文章目录
参考:

基础模型:

下表是在上述基础模型上进行指令微调的大模型:


一、 GPT系列
| 模型 | 发布日期 |
|---|---|
| GPT | 2018-11-14 |
| GPT-2 | 2019-11-27 |
| GPT-3 | 2020-6-11 |
| InstructGPT | 2022-3-4 |
| ChatGPT | 2022-11-30 |
| GPT-4 | 2023-3-14 |
| ChatGPT Plugin | 2023-5-12 |
1.1 GPTs(OpenAI,2018——2020)
GPT是自回归模型(auto-regression),使用 Transformer 的 Decoder 模块构建。原始的Transformer Decoder 比Encoder 多了一个encoder-decoder-attention层(第二个自注意力层,k和v来自encoder层最后的输出memory),使得它可以关注来自 Encoder 的信息。在GPT中,使用的decoder去掉了这一层。
自回归:生每个 token 之后,将这个 token 添加到输入的序列中,形成一个新序列。然后这个新序列成为模型在下一个时间步的输入。

Mask 操作是在 Self-Attention 进行 Softmax 之前进行的,具体做法是将要 Mask 的位置用一个无穷小的数替换 -inf,然后再 Softmax,如下图所示。


下图是 GPT 整体模型图,其中包含了 12 个 Decoder:

GPT提出来“生成式预训练(无监督)+判别式任务精调(有监督)”的范式来处理NLP任务。
- 生成式预训练:在大规模无监督语料上进行预训练一个高容量的语言模型,学习丰富的上下文信息,掌握文本的通用语义。
- 判别式任务精调:在通用语义基础上根据下游任务进行领域适配。具体的在预训练好的模型上增加一个与任务相关的神经网络层,比如一个全连接层,预测最终的标签。并在该任务的监督数据上进行微调训练(微调的一种理解:学习率较小,训练epoch数量较少,对模型整体参数进行轻微调整)
GPT-2(2019-2)和GPT-3(2020-6)的区别:
- GPT-3使用了更深的网络层数和更宽的Transformer网络结构,模型更大,参数更多,表达能力和语言理解能力更强;
- GPT-3在预训练阶段使用了更大规模的数据集,并采用了更多样化的预训练任务
- GPT-3的微调阶段采用了zero-shot学习和few-shot的方法,使得GPT-3具备更强的泛化能力和迁移学习能力。
1.2 InstructGPT(2022-3)
《李沐论文精度系列之九:InstructGPT》、bilibili视频《InstructGPT 论文精读》
1.2.1 算法
语言模型扩大并不能代表它们会更好地按照用户的意图进行工作,大语言模型很可能会生成一些不真实的、有害的或者是没有帮助的答案。换句话说,这些模型和用户的意图并不一致(not aligned with their users)。由此OpenAI提出了“align”的概念,即希望模型的输出与人类意图“对齐”,符合人类真实偏好。
InstructGPT提出了语言模型的三个目标:
- helpful——帮助用户解决问题
- honest——不能伪造信息或误导用户
- harmless——不会令人反感,也不会对他人或社会有害
InstructGPT使用来自人类反馈的强化学习(利用人类的偏好作为奖励信号,让模型仿照人来生成答案),对GPT-3进行微调,实现以上目标。具体实现步骤如下:

- 收集示范数据,进行有监督微调
SFT。- 标注数据:根据prompts(提示,这里就是写的各种各样的问题),人类会撰写一系列demonstrations(演示)作为模型的期望输出(主要是英文);
- 模型微调:将prompts和人类标注的答案拼在一起,作为人工标注的数据集,然后使用这部分数据集对预训练的GPT-3进行监督微调,得到第一个模型
SFT(supervised fine-tuning,有监督微调) - 因为问题和答案是拼在一起的,所以在 GPT 眼中都是一样的,都是给定一段话然后预测下一个词,所以在微调上跟之前的在别的地方做微调或者是做预训练没有任何区别。
- 收集比较数据,训练奖励模型
RM。- 生成式标注是很贵的一件事,所以第二步是进行排序式/判别式标注。用上一步得到的
SFT模型生成各种问题的答案,标注者(labelers)会对这些输出进行比较和排序(由好到坏,比如下图D>C>A=B)。 - 基于这个数据集,用强化学习训练一个
RM(reward model)。训练好了之后这个RM模型就可以对生成的答案进行打分,且打出的分数能够满足人工排序的关系。
- 生成式标注是很贵的一件事,所以第二步是进行排序式/判别式标注。用上一步得到的
- 使用强化学习的机制,优化
SFT模型,得到最终的RL模型(InstructGPT)。
将SFT模型的输出输入RM进行打分,通过强化学习来优化SFT模型的参数,详见本文4.3节。
步骤2和步骤3可以连续迭代。第二步可以使得在同样的标注成本下得到更多的数据,模型的性能会更好一些,最终得到的模型就是InstructGPT。
1.2.2 损失函数
语言模型通过预测下一个词的方式进行训练,其目标函数是最大化给定语言序列的条件概率,而不是“有帮助且安全地遵循用户的指示”,所以当前的语言模型训练的目标函数有问题。这部分在第三步RL模型(InstructGPT)中体现。简单来说就是新的损失函数包括以下几个部分:

- 在标注数据集上训练,期望RL模型的输出在RM模型里打分尽可能的高
- β l o g ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) \beta log(\pi_{\phi }^{RL}(y|x)/\pi^{SFT} (y|x) ) βlog(πϕRL(y∣x)/πSFT(y∣x)):正则项。
随着模型的更新,RL产生的输出 y y y和原始的SFT模型输出的 y y y会逐渐不一样,所以作者在loss里加入了一个KL散度(评估两个概率分布的差异),希望RL在SFT模型的基础上优化一些就行,但是不要偏太远,即相当于加入了一个正则项。 - γ E x ∼ D p r e t r a i n [ l o g ( π ϕ R L ( x ) ] \gamma E_{x}\sim D_{pretrain}[log(\pi_{\phi }^{RL}(x)] γEx∼Dpretrain[log(πϕRL(x)]:GPT-3模型原来的的目标函数
- 如果只使用上述两项进行训练,会导致该模型仅仅对人类的排序结果较好,而在通用NLP任务上,性能可能会大幅下降。文章通过在loss中加入了GPT-3预训练模型的目标函数来规避这一问题。
1.3 ChatGPT(2022.11.30)
ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)来指导模型的训练。区别是InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调的。
1.4 ChatGPT plugin
为了能够更加灵活的扩展 ChatGPT 的现有功能,OpenAI 正式上线了以安全为核心的 ChatGPT plugin,在保障数据安全性的前提下,让 ChatGPT 功能再度提升一整个数量级!plugin(插件)可以允许 ChatGPT 执行以下操作:
- 检索实时信息: 例如,体育比分、股票价格、最新消息等。
- 检索知识库信息: 例如,公司文件、个人笔记等。
- 代表用户执行操作;例如,订机票、订餐等。
ChatGPT plugin,其实就是类似Toolformer技术的应用,使得模型可以连接成百上千个API,这样大语言模型只是一个交互的工具,真正完成任务的还是之前的各种工具。这样不仅准确度可以提升,而且3月24ChatGPT plugin开通联网后,还可以更新自己的知识库,开启了无限可能。
比如用计算器进行计算肯定是可以算对的,而不需要像之前一样进行推理了。
1.5 GPT-4(2023.3.14)
GPT-4 是 OpenAI 继 ChatGPT 之后发布的一个大规模的多模态模型,之前的 GPT 系列模型都是只支持纯文本输入输出的语言模型,而 GPT-4 可以接受图像和文本作为输入,并产生文本输出。
GPT-4 仍然是基于 Transformer 的自回归结构的预训练模型。OpenAI 的博客中表示在随意的对话中,GPT-3.5 和 GPT-4 之间的区别可能很微妙,当任务的复杂性达到足够的阈值时,差异就会出现,即 GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。
虽然在许多现实场景中的能力不如人类,但 GPT-4 在各种专业和学术基准测试中表现出人类水平的表现,包括通过模拟律师考试,得分在应试者的前 10% 左右。和 ChatGPT RLHF 的方法类似,alignment(对齐)训练过程可以提高模型事实性和对期望行为遵循度的表现,具有强大的意图理解能力,并且对 GPT-4 的安全性问题做了很大的优化和提升。
GPT-4 的基础模型其实于 2022 年 8 月就已完成训练。OpenAI 对于基础理解和推理能力越来越强的 LLM 采取了更为谨慎的态度,花 6 个月时间重点针对 Alignment、安全性和事实性等问题进行大量测试和补丁。2023 年 3 月 14 日,OpenAI 发布 GPT-4 及相关文章。文章中几乎没有披露任何技术细节。同时当前公开的 GPT-4 API 是限制了 few-shot 能力的版本,并没有将完整能力的基础模型开放给公众(这个版本会维护到6月14号)。
二、 LaMDA系列
2.1 LaMDA(Google 2021.5)
2.1.1 简介
LaMDA 是谷歌在2021年开发者大会上公布的,专用于对话的大语言模型。模型基于Transformer架构,并在具有1.56T单词的公开对话数据和其他网页文档上预训练,最终尺寸从2B到137B。
论文中提出三个指导模型更好训练的指标,并概括了如何在这三个方面取得进展:
- 质量:
- 合理性/Sensibleness:生成在对话上下文中有意义的响应
- 特异性/Specificity:通过判断系统的响应是否特定于前面的对话上下文来衡量的,而不是适用于大多数上下文的通用回应;
- 趣味性/Interestingness,SSI):衡量模型是否产生了富有洞察力、出乎意料或机智的回应,因此更有可能创造更好的对话。
- 安全性:
- 根基性,Groundedness :生成的响应中包含的声明能够被参考和与已知来源进行核实的程度。当前这一代语言模型通常会生成看似合理但实际上与已知外部事实相矛盾的陈述。
2.1.2 LaMDA 预训练与微调
在定义了对话模型训练的指导指标之后,LaMDA 讲过预训练与微调两个阶段的训练。
- 预训练:从公共对话数据和其他公共网页文档中收集并创建了一个具有 1.56T 单词的数据集,是用于训练以往对话模型的单词量的近 40 倍
- 微调阶段做两个工作:
- LaMDA 生成器:执行混合生成任务,以生成对给定上下文的自然语言响应(模式是预测两个角色来回对话的对话数据集中下一个token)
- LaMDA 分类器:预测LaMDA 生成器生成的响应的安全与质量(SSI)分数,安全分数低的候选响应首先被过滤掉,剩下的候选响应根据 SSI 分数重新排名,并选择分数最高的作为最终响应。

