1.下载requests库
打开pycharm点击控制台
再控制台中输入pip install requests下载requests库
pip install requests
successfully表示安装成功
2.编写爬虫
选择网页获取url
我们选择百度首页复制网页url
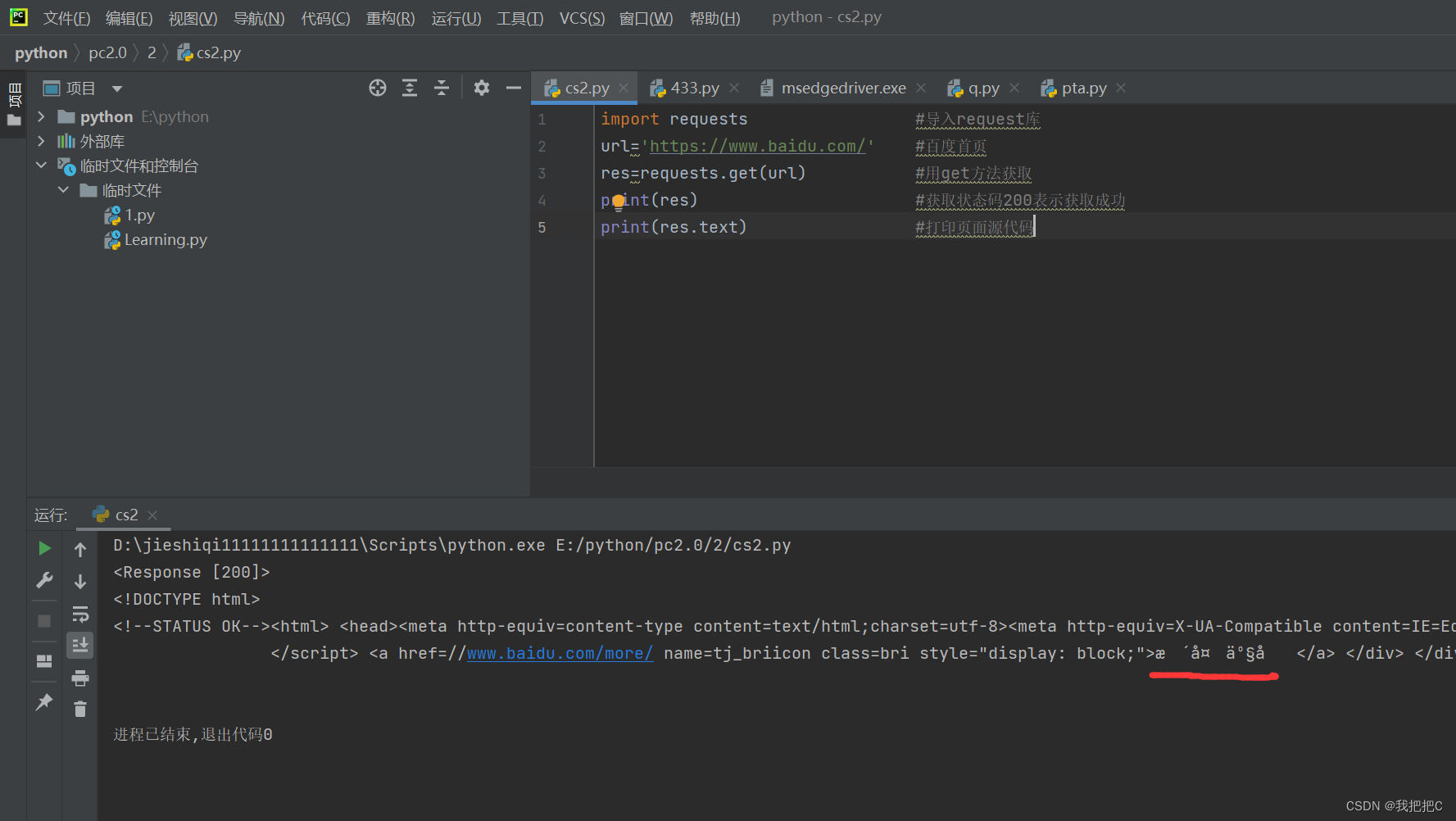
import requests #导入request库
url='https://www.baidu.com/' #百度首页
res=requests.get(url) #用get方法发送请求
print(res) #获取状态码200表示获取成功
print(res.text) #打印页面源代码
打开百度首页F12查看页面源代码

可以看到虽然我们成功获取了页面源代码但是返回结果中会出现中文乱码我们需要对返回的数据进行编码
