链式法则求导
标量对一个列向量求导,结果为一个行向量
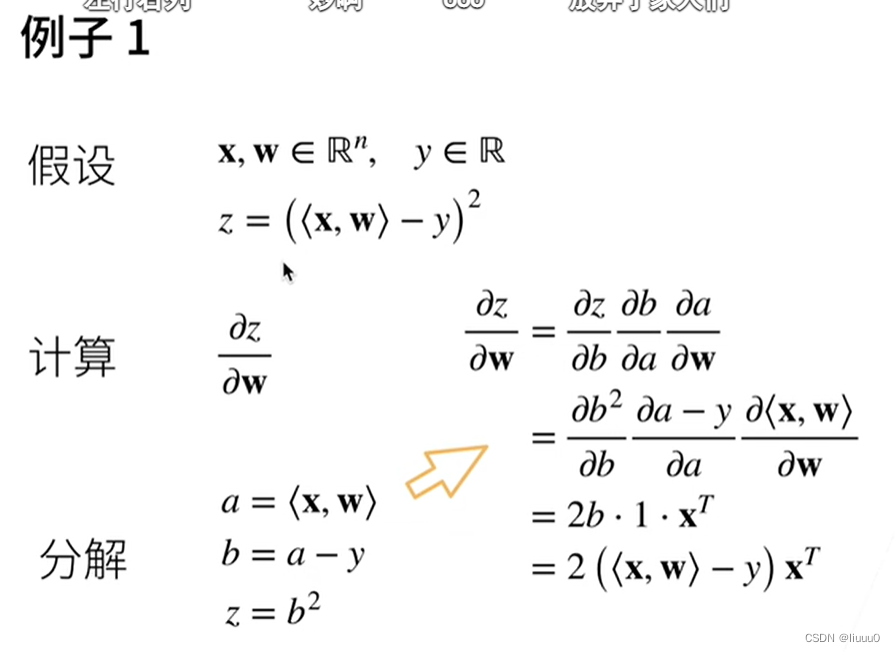

自动求导
计算图
将代码分解成操作子
将计算表示为一个无环图
显示构造:Tensorflow/Theano/MXNet
隐式构造:PyTorch/MXNet

自动求导的两种模式(正向积累、反向传递)

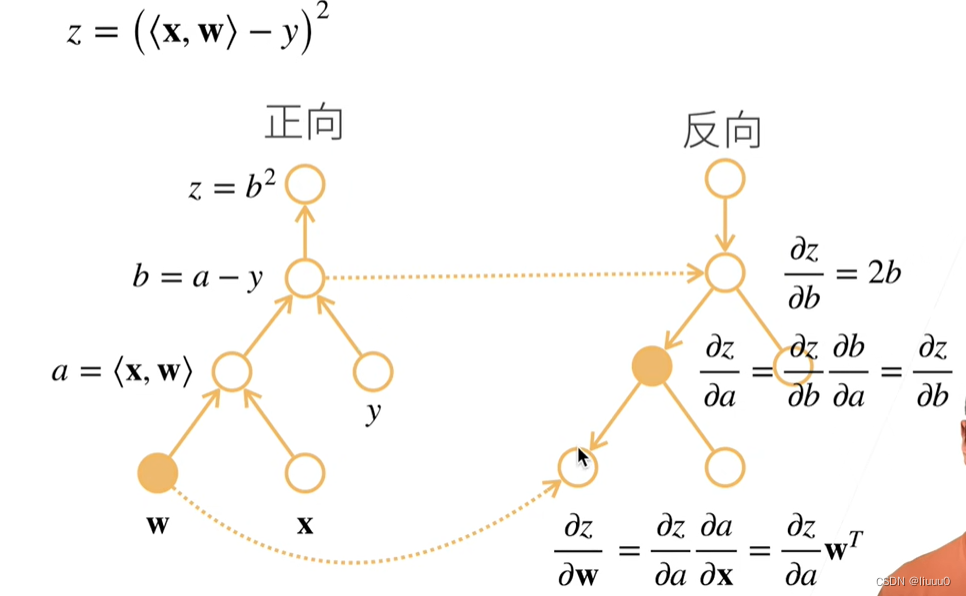
反向积累
构造计算图
前向:执行图,存储中间结果
反向:从相反方向执行图,需要的值去正向处理那里拿。不需要求的导数就不用计算了
复杂度
计算复杂度:正向与反向代价类似
内存复杂度:正向 > 反向(需要存储正向所有的中间结果,耗费gpu的根源)
自动求导实现
import torch
# 对函数y=2xTx关于列向量x求导
x = torch.arange(4.0) # tensor([0., 1., 2., 3.])
# 需要一个地方来存储梯度
x.requires_grad_(True) # 等价于 x = torch.arange(4.0,requires_grad=True)
print(x.grad) # 默认值为None
# 计算y
y = 2 * torch.dot(x,x) # dot就是对应元素相乘再相加
print(y) # tensor(28., grad_fn=<MulBackward0>)
# 通过调用反向传播函数来自动计算y关于x的每个分量的梯度
y.backward()
print(x.grad) # tensor([ 0., 4., 8., 12.])
# 检验自动求导结果与手动计算结果
print(x.grad == 4*x) # tensor([True, True, True, True])
########### 计算x的另一个函数 ##########
x.grad.zero_() # 默认情况下,PyTorch会累积梯度,所以需要清除之前的
y = x.sum()
y.backward()
print(x.grad) # tensor([1., 1., 1., 1.]) y是对向量x中的四个分量求和,x.grad是对四个分量分别求偏导
########### 深度学习中,目的是计算批量中每个样本单独计算的偏导数之和
# 将某些计算移动到记录的计算图之外
x.grad.zero_()
y = x * x
u = y.detach() # 去除y的值,y不再是一个函数,而是一个标量
z = u * x
z.sum().backward()
print(x.grad == u) # tensor([True, True, True, True])
QA互动
Q1:隐式构造和显式构造
显式构造是先把计算写出来,再去赋值(构造使用不方便)
Q2:Pytorch默认累积梯度,好处是?
当要计算的输入数据量太大时,就可以进行分批量计算,把每个批量计算的梯度累积起来,就可以得到最终的梯度
Q3:为什么深度学习中一般是对标量求导而不是对矩阵或向量求导?
因为loss通常是一个标量。如果loss是一个向量或矩阵,那么在求导时,随着神经网络的加深,张量越来越大
Q4:多个loss分别反向的时候是否需要累积梯度?
是。多个损失函数也要做累加操作