2.1.3 事实根基(真实性、可靠性)
人们能够使用工具并参考已建立的知识库来检测事实,但是很多语言模型仅利用内部模型参数来获取知识。谷歌通过与人的对话数据集进行微调,让LaMDA模型能够更好地利用外部知识来提供更可靠的回应。
具体来说,为了提高LaMDA模型原始回应的可靠性,谷歌采集了人与LaMDA之间的对话数据集。这些对话数据集在适当的情况下使用了搜索查询和搜索结果进行注释。谷歌通过对这个数据集进行微调,让LaMDA模型的生成器和分类器能够学习在与用户交互时如何调用外部信息检索系统,以增强回应的可靠性。虽然这项工作仍处于早期阶段,但谷歌已经看到了一些有希望的结果。
2.1.4 实验&结论
谷歌对预训练模型(PT)、微调模型(LaMDA)、人类评估者在多轮双作者对话上的响应进行评估,指标是质量、安全性和根基性,结果如下:

- 质量:LaMDA 在每个维度和所有模型大小情况下都显著优于预训练模型,合理性、特异性和趣味性等质量度量通常会随模型参数量提升;
- 安全性:可以通过微调提升,但是无法仅从模型缩放中得到收益;
- 根基性:随着模型大小的增加,根基性也提升,这或许是因为更大的模型具备更大的记住不常见知识的能力
微调使模型可以访问外部知识源并有效地将记住知识的负载转移到外部知识源。微调还可以缩小与人类水平的质量差距,尽管该模型在安全性和根基性方面的性能依然低于人类。
2.2 Bard(Google 2023.3.21)
Bard 是谷歌基于 LaMDA 研制的对标 ChatGPT 的对话语言模型,目前应该只支持英文对话,限美国和英国用户预约访问。
三、GLM
3.1 GLM生态
-
GLM:一种基于Transformer架构进行改进的通用预训练框架,GLM将不同任务的预训练目标统一为自回归填空任务(Autoregressive Blank Infilling),使得模型在自然语言理解和文本生成方面性能都有所改善。

-
GLM-130B:于2022年8月由清华智谱AI开源放出。该大语言模型基于之前提出的GLM(General Language Model),在Norm处理、激活函数、Mask机制等方面进行了调整,目的是训练出开源开放的高精度千亿中英双语稠密模型,能够让更多研发者用上千亿模型。 -
ChatGLM: 基于GLM-130B,引入面向对话的用户反馈,进行指令微调后得到的对话机器人。ChatGLM解决了大基座模型在复杂问题、动态知识、人类对齐场景的不足。ChatGLM于2023年3月开启申请内测,目前暂停了公开申请。 -
ChatGLM-6B:于2023年3月开源。在进行ChatGLM千亿模型内测的同时,清华团队也开放出了同样技术小参数量的版本,方便研发者们进行学习和开发(非商用)。

3.2 GLM(清华等,2022.3.17)
3.2.1 背景
NLP任务分为NLU(文本分类、分词、句法分析、信息抽取等)、有条件生成任务(seq-seq,如翻译任务、QA)、无条件生成任务(用预训练模型直接生成内容)三大类。基础的预训练模型也分为三种:
| 预训练模式 | 代表模型 | 说明 |
|---|---|---|
| 自编码 | BERT | 双向的transformer作为编码器,在语言理解相关的文本表示效果很好。缺点是不能直接用于文本生成。 |
| 自回归 | GPT | 从左往右学习的模型,在长文本的生成能力很强。缺点是单向的注意力机制在NLU任务中,不能完全捕捉token的内在联系。 |
| 编码解码 | T5 | 编码器使用双向注意力,解码器使用单向注意力,并且有交叉注意力连接两者。在有条件生成任务中表现良好(文本摘要,回答生成)。 |
所以用一张表格简单总结就是:

注:✅表示擅长,x表示无法直接应用,— 表示可以做
目前这些训练前框架都不足以在所有NLP中具有竞争力任务。以往的工作(T5)试图通过多任务学习统一不同的框架。然而,由于自编码和自回归的目标性质不同,简单的统一不能完全继承这两个框架的优点。
3.2.2 主要贡献
- 提出了一种基于自回归空白填充的通用语言模型(GLM)来应对上述三种任务。
- GLM通过添加2D位置编码并允许任意顺序预测跨度来改进空白填充预训练,从而在NLU任务上比BERT和T5获得了性能提升。
- 通过变化空白数量和长度,可以针对不同类型的任务对GLM进行预训练。
- 在跨NLU、有条件和无条件生成的广泛任务范围内,GLM在相同的模型大小和数据情况下优于BERT、T5和GPT,并且使用BERTLarge的1.25×参数的单个预训练模型实现了最佳性能,展示了其对不同下游任务的通用性。
3.2.3 预训练

3.2.3.1 模型输入
GLM通过优化自回归空白填充目标进行训练。给定输入文本x =[x 1 ,··· ,x n ],对多个文本跨度spans {s 1 ,··· ,s m } 进行采样,然后将这些span进行mask(用[mask]标记替换),形成损坏的文本xcorrupt。span的长度服从泊松分布(λ=3),与BART一样,重复采样,直到15%的token被mask(根据经验,15% 的比率对于下游 NLU 任务的良好性能至关重要)。
下面举例说明。对于input=[x1,x2,x3,x4,x5,x6],假设mask 掉 [x3] 和 [x5,x6]。然后输入x包括两部分:
- part A:损坏的文本
xcorrupt,例子中是[x1,x2,mask,x4,mask] - part B :mask掉的span部分,例子中是
[x5,x6],[x3]。为了完全捕捉不同跨度之间的相互依赖关系,会随机排列跨度的顺序,类似于置换语言模型XLNet。
3.2.3.2 预训练目标&Mask矩阵
预训练的目标是:通过自回归方式从损坏的文本xcorrupt中预测跨度span中被mask的部分,即从part A预测part B。下图显示了mask矩阵,可以看出:
- Part A部分采用双向注意力,可以关注它们自己(蓝框)前后的信息,但不能关注 B;
- Part B采用单向注意力,可以关注 A 部分及 B 部分中的前文。
为了启用自回归生成,每个span都自动填充了特殊标记 [S] 和 [E] ,表示预测从start到end跨度的部分。通过这种方式,GLM在统一模型中自动学习双向编码器(Part A)和单向解码器(Part B)。

3.2.3.3 二维位置编码

如上图所示,Part A与PartB拼接成一个sequence,每个token都用两个位置编码 ids( two positional ids):
- positional id1:表示损坏的文本xcorrupt中的位置,PartB以span被mask的位置表示
- positional id2:表示跨度内的位置,所以Part A统一以0表示。PartB中的token,以从开始到此位置的span长度表示。
最终两个位置编码都会加入到输入token 的embedding向量中。
3.2.3.4 多任务预训练
前面的介绍中,span都比较短,适用于NLU任务。然而,我们希望模型能同时处理NLU任务和文本生成任务是,所以我们设置了第二个预训练任务——长文本生成,分两个级别:
- 文档级别(gMASK)。我们随机抽样一个跨度,其长度从原始长度的50%到100%的均匀分布中抽样。该目标旨在进行长文本生成。
- 句子级别(sMASK)。我们限制掩蔽跨度必须是完整的句子。我们随机抽样多个跨度(句子)以覆盖15%的原始令牌。此目标旨在进行序列到序列任务,其预测通常为完整的句子或段落。
这两个级别的生成任务和NLU任务相同,唯一的区别在于跨度数量和跨度长度。在实际使用中,可以根据不同的任务需要,设置不同mask方式的比例。例如,如果希望模型有更强的生成能力,可以把文档级别的gMASK的比例设置地比较高。在GLM-130B中,采用了70%文档级别的gMASK和30%单词级别的MASK。
3.2.4 模型结构
GLM 使用单个Transformer ,并对架构进行了多项修改:
- 采用
Sandwich-LN。LayerNorm会影响训练的稳定性,目前认为认为稳定性上: Sandwich-LN > Pre-LN > Post-LN(原始的BERT) - 使用单个线性层来进行输出Token预测
ReLU激活函数替换为GELU

3.2.5 下游任务微调

对于下游NLU任务,我们通常会在模型之上添加线性分类器,以前层的输出作为输入来预测正确的标签,但这会导致预训练和微调之间的不一致。
GLM微调时,分类任务转换为完形填空,类似PET。如上图示例,原本的“positive”和“negative”二分类任务,转换为预测[mask]的任务(映射到单词“good”和“bad”)。
其实这部分就是
Prompt Tuning,有三种主要算法:PET、P-Tuning和EFL。有兴趣的可以参考《PaddleNLP系列课程一:Taskflow、小样本学习、FasterTransformer》第二章。
3.2.6 实验结果
- SuperGLUE:NLU任务上,GLM在大多数具有基础架构或大型架构的任务上始终优于BERT。平均而言,
GLMBase得分比BERT Base 高 4.6%,GLMLarge得分比BERT Large 高 5.0%。

