1. AlexNet
1.1 AlexNet概要
如果你和机器学习研究人员交谈,你会发现他们相信机器学习既重要又美丽:优雅的理论去证明各种模型的性质。机器学习是一个正在蓬勃发展、严谨且非常有用的领域。然而,如果你和计算机视觉研究人员交谈,你会听到一个完全不同的故事。他们会告诉你图像识别的诡异事实————推动领域进步的是数据特征,而不是学习算法。计算机视觉研究人员相信**,从对最终模型精度的影响来说,更大或更干净的数据集、或是稍微改进的特征提取,比任何学习算法带来的进步要大得多。**
2012年,AlexNet(作者:Alex Krizhevsky、Ilya Sutskever和Geoff Hinton)横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
在网络的最底层(靠近输入层的卷积层),模型学习到了一些类似于传统滤波器的特征抽取器比如边缘、颜色和纹理等特征,比如下图所示。

AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征,如眼睛、鼻子、草叶等等。而更高的层可以检测整个物体,如人、飞机、狗或飞盘。最终的隐藏神经元可以学习图像的综合表示,从而使属于不同类别的数据易于区分。
1.2 AlexNet架构
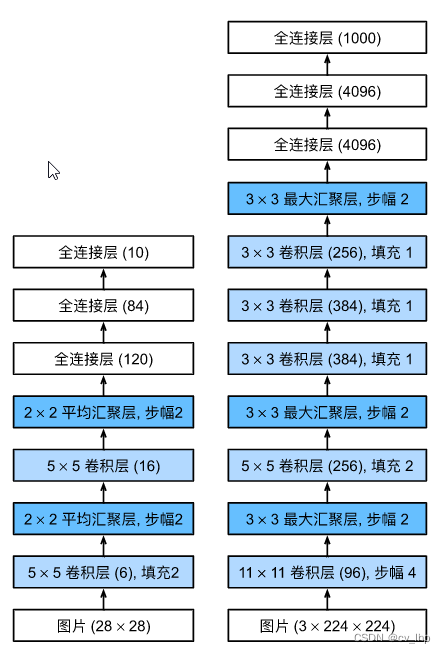
AlexNet和LeNet的设计理念和架构非常相似,但也存在显著差异。 首先,AlexNet比相对较小的LeNet5要深得多。 AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层(为三个全连接层)并且每个全连接层后面加入了Dropout()丢弃层,LeNet由五层组成:两个卷积层和三个全连接层。 其次,AlexNet使用ReLU而不是sigmoid作为其激活函数,AlexNet使用MaxPool2d()池化层,而LeNet使用AvgPool2d()池化层,如下图所示。
1.3 模型设计
在AlexNet的第一层,卷积窗口的形状是 11×11 。 由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。 第二层中的卷积窗口形状被缩减为 5×5 ,然后是 3×3 。 此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为 3×3 、步幅为2的最大汇聚层。 而且,AlexNet的卷积通道数目是LeNet的十几倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。特别注意:三个全连接层总共有64004096+40964096+4096*10个参数,因此三个全连接层的所有参数占了整个AlexNet模型参数的一大部分(卷积层的权重参数其实很少,因为卷积核的权重参数会进行共享,有效地大量减少了模型的参数),因此也是在AlexNet计算中也是占大部分,也会占用GPU显存的大部分。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。 幸运的是,现在GPU显存相对充裕,所以我们现在很少需要跨GPU分解模型(因此,我们的AlexNet模型在这方面与原始论文稍有不同)。
1.4 激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
1.5 容量控制和预处理
AlexNet通过暂退法( :numref:sec_dropout)控制全连接层的模型复杂度,而LeNet只使用了权重衰减。 为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。
1.6 AlexNet模型全部代码
尽管论文中AlexNet是在ImageNet上进行训练的,但我们在这里使用的是Fashion-MNIST数据集。因为即使在现代GPU上,训练ImageNet模型,同时使其收敛可能需要数小时或数天的时间。 将AlexNet直接应用于Fashion-MNIST的一个问题是:Fashion-MNIST图像的分辨率( 28×28 像素)(低于ImageNet图像。 为了解决这个问题,我们将它们增加到 224×224 (通常来讲这不是一个明智的做法,但我们在这里这样做是为了有效使用AlexNet架构。 我们使用d2l.load_data_fashion_mnist() 函数中的resize参数执行此调整。
与LeNet相比,训练AlexNet模型主要变化是需要使用更小的学习速率训练,这是因为网络更深更广、图像分辨率更高,因此导致训练AlexNet网络就更耗时也更昂贵(需要更多GPU来进行训练)。
import d2l.torch
import torch
from torch import nn
#定义AlexNet模型
AlexNet = nn.Sequential(nn.Conv2d(in_channels=1,out_channels=96,kernel_size=11,stride=4),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2),
nn.Flatten(),
nn.Linear(in_features=6400,out_features=4096),nn.ReLU(),nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=4096),nn.ReLU(),nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=10))
X = torch.randn(size=(1,1,224,224))
#构造一个高度和宽度都为224的单通道数据,来观察AlexNet每一层输出的形状大小
for layer in AlexNet:
X = layer(X)
print(layer.__class__.__name__,"output shape: \t",X.shape)
batch_size = 128
train_iter,test_iter = d2l.torch.load_data_fashion_mnist(batch_size=batch_size,resize=224)
lr,num_epochs = 0.03,20
#训练模型并在测试数据集上面测试
d2l.torch.train_ch6(AlexNet,train_iter,test_iter,num_epochs,0.03,d2l.torch.try_gpu())#跟LeNet模型训练函数train_LeNet()一样,这里只是把这个函数封装在d2l.torch里面,方便后面调用
'''
每一层输出形状大小结果如下:
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
'''
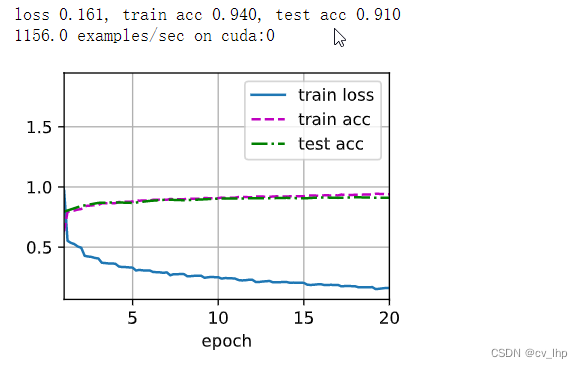
AlexNet模型训练结果和测试结果如下图所示(学习率lr为0.03,训练轮数epochs为20轮):
1.7 小结
- AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
- 今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
- 尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。
- Dropout、ReLU和预处理(使用了大量的图像增强数据达到数据集扩增,更大的数据集样本量使得模型更健壮,有效地减少了模型的过拟合)是提升计算机视觉任务性能的其他关键步骤。