体头部的关键运动。以更密集的方式,深度还用于学习 3D 感知的跨模态注意力以改进生成结果。
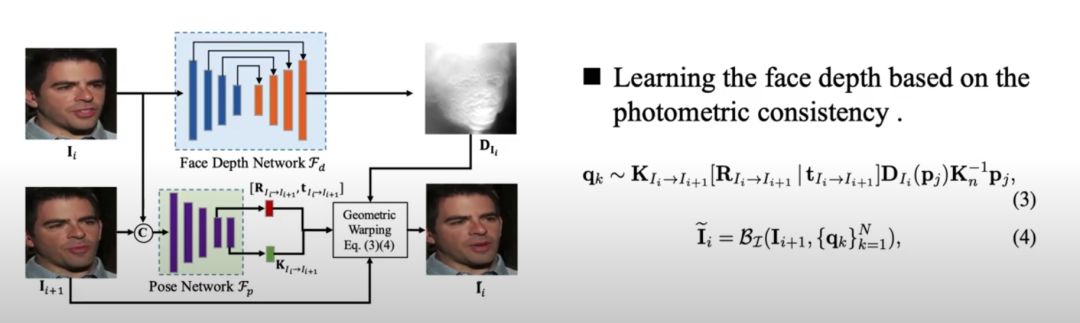
在自监督人脸深度学习模块中,我们使用估计的深度图、源视图和相机矩阵通过公式 3 重构目标视图。
因此,我们可以通过重构损失学习一个满意的人脸深度网络。
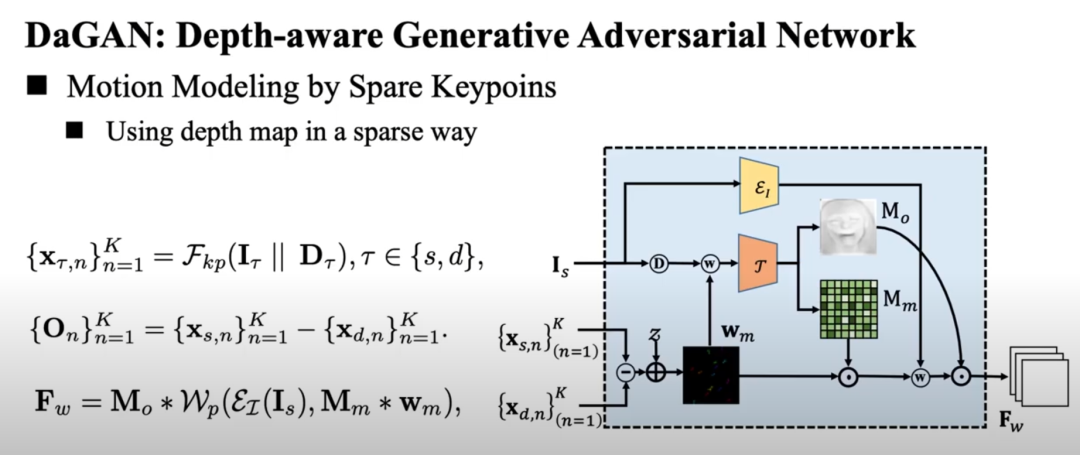
从人脸深度网络获得深度图后,我们采用特征扭曲策略来捕捉源图像和目标图像之间的头部运动。
重要的是,在这个模块中预测了一个运动流掩码和一个遮挡图。运动流掩码为估计的密集 2D 运动场分配不同的置信度值,而遮挡图旨在掩盖由于头部旋转变化而应修复的特征图区域,有效嵌入学习的深度图 ,以更密集的方式促进生成。。
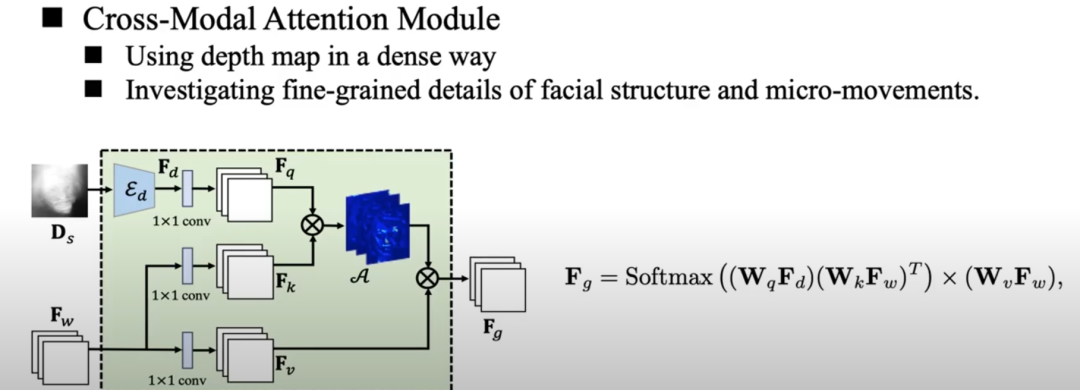
我们提出了一种跨模态注意机制,使模型能够更好地保留面部结构并生成与表情相关的微面部运动,因为深度可以为我们提供密集的 3D 几何,这对于保持 面部结构和识别关键动作我们首先展示了从所提出的面部深度网络中恢复的人脸深度图。
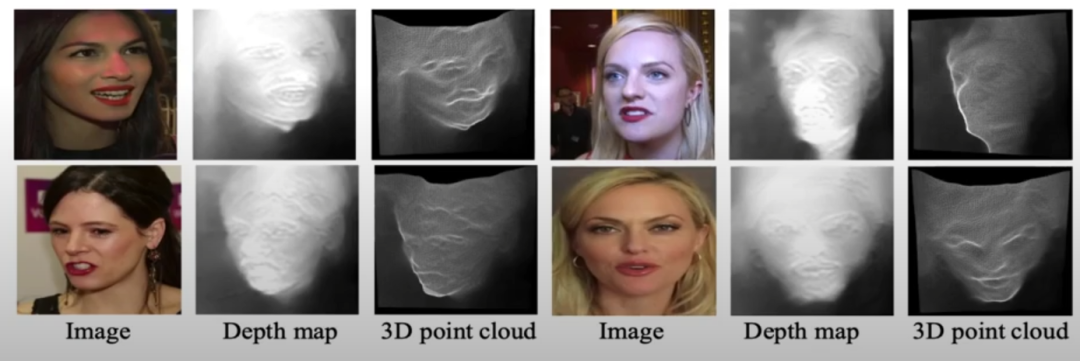
我们将学习到的人脸深度图及其对应的 3d 点云可视化。学习到的密集 3D 面部结构显然非常有益,并有显着改善。

此外,我们将密集的深度感知注意力图可视化。
每个查询点的高激活区域主要位于人脸表情相关的部分。
这些可视化结果表明,我们设计的跨模态注意力模块,确实可以解决人脸的微运动,从而在生成过程中产生更生动的表情
另外代码部分作者已开源,感兴趣的可以去尝试哈:
今天的分享就到这里,大家喜欢的话,可以多多支持,感谢!