- Sequence-to-Sequence:GLM RoBERTa可以实现匹配Seq2Seq BART模型的性能,并且优于T5和UniLMv2

3. 有条件生成和无条件生成

其它结果请看论文。
3.2.7 结论
GLM是一种用于自然语言理解和生成的通用预训练框架。论文展示了NLU任务可以被形式化为条件生成任务,因此可以由自回归模型解决。GLM将不同任务的预训练目标统一为自回归空白填充,具有混合的注意力掩码和新颖的二维位置编码。我们的实验证明GLM在NLU任务中优于先前的方法,并且可以有效地共享参数以用于不同的任务。
3.3 GLM-130B
3.3.1 背景&模型优势
GPT-3是一款强大的语言模型,但由于未公开,存在技术瓶颈。目前的语言模型规模庞大,训练需要数百张A100以上的显卡,非常困难。GLM-130B是2022年8月由清华AI向研究界和工业界开放的拥有1300亿参数的中英双语稠密模型。本文介绍了GLM-130B的训练过程,包括设计选择、高效稳定的训练策略和工程努力。
在广泛的英语测试中,GLM-130B的性能明显优于GPT-175B,但在OPT-175B和BLOOM-176B上并未观察到性能优势。在相关测试中,GLM-130B也始终明显优于最大的中文模型ERNIE TITAN 3.0 260B。最后,利用GLM-130B独特的缩放特性,实现了INT4量化使其成为100B缩放模型中的先驱,可进行快速推理(小型多任务模型成为一种趋势)。
- 可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
- 跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
2022年11月,在斯坦福大学大模型中心对全球30个主流大模型的评测报告中,GLM-130B 在准确性和恶意性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中表现不错(下图)。

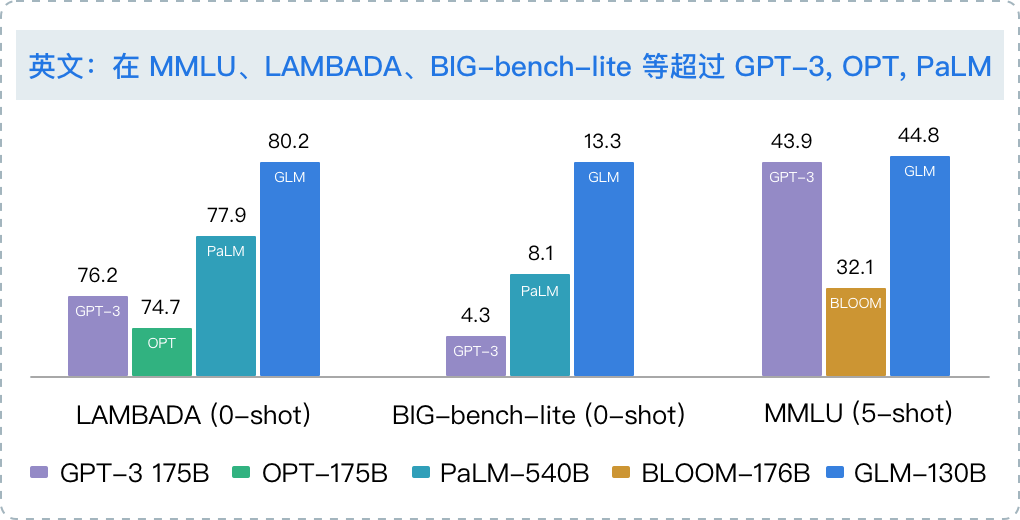 |
![(image2.jpg)]](https://img-blog.csdnimg.cn/c960e024262f4dd294be2c03d4154208.png) |
|---|

3.3.2 Deep Layer Norm
训练不稳定性是训练LLMs的一个主要挑战,适当选择LNs有助于稳定LLM的训练。作者发现GLM的训非常不稳定,于是使用了Deep Layer Norm机制,公式为:

此外,所有偏置项都被初始化为零。下图显示Deep Layer Norm显著有利于GLM-130B的训练稳定性,比Sandwich-LN更稳定。

3.3.3 位置编码
位置编码分为绝对位置编码和相对位置编码。一些较新的在大模型中应用较多的位置编码有ALiBi和RoPE,GLM-130B采用的是后者。GLM-130B团队的观点是虽然RoPE外推性能有限,但是并不应该把长文本的处理问题完全依赖于位置编码的外推,而是需要什么样的长度就在什么样的context length上做训练。

3.3.4 大模型训练系列技术(混合精度训练、激活函数重演、数据并行、流水线气泡)
这部分内容请参考官方视频《从GLM-130B到ChatGLM:大模型预训练与微调》、视频笔记。
3.4 ChatGLM(2023.3.22)
由于GLM-130B的动态知识欠缺、知识陈旧、缺乏可解释性,同时缺少高效“Prompt工程”,在对话场景中使用时很难尽人意。所以清华大学参考了 ChatGPT 的设计思路,在 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等技术实现人类意图对齐。
ChatGLM千亿参数版本由于还处于内测,没有太多的公开信息,报告中给出了目前的一些成绩对比:
- 在
MMLU评测基准上,较GLM-130B有了有更大提升,超过GPT3 davinci版本30%,达到了ChatGPT(GPT-3.5-turbo)的81% - 在非数学知识场景达到了
ChatGPT(GPT-3.5-turbo)的95% - 在非数学推理场景达到了
ChatGPT(GPT-3.5-turbo)的96% - 在高考、SAT、LSAT等考试的综合成绩上,达到了
ChatGPT(GPT-3.5-turbo)的90%。
3.5 ChatGLM-6B
3.5.1 简介
由于ChatGLM千亿参数版本暂未公开,为了与社区一起更好地推动大模型技术的发展,清华团队开源了62亿参数版本的ChatGLM-6B。结合模型量化技术,用户可以在消费级的显卡上进行本地部署。
该版本具有以下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
3.5.2 局限性
- 模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
- 偏见:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 多轮对话能力较弱:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
- 英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
- 易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
3.5.3 环境配置

ChatGLM-6B所有模型文件,总共13G左右,显存不够时可以使用量化模型的方式加载,4-bit量化后可以加载到显存,占用5.2G显存左右,但是量化加载需要13G的内存,就是无论无何这13G的模型文件要么直接加载到显存,要么加载到内存量化后再加载到显存
下面官方直接提供了量化后的模型文件,也就避免了上述处理13G模型文件的操作。
- 4-bit量化后的模型文件下载:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b-int4 - 进一步提对Embedding量化后的模型,模型参数仅占用4.3 GB显存:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b-int4-qe
3.5.4 相关开源项目
- Chinese-LangChain:中文langchain项目,基于ChatGLM-6b+langchain实现本地化知识库检索与智能答案生成,增加web search功能、知识库选择功能和支持知识增量更新
- langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答
- ChatGLM-6B-Engineering:基于 ChatGLM-6B 后期调教,网络爬虫及 Stable Diffusion 实现的网络搜索及图片生成
- ChatGLM-OpenAI-API:将 ChatGLM-6B 封装为 OpenAI API 风格,并通过 ngrok/cloudflare 对外提供服务,从而将 ChatGLM 快速集成到 OpenAI 的各种生态中。
对 ChatGLM-6B 进行微调的开源项目:
-
InstructGLM:基于ChatGLM-6B进行指令学习,汇总开源中英文指令数据,基于Lora进行指令数据微调,开放了Alpaca、Belle微调后的Lora权重,修复web_demo重复问题
-
ChatGLM-Finetuning:一种平价的chatgpt实现方案,基于清华的ChatGLM-6B+ LoRA 进行finetune。
-
ChatGLM-Efficient-Tuning:基于ChatGLM-6B模型进行定制化微调,汇总10余种指令数据集和3种微调方案,实现了4/8比特量化和模型权重融合,提供微调模型快速部署方法。
-
ChatGLM-Tuning:基于 LoRA 对 ChatGLM-6B 进行微调。
四、 PaLM(Google Research 2022.4 )
4.1 简介
PaLM(Pathways Language Model )是谷歌2022年提出的 540B 参数规模的大语言模型,论文主要贡献有:
- PaLM 使用 谷歌提出的Pathways系统 在 6144 TPU v4 芯片上进行训练(Pathways 是一种新的 ML 系统,可以跨多个 TPU Pod 进行高效训练,详情可参考李沐的Pathways论文精读)
- 它通过在数百种语言理解和生成基准上实现小样本学习sota结果,证明了scaling的良好效果。
4.2 模型结构
PaLM 使用Transformer decoder架构,但是做了一些修改:
- 采用
SwiGLU激活函数,提供更好的性能和梯度流动,提高模型效果 - 提出
Parallel Layers,并行处理多个输入,训练速度提高约 15% - Multi-Query Attention共享key/query的映射,自回归时解码更快
- 位置嵌入使用
RoPE embeddings,在长文本上性能更好 - 采用
Shared Input-Output Embeddings,输入、输出embedding矩阵是共享 - 不使用偏置项:在dense kernel或layer norm中都没有使用偏差,这种操作提高了大模型的训练稳定性
4.2.1 SwiGLU层
在论文《GLU Variants Improve Transformer》中提到,使用SwiGLU替换transformer中FFN的第一层,得到的FFNSwiGLU,已被证明可以显著提高模型效果,下面进行简单的介绍。
4.2.1.1 FFN
一个Transformer Bolck中主要包含三部分:MultiheadAttention(多头注意力)、FFN(前馈神经网络)和Add&Norm(残差连接和LayerNorm),其中FFN是由两个线性变换层和激活函数组成。