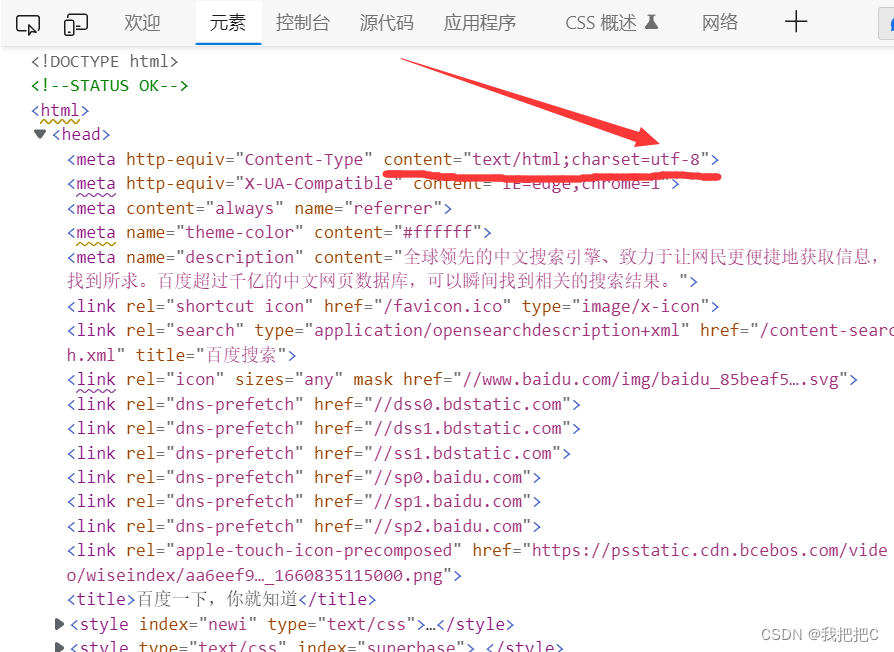
查看页面源代码发现编码格式为’utf-8’我们将返回的数据按utf-8进行编码
编码和解码请参考: Python 中的编码与解码(encoding和decoding)
import requests #导入request库
url='https://www.baidu.com/' #百度首页
res=requests.get(url) #用get方法发送请求
print(res) #获取状态码200表示获取成功
res.encoding='utf-8' #对返回的数据编码
print(res.text) #打印页面源代码
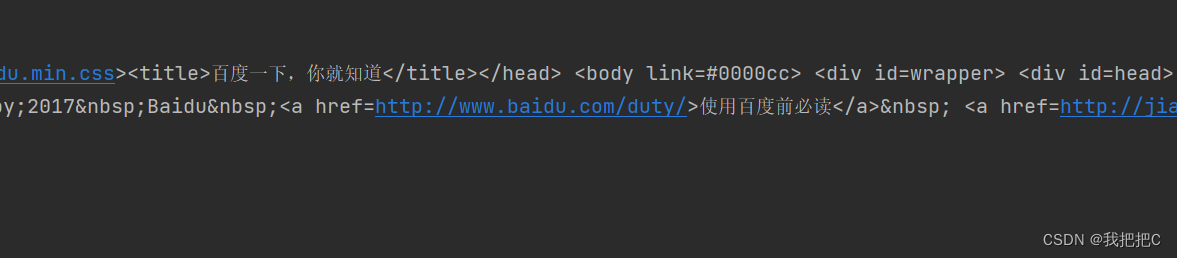
返回的数据中文乱码已解决成功获取页面源代码