所以Transformer中的FFN层可表示为:
F F N ( x , W 1 , W 2 , b 1 , b 2 ) = W 2 ( r e l u ( x W 1 + b 1 ) ) + b 2 = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x, W_1, W_2, b_1, b_2) = W_{2}(relu(xW_{1}+b_{1}))+b_{2}=max(0, xW_1 + b_1)W_2 + b_2 FFN(x,W1,W2,b1,b2)=W2(relu(xW1+b1))+b2=max(0,xW1+b1)W2+b2
- relu的优点:神经元只需要进行加、乘和比较这些简单的计算操作,而且有很好的稀疏性,大约有50%的神经元会处于激活状态
- relu的缺点:输出是非零中心化的,会给后面的计算引入偏置转移的问题,影响梯度下降的效率。
神经元在训练时容易死亡,不恰当的更新会导致参数梯度一直为0,永远无法被激活。
在T5模型中去除了FFN的偏置项,所以T5中的FFN表示为:
F F N R e L U ( x , W 1 , W 2 ) = m a x ( 0 , x W 1 ) W 2 FFN_{ReLU}(x, W_1, W_2) =max(0, xW_1 )W_2 FFNReLU(x,W1,W2)=max(0,xW1)W2
4.2.1.2 swish激活函数及FFN变体
后面的一些工作也使用了其它的激活函数替换ReLU,例如Hendrycks等人就使用了GELU来进行替换,Ramachandran等人使用了Swish来进行替换 :
FFN GELU ( x , W 1 , W 2 ) = GELU ( x W 1 ) W 2 FFN Swish ( x , W 1 , W 2 ) = Swish 1 ( x W 1 ) W 2 \begin{align*} \text{FFN}_{\text{GELU}}(x, W_1, W_2) &= \text{GELU}(xW_1)W_2 \\ \text{FFN}_{\text{Swish}}(x, W_1, W_2) &= \text{Swish}_1(xW_1)W_2 \\ \end{align*} FFNGELU(x,W1,W2)FFNSwish(x,W1,W2)=GELU(xW1)W2=Swish1(xW1)W2
其中,GELU(高斯误差线性单元)公式为:(erf 表示误差函数)
GELU ( x ) = 1 2 ( 1 + erf ( x 2 ) ) ⋅ x \text{GELU}(x) = \frac{1}{2} \left(1 + \text{erf}\left(\frac{x}{\sqrt{2}}\right)\right) \cdot x GELU(x)=21(1+erf(2x))⋅x
Swish:
Swish ( x ) = x ⋅ sigmoid ( β ⋅ x ) \text{Swish}(x) = x \cdot \text{sigmoid}(\beta \cdot x) Swish(x)=x⋅sigmoid(β⋅x)
Swish具有以下特性:
-
平滑性:Swish函数在整个实数域上是连续且可微的,没有突变点或不连续的部分,这有助于提高梯度的稳定性和训练的效果。(比ReLU更平滑)
-
渐进饱和性:Swish函数在输入为正或负的大值时,会趋向于饱和,即输出值接近于输入值。这有助于抑制大幅度的激活响应,减轻梯度爆炸的问题。
-
自适应性:Swish函数具有自适应的特性,它的形状和曲线根据输入值的变化而变化。在较大的负值范围内,Swish函数趋向于线性变换;在较大的正值范围内,Swish函数趋向于饱和(Sigmoid函数的特性),保持输入的大部分信息。Swish函数结合了ReLU的线性增长特性,和Sigmoid函数的平滑特性,使得处理复杂的非线性关系时更具表达能力。
-
较低的计算复杂度:相比于其他激活函数(如ReLU),Swish函数的计算复杂度较低,可以更高效地进行前向传播和反向传播。
4.2.1.3 GLU一般形式及变体
GLU,门控线性单元(Gated Linear Units),是一种神经网络层,其核心思想是通过门控机制来控制激活函数的输出,由线性变换和门控机制组成:
- 输入 x x x通过线性变换得到两个输出向量,分别称为"门"向量(下式中的 x W + b xW + b xW+b)和"中间"向量(下式中的 x V + c xV + c xV+c)
- 门向量通过一个激活函数(通常是sigmoid函数)进行门控,产生一个介于0和1之间的值,表示在给定位置上的输入是否应该被过滤或保留
- 中间向量与门向量进行Hadamard乘积,从而对输入进行控制和加权。
GLU的一般形式可表示为:
G L U ( x , W , V , b , c ) = σ ( x W + b ) ⊗ ( x V + c ) GLU(x, W, V, b, c) = σ(xW + b) ⊗ (xV + c) GLU(x,W,V,b,c)=σ(xW+b)⊗(xV+c)
如果将激活函数省略,就可以得到一个双线性变换函数(Bilinear),可表示为:
B i l i n e a r ( x , W , V , b , c ) = ( x W + b ) ⊗ ( x V + c ) Bilinear(x, W, V, b, c) = (xW + b) ⊗ (xV + c) Bilinear(x,W,V,b,c)=(xW+b)⊗(xV+c)
GLU变体:
ReGLU ( x , W , V , b , c ) = max ( 0 , x W + b ) ⊙ ( x V + c ) GEGLU ( x , W , V , b , c ) = GELU ( x W + b ) ⊙ ( x V + c ) SwiGLU ( x , W , V , b , c , β ) = Swish β ( x W + b ) ⊙ ( x V + c ) \begin{align*} \text{ReGLU}(x, W, V, b, c) &= \max(0, xW + b) \odot (xV + c) \\ \text{GEGLU}(x, W, V, b, c) &= \text{GELU}(xW + b) \odot (xV + c) \\ \text{SwiGLU}(x, W, V, b, c, \beta) &= \text{Swish}_{\beta}(xW + b) \odot (xV + c) \end{align*} ReGLU(x,W,V,b,c)GEGLU(x,W,V,b,c)SwiGLU(x,W,V,b,c,β)=max(0,xW+b)⊙(xV+c)=GELU(xW+b)⊙(xV+c)=Swishβ(xW+b)⊙(xV+c)
从GLU的变体中我们不难发现ReGLU的表达式与FFN的表达式是相似的,所以考虑将FFN的第一次线性和激活函数替换为GLU,所以有:
FFNGLU ( x , W , V , W 2 ) = ( σ ( x W ) ⊙ x V ) W 2 FFNBilinear ( x , W , V , W 2 ) = ( x W ⊙ x V ) W 2 FFNReGLU ( x , W , V , W 2 ) = ( max ( 0 , x W ) ⊙ x V ) W 2 FFNGEGLU ( x , W , V , W 2 ) = ( GELU ( x W ) ⊙ x V ) W 2 FFNSwiGLU ( x , W , V , W 2 ) = ( Swish 1 ( x W ) ⊙ x V ) W 2 \begin{align*} \text{FFNGLU}(x, W, V, W2) &= (\sigma(xW) \odot xV)W_2 \\ \text{FFNBilinear}(x, W, V, W2) &= (xW \odot xV)W_2 \\ \text{FFNReGLU}(x, W, V, W2) &= (\max(0, xW) \odot xV)W_2 \\ \text{FFNGEGLU}(x, W, V, W2) &= (\text{GELU}(xW) \odot xV)W_2 \\ \text{FFNSwiGLU}(x, W, V, W2) &= (\text{Swish}1(xW) \odot xV)W_2 \\ \end{align*} FFNGLU(x,W,V,W2)FFNBilinear(x,W,V,W2)FFNReGLU(x,W,V,W2)FFNGEGLU(x,W,V,W2)FFNSwiGLU(x,W,V,W2)=(σ(xW)⊙xV)W2=(xW⊙xV)W2=(max(0,xW)⊙xV)W2=(GELU(xW)⊙xV)W2=(Swish1(xW)⊙xV)W2
不难看出,替换操作是FFN原先第一层的 x W 1 xW_1 xW1替换为GLU的 ( x W ) ⊙ x V (xW) \odot xV (xW)⊙xV,所以对比于原始的FFN来说,多了一项线性变换 x V xV xV。作者为了保持参数数量和计算量不变,将hidden unit减少2/3,即 W , V W,V W,V的第二维和 W 2 W_2 W2的第一维减少2/3。
4.2.1.4 实验结果
使用T5模型作为baseline,设置编码器和解码器各由12层组成,维度768,注意力层采用
h e a d = 12 , d k = d v = 64 head=12,d_k = d_v = 64 head=12,dk=dv=64 ,FFN层及其变体采用3072个神经元,而GLU及其变体则采用2048个神经元,实验结果如下所示:

在GLUE语言理解基准数据集的任务上进行对比:

4.2.2 Parallel Layers
在传统的语言模型中,模型的每一层负责特定的任务,每一层都必须等待前一层完成后才能开始处理。Parallel Layers是PaLM的一个关键创新,通过并行层,可以同时处理多个任务,显著提高模型的速度和准确性(并行层可以同时从多个示例中进行学习)。
标准的transformer block中,输出公式可以写成:
y = x + M L P ( L a y e r N o r m ( x + A t t e n t i o n ( L a y e r N o r m ( x ) ) ) y = x + MLP(LayerNorm(x + Attention(LayerNorm(x))) y=x+MLP(LayerNorm(x+Attention(LayerNorm(x)))
在Parallel Layers中,可以写成:(代码可参考LLM系列之PaLM)
y = x + M L P ( L a y e r N o r m ( x ) ) + A t t e n t i o n ( L a y e r N o r m ( x ) ) y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x)) y=x+MLP(LayerNorm(x))+Attention(LayerNorm(x))
并行公式使大规模训练速度提高了大约 15%。消融实验显示在 8B 参数量下模型效果下降很小,但在 62B 参数量下没有模型效果下降的现象。
4.2.3 共享键/值的映射
标准的transformer block中,假设有k个注意力头,则计算过程为:
- 使用矩阵 W W W将Q、K、V映射到k个不同的语义空间中,形状为[k, h];
- 进行Attention计算,得到k个head矩阵。
- 将这k个矩阵串联拼接起来,乘以矩阵 W o W^o Wo(保持维度一致)得到多头注意力结果。
故多头注意力模型公式可以写成:
M u l t i − H e a d ( Q , K , V ) = c o n c a t ( h e a d 1 . . . . h e a d c ) W O = [ c o n c a t ( h 1 , 1 . . . h n , 1 ) W O . . . c o n c a t ( h 1 , m . . . h n , m W O ] Multi-Head(Q ,K , V )=concat(head_1....head_c)W^{O}=\begin{bmatrix} concat(h_{1,1}...h_{n,1})W^{O}\\ ...\\ concat(h_{1,m}...h_{n,m}W^{O}\end{bmatrix} Multi−Head(Q,K,V)=concat(head1....headc)WO= concat(h1,1...hn,1)WO...concat(h1,m...hn,mWO

而在PaLM中,每个head的key/value权值共享,即key和value被映射为[1,h],但query仍然被映射为shape[k,h]。论文发现这种操作对模型质量和训练速度没有影响,但在自回归解码时间上有效节省了成本。(标准的多头注意力在自回归解码过程中,键(key)和值(value)张量在不同样本之间不共享,并且每次只解码一个单词,所以在加速器硬件上的效率较低)
4.2.4 RoPE embeddings
RoPE 嵌入在长文本上具有更好的性能 ,具体原理可看苏神文章《Transformer升级之路:2、博采众长的旋转式位置编码》
4.2.5 Shared Input-Output Embeddings
在自然语言处理任务中,输入序列和输出序列都需要经过嵌入层来获取对应的嵌入向量。而在PaLM中,输入序列和输出序列共享相同的嵌入层参数矩阵,即输入序列中的单词通过嵌入层获得其嵌入向量,同时输出序列中的单词也通过相同的嵌入层获得对应的嵌入向量。
这样做的目的是为了让输入和输出之间共享语义信息,表示更加一致和相互关联,使得模型能够更好地理解输入和输出之间的语义关系,并更准确地进行预测和生成。
需要注意的是,共享嵌入层并不意味着输入和输出之间的嵌入是完全相同的,而是共享参数矩阵,通过参数的共享来实现输入和输出之间的信息传递和一致性。
4.3 模型尺度和训练数据
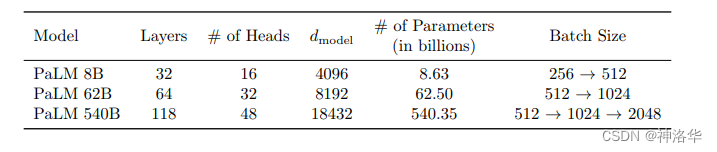
考虑了三种不同的模型尺度:540B、62B 和 8B 参数:
PaLM 预训练数据集:
- 包含 7800 亿个标记的高质量语料库,代表了广泛的自然语言用例。该数据集是经过过滤的网页、书籍、维基百科、新闻文章、源代码和社交媒体对话的混合体。该数据集基于用于训练
LaMDA(Thoppilan 等人,2022 年)和GLaM(Du 等人,2021 年)的数据集。 - 所有三个模型都只在一个时期的数据上进行训练(所有模型的数据清洗方式都相同)。
- 除了自然语言数据,预训练数据集还包含 196GB 代码,从 GitHub 上的开源存储库获取,包括 Java、HTML、Javascript、Python、PHP、C#、XML、C++ 和 C。

4.4 训练硬件资源

总体来说,该程序包含:
- 组件 A:用于 pod 内前向+反向计算(包括 pod 内梯度减少)
- 组件 B:用于跨 pod 梯度传输的传输子图,以及用于优化器更新的(包括本地和远程梯度的求和)
Pathways 程序在每个 pod 上执行组件 A,然后将输出梯度传输到另一个 pod,最后在每个 pod 上执行组件 B。因此,它掩盖了延迟,还分摊了管理数据传输的成本,PaLM 代表了 LLM 训练效率向前迈出的重要一步。(PaLM的硬件FLOPs利用率为57.8%,模型FLOPs利用率见下表)

FLOPS表示每秒钟可以执行的浮点运算次数,Model FLOPS utilization(模型FLOPS利用率)是指在机器学习模型中使用的浮点运算数(FLOPS)的有效利用程度,表示实际执行的浮点运算与模型的理论计算能力之间的关系。一个高的Model FLOPS utilization意味着模型能够有效地利用计算资源,并将其转化为有意义的计算任务。这意味着模型的计算效率较高,能够更快地完成训练或推断任务。
4.5 实验
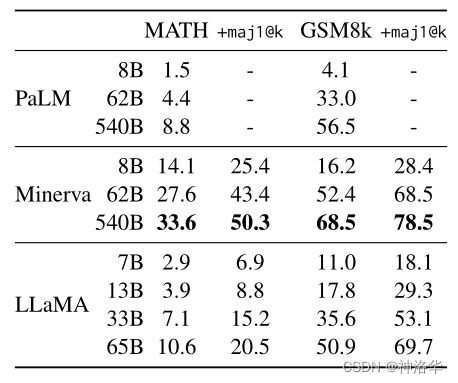
PaLM 540B 在所有基准测试中都优于类似尺寸的模型(Megatron-Turing NLG 530B)。这表明预训练数据集、训练策略和训练期间观察到的标记数量在实现这些结果方面也起着重要作用。


PaLM-Coder 540B 的性能进一步提高,在 HumanEval 上达到 88.4% pass@100,在 MBPP 上达到 80.8% pass@80。

其它实验效果详见论文。
五、 BLOOM(Google AI,2022.7)
5.1 背景
大型语言模型(LLMs)已被证明能够根据少数示例或指令微调就可以执行新任务(zero-shot),但大多数LLMs是由资源充裕的组织开发的,且没有公开发布。因此,大多数的研究社区都被排除在LLMs的开发之外,也导致了一些结果,例如大多数LLMs主要是在英文文本上训练的。
为了推广这一技术,我们发布了BLOOM模型。BLOOM是一个在包含46种自然语言和13种编程语言的数百个数据源上训练的1760亿参数的多语言模型,由数百名研究人员合作开发和发布的。BLOOM使用了Transformer-decoder结构,在各种基准测试中取得了竞争性的性能。
为构建BLOOM,我们对其各个组成部分进行了彻底的设计过程,包括训练数据集(第3.1节)、模型架构和训练目标(第3.2节)以及分布式学习的工程策略(第3.4节)。我们还对模型的能力进行了分析(第4节)。我们的总体目标不仅是公开发布一个具有与最近开发的系统相当性能的大规模多语言语言模型,还要记录开发过程中采取的协调步骤(第2.2节)。本文的目的是提供对这些设计步骤的高级概述,并引用我们在开发BLOOM过程中产生的各个报告。
BLOOM:BigScience Large Open-science Open-access Multilingual Language Model,大型开放多语言模型。
BigScience:是一个开放的研究合作组织,其目标是公开发布LLM。

5.2 训练数据
5.2.1 多语言语料库 ROOTS
BLOOM是在ROOTS语料库上进行训练的。该语料库是由498个Hugging Face数据集组成的综合集合,涵盖了1.61TB的文本,覆盖了46种自然语言和13种编程语言,其分布可见下图:

5.2.2 xP3和指令数据集xP3mt
在公共提示池(P3)的子集上训练的T0证明了,在多任务提示数据集的混合上微调的语言模型具有强大的零样本任务泛化能力。在预训练BLOOM之后,我们采用了同样的大规模多任务微调方法,为BLOOM赋予了多语言零样本任务泛化能力。我们将结果模型称为BLOOMZ。下面是模型用到的几个数据集:
-
P3:各种现有的和开源的英文自然语言数据集的提示集合,涵盖了各种自然语言任务,包括情感分析、问答和自然语言推理,并排除了有害内容或非自然语言,如编程语言。 -
xP3:为了训练BLOOMZ,我们扩展了P3,得到了xP3,一个包含83个数据集的提示集合,涵盖46种语言和16个任务。xP3中的任务既可以是跨语言的(例如翻译),也可以是单语言的(例如摘要、问答)。我们使用PromptSource来收集这些提示,并为提示添加了额外的元数据 -
xP3mt:为了研究多语言提示的重要性,我们还将xP3中的英语提示机器翻译为各自的数据集语言,从而生成了一个称为xP3mt的提示集合。

xP3的语言分布与
ROOTS紧密相关。
5.3 模型结构
我们评估了各种模型结构,发现因果解码器模型表现最佳。我们进行了一系列实验,评估了位置编码和激活函数等对因果解码器模型的影响,最终我们在BLOOM中采用了两种改进:
-
ALiBi位置嵌入:与将位置信息添加到嵌入层不同,ALiBi直接根据键和查询的距离减弱注意力得分。尽管ALiBi最初是基于对更长序列的外推能力的动机,但我们发现它在原始序列长度上也导致了更平滑的训练和更好的下游性能,优于原始transformer的和rotary embeddings这两种。 -
Embedding Layer Norm:嵌入层归一化。在嵌入层后添加了额外的层归一化层,显著提高了训练的稳定性。
请注意,初步的104B实验是在float16精度下进行的,而最终的训练是在bfloat16精度下进行的。自那时以来,float16被认为是导致训练LLM时观察到的许多不稳定性的原因之一(Zhang等人,2022;Zeng等人,2022)。bfloat16可能减轻了对嵌入层归一化的需求。
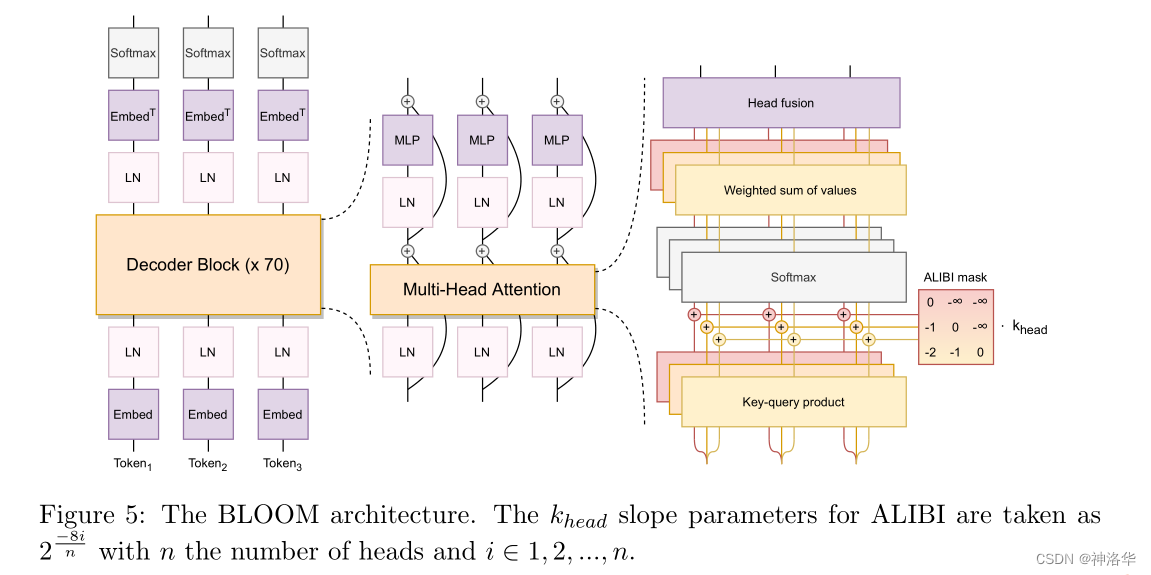
5.3 工程实现
BLOOM使用Megatron-DeepSpeed进行训练的,这是一个用于大规模分布式训练的框架。它由两个部分组成:
- Megatron-LM:提供了Transformer的实现,张量并行性和数据加载原语
- DeepSpeed提供了ZeRO优化器,模型流水线和通用的分布式训练组件。
这个框架使我们能够以高效的方式进行3D并行训练(三种互补的分布式训练方法的融合)。下面将介绍这些方法:
-
DP:Data parallelism,数据并行。将模型复制多次,每个副本放置在不同的设备上,并提供数据的切片进行并行处理。在每个训练步骤结束时,所有模型副本都会进行同步。 -
TP:Tensor parallelism,张量并行。将模型的各个层在多个设备上进行分区。这样,不再将整个激活或梯度张量放置在单个GPU上,而是将该张量的分片放置在不同的GPU上。这种技术有时被称为水平并行或层内模型并行。 -
PP:Pipeline parallelism,流水线并行。将模型的层分割到多个GPU上,这样模型的每个GPU上只放置部分层,这有时被称为垂直并行。 使用bfloat16 混合精度,使用融合的 CUDA 内核
最后,ZeRO(零冗余优化器)允许不同的进程仅保存数据的一部分(参数、梯度和优化器状态)。

该模型是在Jean Zay上进行训练的,Jean Zay是由法国国家计算中心(CNRS)的IDRIS运营的,由法国政府资助的超级计算机。
训练BLOOM大约耗时3.5个月,共计消耗了1,082,990个计算小时。训练过程在48个节点上进行,每个节点配备8个NVIDIA A100 80GB的GPU(总共384个GPU)
由于在训练过程中可能出现硬件故障,我们还保留了4个备用节点。每个节点配备2个AMD EPYC 7543 32核的CPU和512 GB的内存,存储由使用SpectrumScale(GPFS)并行文件系统的全闪存和硬盘驱动器混合处理,该文件系统在超级计算机的所有节点和用户之间共享。
每个节点有4个NVLink GPU到GPU的互连通道用于节点内通信,每个节点有4个Omni-Path 100 Gbps的链路,按照增强的8D超立方体全局拓扑结构排列,用于节点间通信
5.4 实验&评测
- SuperGLUE

SuperGLUE基准上zero-shot and one-shot prompt-based 效果
- HELM基准

5.5 总结
BLOOM主要提升LLM的多语言能力,采用因果解码器的结构,但是做了AIBI位置编码和层归一化两方面的改进。文在还有很详细的数据集采集即过滤、训练调试等细节,感兴趣的可以看看。
六、 FLAN(Google 2022.10)
FLAN 指的是(Instruction finetuning ),即"基于指令的微调"。通过在超大规模的任务上进行微调,可以大大提高语言模型的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。这意味着模型一旦训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现One model for ALL tasks。随后谷歌公开发布了大幅优于基线 T5 模型的 Flan-T5模型。
基础模型可以进行任意的替换(需要有Decoder部分,所以不包括BERT这类纯Encoder语言模型)
6.1 摘要
通过使用一系列以指令形式表达的数据集来对语言模型进行微调,已经被证明可以提高模型的性能并提高其对未见任务的泛化能力。在本论文中,我们探讨了指令微调的几个关键方面:(1)扩展任务数量,(2)扩大模型规模,(3)链式思维数据的微调(CoT,chain-of-thought data)。我们的实验表明,指令微调在任务数量和模型规模方面都具有良好的扩展性。其次,经过CoT的指令微调会极大提高在CoT任务上的性能。
我们发现,使用上述方法进行指令微调显著改善了各种模型类别(PaLM、T5、U-PaLM)、启动设置(零样本、少样本、连续思考)和评估基准(MMLU、BBH、TyDiQA、MGSM、开放式生成)的性能。
例如,经过1.8K个任务的指令微调后,Flan-PaLM 540B在性能上大幅超过了PALM 540B(平均提高了9.4%),并在一些基准测试中取得了SOTA性能,如在五样本MMLU上达到了75.2%。我们还公开发布了Flan-T5的checkpoints,即使与规模更大的模型(如PaLM 62B)相比,它们在少样本情况下也具有强大的性能。总体而言,指令微调是改善预训练语言模型性能和可用性的通用方法。

6.2 介绍
6.2.1 Task mixtures
混合任务包括总共 1836 种指令任务,包括 473个 数据集,146 个任务类别,包括Muffin3、T0-SF、NIV2和CoT以及一些对话、程序合成和链式思维推理任务。所有数据源都是公开的,详情可见附录F。
CoT微调混合:涉及CoT注释,我们使用它来探索在CoT注释上微调是否能够提高对未见推理任务的性能。我们从先前的工作中选择了九个数据集,人工评估者为这些数据集手动编写了CoT注释作为训练语料库。这九个数据集包括算术推理(Cobbe等,2021年)、多跳推理(Geva等,2021年)和自然语言推理(Camburu等,2020年)等任务。我们为每个任务手动编写了十个指令模板。数据卡片详见附录F。

6.2.2 模板和格式
因为需要用单个语言模型来完成超过1800+种不同的任务,所以需要将任务都转换成相同的“输入格式”喂给模型训练,同时这些任务的输出也需要是统一的“输出格式”。根据 “是否需要进行推理 (CoT)” 以及 “是否需要提供示例(Few-shot)” 可将输入输出划分成四种类型:

| chain-of-thought | few-shot | 输入 | 输出 |
|---|---|---|---|
| ❎ | ❎ | 指令 + 问题 | 答案 |
| ✅ | ❎ | 指令 + CoT引导(by reasoning step by step) + 问题 | 理由 + 答案 |
| ❎ | ✅ | 指令 + 示例问题 + 示例问题回答 + 指令 + 问题 | 答案 |
| ✅ | ✅ | 指令 + CoT引导 + 示例问题 + 示例问题理由 + 示例问题回答 + 指令 + CoT引导 + 问题 | 理由 + 答案 |
6.2.3 微调过程
文本中,我们实验了T5(80M到11B)、PaLM(8B到540B)和U-PaLM(540B)等各种规模的模型,训练过程都是相同的。
我们采用恒定的学习率以及Adafactor优化器进行训练;同时会将多个训练样本“打包”成单个序列,这些训练样本直接会通过一个特殊的“解释。token”进行分割,每个模型的微调步骤数、学习率、批次大小和丢弃率详见附录E。
对于每个模型,我们选择一个检查点用于所有评估。我们通过定期评估保留任务的性能(每2k到10k步骤,具体取决于模型大小)来确定最佳步骤,并在所有消融运行中使用相同数量的检查点步骤。

Flan-PaLM 540B时,只使用了预训练计算量的
0.2%
6.3 实验结果
- 增加微调数据中的任务数量可以提升
Flan-PaLM在大多数评估基准上的性能
如下表所示,评估基准包括MMLU(57个任务)、BBH(23个任务)、TyDiQA(8种语言)和MGSM(10种语言)。所有四个评估基准的评估指标都是few-shot提示准确率(完全匹配),我们对所有任务进行了平均值计算(不考虑权重)。

T5模型应用Flan效果如下:

- 模型越大效果越好、任务越多效果越好。

- 、CoT数据可显著提高模型的推理能力(包括零样本)

PaLM和
Flan-PaLM在23个具有挑战性的BIG-Bench任务(BBH)上的zero-shot表现。Flan-PaLM通过“Let’s think step-by-step”激活了链式思维(CoT)生成。
可以看到:
- 只有加入Flan训练之后的PaLM模型,CoT文本的加入才会带来效果提升;
- Flan本身也能够给模型带来足够的效果提升
6.4 总结
这篇工作提出了Flan的微调框架,核心有四点:统一的输入输出格式(4种类型),引入chain-of-thought,大幅提高任务数量,大幅提高模型体积;实现了用一个模型来解决超过1800种几乎全部的NLP任务,通过较低的成本,极大发掘了现有语言模型的泛化性能,让大家看到了通用模型的希望,即One Model for ALL Tasks。
七、 LLaMA系列
7.1 LLaMA(Meta AI 2023.2.24)
7.1.1 背景
Hoffmann等人的最新研究表明,在给定的计算预算下,最佳性能并不是由最大的模型实现的,而是由在更多数据上训练的较小模型实现的。但是在大模型时代,推理成本至关重要。在这种情况下,对于给定的性能水平,首选的模型不是训练速度最快的模型,而是推理速度最快的模型。尽管训练一个大模型以达到一定性能水平可能更便宜,但训练时间更长的较小模型最终在推理方面更经济。
本研究的重点是训练一系列语言模型,在各种推理预算下实现最佳性能。通过在更多的token上进行训练,得到的模型称为LLaMA,参数范围从7B到65B,与现在最好的LLM相当。
LLaMA-13B仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B)LLaMA-65B与业内最好的模型Chinchilla-70B和PaLM-540B实力相当。- 仅使用公开数据集即可部分复现最先进的性能(86%左右的效果)
7.1.2. 预训练数据
我们的训练数据集是多个来源的混合,涵盖了不同的领域,但仅限于使用公开可用且与开源兼容的数据。

1.4T tokens)。表中列出了每个子集的采样比例、epoch数量和磁盘大小。在预训练1T个token时,采样比例相同
7.1.3 模型结构
整体结构仍然是Transformer decoder,但是做了三点改进:
RMSNorm Pre-normalizatio(GPT3):为了提高训练的稳定性,我们对每个Transformer子层的输入进行归一化,而不是对输出进行归一化,并使用了RMSNorm归一化函数;SwiGLU(PaLM):将ReLU非线性激活函数替换为SwiGLU激活函数,详情参考本文4.2.1节;Rotary Embeddings (GPTNeo):去除了绝对位置嵌入,并在网络的每一层中添加了旋转位置嵌入RoPE
相关代码(llama/model.py):
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
# 作者对每个Transformer子层的输入进行归一化,而不是对输出进行归一化
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
7.1.4 高效训练
- 算法
我们的训练方法与Brown的Flan和Chowdhery的PaLM这些工作相似,并受到了Chinchilla scaling laws的启发。
DeepMind发表的《Training Compute-Optimal Large Language Models》这篇论文,研究了在给定计算预算下,训练Transformer语言模型的最佳模型大小和训练tokens数量。通过在5亿到5000亿个tokens上训练超过400个语言模型,作者发现模型大小和训练令牌数应该等比例扩展:模型大小每翻倍,训练令牌数也应翻倍。而现有的趋势是是增加模型大小,通常不增加训练令牌数。例如MT-NLG 530B比GPT-3 170B大了三倍,但是训练令牌数大致相同,导致训练不足,性能明显低于相同计算预算下可能实现的水平。
作者认为,在相同的计算预算下,一个在更多数据上训练的较小模型将表现更好,并训练了一个计算优化模型
Chinchilla(70B)验证了这一假设。Chinchilla(70B)其在微调和推理时使用的计算资源大大减少,极大地方便了下游应用,但是在各种下游评估任务中,性能上显著优于Gopher(280B)、GPT-3(175B)、Jurassic-1(178B)和Megatron-Turing NLG(530B)这些更大规模的模型。
- 训练参数
作者使用了AdamW优化器,并使用cosine learning rate schedule,使得最终学习率等于最大学习率的10%,设置0.1的权重衰减和1.0的梯度裁剪。warmup的step为2000,并根据模型的大小改变学习率和批处理大小:

- 高效优化
- 使用高效的因果多头注意力机制的实现来减少内存使用和运行时间,该实现可在xformers库中获得
- gradient checkpointing:使用checkpoint技术来减少在反向传播过程中需要重新计算的激活值数量。具体来说,我们保存了计算成本较高的激活值,例如线性层的输出,这是通过手动实现transformer层的backward函数来实现的,而不是依赖于PyTorch的autograd库。
- 尽可能地重叠激活值的计算和GPU之间的通信(基于all_reduce操作)
当训练一个65B参数的模型时,我们的代码在具有80GB RAM的2048个A100 GPU上每秒处理大约380个标记。这意味着在包含1.4T个标记的数据集上进行训练需要大约21天的时间。训练损失的变化参考下图:

7.1.5 主要结果
-
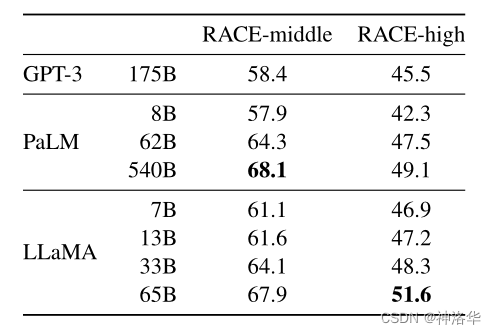
常识推理(Common Sense Reasoning)
LLaMA-65B在大多数任务中都优于Chinchilla-70B、PaLM-540B和GPT-3。

表3:在常识推理任务上的zero-shot表现 -
闭卷问答(Closed-book Question Answering)
 |
 |
|---|
- 其它任务
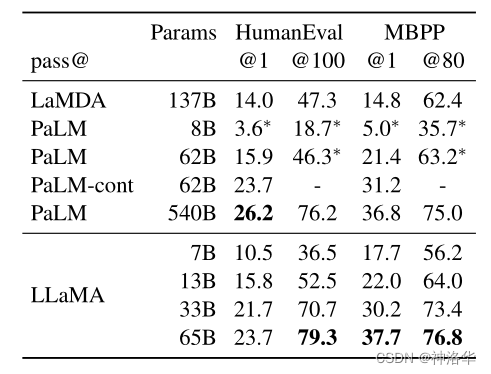 |
 |
 |
|---|---|---|
| 阅读理解 | 数学推理 | 代码生成 |
- 训练过程中的性能演变(Evolution of performance during training)
在训练过程中,我们对几个问题回答和常识推理基准进行了模型性能的跟踪,并在图2中进行了报告。在大多数基准测试中,性能稳步提高,并与模型的训练困惑度相关(参见图1)。不过,SIQA和WinoGrande是例外。特别值得注意的是,在SIQA上,我们观察到性能存在较大的变异,这可能表明该基准测试不够可靠。在WinoGrande上,性能与训练困惑度的相关性不太明显:LLaMA-33B和LLaMA-65B在训练过程中的性能相似。

- 指令调优
尽管LLaMA-65B的非微调版本已经能够遵循基本指令,但我们观察到非常少量的指令微调可以提高在MMLU上的性能,并进一步提高模型遵循指令的能力。指令微调得到的模型为LLaMA-I,在MMLU上达到了68.9%,但仍远未达到最先进的水平(MMLU上的GPT code-davincii-002为77.4)。

表10:指令微调 - MMLU(5-shot)。中等模型在MMLU上进行指令微调和不进行指令微调的比较
7.1.6 结论
本文中提出了一系列公开发布的语言模型,并实现与最先进的基础模型相竞争的结果。最值得注意的是,LLaMA-13B的性能优于GPT-3,但体积比GPT-3小10倍以上,LLaMA-65B与Chinchilla-70B和PaLM-540B竞争。
与之前的研究不同,论文的研究表明,不使用专有数据集,而只使用公开可用的数据集进行训练,可以达到最先进的性能。作者希望向研究界发布这些模型将加速大型语言模型的发展,并有助于提高它们的鲁棒性,减轻已知的问题,如毒性和偏见。
此外,作者像Chung等人一样观察到,根据指令对这些模型进行微调会产生有希望的结果计划在未来的工作中进一步研究这一点。
最后,作者计划在未来发布在更大的预训练语料库上训练的更大的模型,因为作者在扩展语料时已经看到了性能的不断提高
7.2 Alpaca(2023.3.13)
Alpaca 7B是斯坦福大学在LLaMA 7B模型上经过52K个指令跟踪示范进行微调的模型,其性能比肩GPT-3.5(text-davinci-003),但是整个训练成本不到600美元。
在8个80GB A100上训练了3个小时,不到100美元;使用OpenAI的API自动生成指令集,不到500美元
7.2.1 背景
诸如GPT-3.5(text-davinci-003)、ChatGPT、Claude和Bing Chat等指令跟踪模型(Instruction-following models)的功能越来越强大,但它们仍然存在许多问题:它们可能生成虚假信息、传播社会刻板印象并产生有害语言。为了解决这些紧迫的问题,学术界的参与非常重要。不幸的是,由于没有能够与OpenAI的text-davinci-003等闭源模型相媲美的易于获取的模型,学术界在指令跟踪模型上进行研究一直很困难。
我们发布了一种名为Alpaca的指令跟踪语言模型,该模型基于Meta的LLaMA 7B模型,其微调的52K指令集是在text-davinci-003上自我指导式生成的(generated in the style of self-instruct )。在self-instruct evaluation set上,Alpaca表现出许多与OpenAI的text-davinci-003相似的行为,但其尺寸也惊人地小,易于复制且成本低廉。
我们发布了训练配方(training recipe)和数据,并计划在将来发布模型权重。我们还提供一个交互式演示,以便研究界更好地了解Alpaca的行为。Alpaca仅供学术研究使用,禁止任何商业用途。
- alpaca_data.json:包含了我们用于对Alpaca模型进行微调的52K个指令跟随数据。这个JSON文件是一个字典列表,每个字典包含以下字段:
- instruction: str,描述模型应执行的任务。这52K个指令中的每个指令都是独特的。
- input: str,任务的可选上下文或输入。例如,当指令是“总结以下文章”时,输入是文章内容。大约40%的示例有一个输入。
- output: str,由text-davinci-003生成的指令答案。
- Data generation process:数据生成代码
- Training code:使用Hugging Face API进行微调的代码。
总结起来就是构建了self-instruct方法并通过指令微调实验证明了其有效性,发布了alpaca_data.json指令数据集,发布了Alpaca模型。评估显示,使用 SELF -INSTRUCT 对 GPT3 进行调整的性能明显优于使用现有的公共指令数据集,并且与 InstructGPT 001 的性能表现接近。
7.2.2 self-instruct 概述
在一定的预算下训练高质量的指令跟踪模型面临两个重要挑战:一个是强大的预训练语言模型,另一个是高质量的指令跟踪数据。前者通过Meta最近发布的LLaMA模型得到解决,后者可以通过现有的强大语言模型自动生成指令数据来解决,即self-instruct半自动化方法。
该方法通过使用一个小的任务种子集作为任务池,从中随机选择任务来生成指令数据集。生成的数据经过过滤和筛选后,可以用于对语言模型进行指令调优,以提高其遵循指令的能力。
本文采用175个人工编写的instruction-output pairs作为种子池,指示模型(text-davinci-003)创造更广泛的指令集,每个pais都包含[指令, 输入, 输出]或[指令, 输出]。生成流程如下:
- 使用模型生成新的指令,用于定义任务(通常是新的);
- 对该模型生成的指令判断是否分类任务;
- 使用模型生成输入-输出实例,这些实例可以后续用于指令微调;
- 对上述模型生成的数据进行过滤和后处理;
最后将经过过滤和后处理的数据添加到种子池中;一直重复上述步骤直到种子池有足够多的数据。通过简化生成流程(详见GitHub)大大降低成本,使得用OpenAI API生成52K指令集的成本不到500美元。

在这个生成的数据上,我们对GPT3进行微调(即使用生成指令数据时使用的相同模型)构建了GPT3 SELF-INST。评估结果表明,在SUPER NI(典型NLP任务)上GPT3 SELF-INST的性能大幅超过GPT3(原始模型)(+33.1%),并几乎与InstructGPT 001的性能相当;在广泛的指令遵循能力上,与InstructGPT 001之间存在5%的差距。
我们还使用Hugging Face的训练框架对LLaMA模型进行了微调,利用了Fully Sharded Data Parallel和混合精度训练等技术,在8个80GB的A100上花费了3个小时,成本不到100美元。
7.2.3 self-instruct 方法
一般的,指令数据集中的一条数据包含(指令, 输入, 输出)这三部分,例如:
指令:写一篇关于以下主题的文章
输入:校园安全
输出:校园安全是学校必须高度重视的问题,涉及到师生的生命财产安全。建立安全意识,制定严格的规章制度,加强安全巡查和应急预案,是确保校园安全的关键。
不过很多时候"指令"和"输入"划分的不是那么清晰,例如上面也可以写成:
指令:写一篇以校园安全为主题的文章
输出:校园安全是学校必须高度重视的问题,涉及到师生的生命财产安全。建立安全意识,制定严格的规章制度,加强安全巡查和应急预案,是确保校园安全的关键。
所以指令数据集中的一条数据可能包含三部分(指令, 输入, 输出),也可能只有两部分(指令, 输出)。
- 生成指令
生成指令时,先从种子池中随机抽取6个人工编写的指令,再随机抽取2个之前步骤中模型生成的指令,总共8个指令。以如下表的模版格式组织之后,输入给模型,让模型输出一个新的指令。

- 判断指令是否属于分类任务:在根据指令生成实例时,分类任务与非分类任务使用的prompt模版是不同的,下一点会详细讲解。
判断方法:在种子池中随机挑选12条分类指令和19条非分类指令,然后加上新生成的指令,以下表7的模版格式组织之后,输入给模型,让模型输出新生成的指令是否分类任务。

- 生成实例
在给定指令之后,生成(输入, 输出)这个实例对时还有两种策略:
Input-first:输入优先策略,先生成输入,后生成输出。Output-first:输出优先策略,常用于分类任务。
输入优先的方式在生成输入时,偏向于只生成一个标签,尤其是指令对应着分类任务时,其输入里面偏向于只生成一个类别。输出优先就是为了一定程度上缓解该问题。
指令数据集的丰富度我们是希望越丰富越好,所以允许出现一个指令,多个输入的数据。
-
输入优先:在种子池中随机抽取 k 条数据,以如下的prompt模版的形式组合之后,输入给模型,让模型为最后的指令生成相应的实例。

-
输出优先:在种子池中随机抽取 k 条在之前的步骤中已经标记为分类的数据,以如下的prompt模版的形式组合之后,输入给模型,让模型为最后的指令生成相应的实例。

- 过滤及后处理
- 为了数据的多样性,新生成的指令只有与种子池中的指令的 ROUGE-L 小于0.7时才会添加进入种子池;
- 排除一些无法被语言模型处理的指令,比如涉及图像、图片、图形的指令;
- 在给指令生成实例时,会过滤掉输入相同但是输出不同的实例
7.2.5 alpaca_data.json指令集分析
- 统计信息
下表描述了生成数据的基本统计信息。在过滤后,我们生成了总计超过52K个指令和82K多个对应这些指令的实例。

- 数据质量
评估方式:随机抽取200条指令,并给每个指令随机抽取一个实例,然后人工对该指令和实例进行标注评估,评估结果如下表2所示。

- 生成的指令有含义,能表示一个任务的占比为92%;
- 给每个指令生成合适的输入的占比为79%;
- 生成的输出是指令和输入的正确结果的占比为58%;
- 指令、输入、输出,这三个字段全对的占比为54%;
7.2.6 实验结果
- SUPER NI benchmark:Self-Instruct能够给GPT3模型带来33.1%的巨大的提升,效果接近
InstructGPT 001

表格3:在来自SUPER NI)的未见任务上的评估结果

- 新新测评数据集SUPERNI。
为了更好的测试本文中提出的方法训练出的模型在给用户使用时的效果。本文设计了一份新的更贴近普通用户的数据集(252条指令,每个指令一个实例),在该数据集上测试Self-Instruct的效果。在设计这个数据集时考虑到的有:
- 不同的领域:邮件写作、社交媒体、生产力工具、娱乐、编程等;
- 形式上:可以是(指令, 输入, 输出),也可以是(指令, 输出);
- 指令有的长、有的短,输入/输出中包含项目符号、表格、代码、方程等;
评估方式是人工对模型的输出结果做打分,评分A最好,评分D最差。在下图5中的颜色对应着绿色最好,红色最差。

结果显示:

7.3 Alpaca-LoRA
请参见我的下一篇文章
7.4 Chinese-LLaMA-Alpaca
请参见我的下一篇文章
八、 LLM系列之底座模型对比
-
LLama:
- 使用
RMSNorm[GPT3]对输入数据进行标准化,参考论文:Root mean square layer normalization; - 使用激活函数
SwiGLU [PaLM], 参考PALM论文:Glu variants improve transformer; - 使用
Rotary Embeddings进行位置编码[GPTNeo],参考论文 Roformer: Enhanced transformer with rotary position embedding; - 使用了AdamW优化器,并使用cosine learning rate schedule;
- 使用因果多头注意的有效实现来减少内存使用和运行时间(xformers库实现)
- 使用
-
Palm
SwiGLU激活函数:用于 MLP 中间激活,采用SwiGLU激活函数:用于 MLP 中间激活,因为与标准 ReLU、GELU 或 Swish 激活相比,《GLU Variants Improve Transformer》论文里提到:SwiGLU 已被证明可以显著提高模型效果Parallel Layers:每个 Transformer 结构中的“并行”公式:与 GPT-J-6B 中一样,使用的是标准“序列化”公式。并行公式使大规模训练速度提高了大约 15%。消融实验显示在 8B 参数量下模型效果下降很小,但在 62B 参数量下没有模型效果下降的现象。Multi-Query Attention:每个头共享键/值的映射,即“key”和“value”被投影到 [1, h],但“query”仍被投影到形状 [k, h],这种操作对模型质量和训练速度没有影响,但在自回归解码时间上有效节省了成本。RoPE embeddings:使用的不是绝对或相对位置嵌入,而是RoPE,是因为 RoPE 嵌入在长文本上具有更好的性能 ,Shared Input-Output Embeddings:输入和输出embedding矩阵是共享
-
GLM
- Layer Normalization的顺序和残差连接被重新排列,
- 使用单个线性层来进行输出Token预测
ReLU激活函数替换为GELU- 采用二维位置编码
-
BLOOM
- 使用
ALiBi位置嵌入,它根据键和查询的距离直接衰减注意力分数。 与原始的 Transformer 和 Rotary 嵌入相比,它可以带来更流畅的训练和更好的下游性能。ALiBi不会在词嵌入中添加位置嵌入;相反,它会使用与其距离成比例的惩罚来偏向查询键的注意力评分。图片 Embedding Layer Norm:嵌入层归一化。在嵌入层后添加了额外的层归一化层,显著提高了训练的稳定性。- 使用了 25 万个标记的词汇表。 使用字节级 BPE,解码时永远不会产生未知标记。
- 使用
两个全连接层:图片
- GPT
GPT 使用 Transformer Decoder 结构,但是去掉了第二个 Mask Multi-Head Attention层。