一、用requests库的get()函数访问必应主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。
代码如下:
import requests for i in range(20): r = requests.get("http://www.google.cn",timeout=30) print("状态 = {}".format( r.status_code)) print("text编码方式 = {}".format(r.encoding)) print("text属性 = {}".format(r.text)) print("二进制形式 = {}".format(r.content))
这是访问一次的结果:
状态 = 200
text编码方式 = ISO-8859-1
text内容 = <!DOCTYPE html>
<html lang="zh">
<meta charset="utf-8">
<title>Google</title>
<style>
html { background: #fff; margin: 0 1em; }
body { font: .8125em/1.5 arial, sans-serif; text-align: center; }
h1 { font-size: 1.5em; font-weight: normal; margin: 1em 0 0; }
p#footer { color: #767676; font-size: .77em; }
p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; }
ul { margin: 2em; padding: 0; }
li { display: inline; padding: 0 2em; }
div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; }
div:hover, div:hover * { cursor: pointer; }
div:hover { border-color: #999; }
div p { margin: .5em 0 1.5em; }
img { border: 0; }
</style>
<div>
<a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp">
<img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257">
</a>
<h1><a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp"><strong id="target">google.com.hk</strong></a></h1>
<p>请æ¶èæ们çç½å
</div>
<ul>
<li><a href="http://translate.google.cn/?sourceid=cnhp">ç¿»è¯</a>
</ul>
<p id="footer">©2011 - <a href="http://www.miibeian.gov.cn/">ICPè¯ååB2-20070004å·</a>
<script nonce="6ITAIsTQoV0sDDa8Sw1U2g">
var gcn=gcn||{};gcn.IS_IMAGES=(/images\.google\.cn/.exec(window.location)||window.location.hash=='#images'||window.location.hash=='images');gcn.HOMEPAGE_DEST='http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp';gcn.IMAGES_DEST='http://images.google.com.hk/imghp?'+'hl=zh-CN&sourceid=cnhp';gcn.DEST_URL=gcn.IS_IMAGES?gcn.IMAGES_DEST:gcn.HOMEPAGE_DEST;gcn.READABLE_HOMEPAGE_URL='google.com.hk';gcn.READABLE_IMAGES_URL='images.google.com.hk';gcn.redirectIfLocationHasQueryParams=function(){if(window.location.search&&/google\.cn/.exec(window.location)&&!/webhp/.exec(window.location)){window.location=String(window.location).replace('google.cn','google.com.hk')}}();gcn.replaceHrefsWithImagesUrl=function(){if(gcn.IS_IMAGES){var a=document.getElementsByTagName('a');for(var i=0,len=a.length;i<len;i++){if(a[i].href==gcn.HOMEPAGE_DEST){a[i].href=gcn.IMAGES_DEST}}}}();gcn.listen=function(a,e,b){if(a.addEventListener){a.addEventListener(e,b,false)}else if(a.attachEvent){var r=a.attachEvent('on'+e,b);return r}};gcn.stopDefaultAndProp=function(e){if(e&&e.preventDefault){e.preventDefault()}else if(window.event&&window.event.returnValue){window.eventReturnValue=false;return false}if(e&&e.stopPropagation){e.stopPropagation()}else if(window.event&&window.event.cancelBubble){window.event.cancelBubble=true;return false}};gcn.resetChildElements=function(a){var b=a.childNodes;for(var i=0,len=b.length;i<len;i++){gcn.listen(b[i],'click',gcn.stopDefaultAndProp)}};gcn.redirect=function(){window.location=gcn.DEST_URL};gcn.setInnerHtmlInEl=function(a){if(gcn.IS_IMAGES){var b=document.getElementById(a);if(b){b.innerHTML=b.innerHTML.replace(gcn.READABLE_HOMEPAGE_URL,gcn.READABLE_IMAGES_URL)}}};
gcn.listen(document, 'click', gcn.redirect);
gcn.setInnerHtmlInEl('target');
</script>
二进制形式 = b'<!DOCTYPE html>\n<html lang="zh">\n <meta charset="utf-8">\n <title>Google</title>\n <style>\n html { background: #fff; margin: 0 1em; }\n body { font: .8125em/1.5 arial, sans-serif; text-align: center; }\n h1 { font-size: 1.5em; font-weight: normal; margin: 1em 0 0; }\n p#footer { color: #767676; font-size: .77em; }\n p#footer a { background: url(//www.google.cn/intl/zh-CN_cn/images/cn_icp.gif) top right no-repeat; padding: 5px 20px 5px 0; }\n ul { margin: 2em; padding: 0; }\n li { display: inline; padding: 0 2em; }\n div { -moz-border-radius: 20px; -webkit-border-radius: 20px; border: 1px solid #ccc; border-radius: 20px; margin: 2em auto 1em; max-width: 650px; min-width: 544px; }\n div:hover, div:hover * { cursor: pointer; }\n div:hover { border-color: #999; }\n div p { margin: .5em 0 1.5em; }\n img { border: 0; }\n </style>\n <div>\n <a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp">\n <img src="//www.google.cn/landing/cnexp/google-search.png" alt="Google" width="586" height="257">\n </a>\n <h1><a href="http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp"><strong id="target">google.com.hk</strong></a></h1>\n <p>\xe8\xaf\xb7\xe6\x94\xb6\xe8\x97\x8f\xe6\x88\x91\xe4\xbb\xac\xe7\x9a\x84\xe7\xbd\x91\xe5\x9d\x80\n </div>\n <ul>\n <li><a href="http://translate.google.cn/?sourceid=cnhp">\xe7\xbf\xbb\xe8\xaf\x91</a>\n </ul>\n <p id="footer">©2011 - <a href="http://www.miibeian.gov.cn/">ICP\xe8\xaf\x81\xe5\x90\x88\xe5\xad\x97B2-20070004\xe5\x8f\xb7</a>\n <script nonce="6ITAIsTQoV0sDDa8Sw1U2g">\n var gcn=gcn||{};gcn.IS_IMAGES=(/images\\.google\\.cn/.exec(window.location)||window.location.hash==\'#images\'||window.location.hash==\'images\');gcn.HOMEPAGE_DEST=\'http://www.google.com.hk/webhp?hl=zh-CN&sourceid=cnhp\';gcn.IMAGES_DEST=\'http://images.google.com.hk/imghp?\'+\'hl=zh-CN&sourceid=cnhp\';gcn.DEST_URL=gcn.IS_IMAGES?gcn.IMAGES_DEST:gcn.HOMEPAGE_DEST;gcn.READABLE_HOMEPAGE_URL=\'google.com.hk\';gcn.READABLE_IMAGES_URL=\'images.google.com.hk\';gcn.redirectIfLocationHasQueryParams=function(){if(window.location.search&&/google\\.cn/.exec(window.location)&&!/webhp/.exec(window.location)){window.location=String(window.location).replace(\'google.cn\',\'google.com.hk\')}}();gcn.replaceHrefsWithImagesUrl=function(){if(gcn.IS_IMAGES){var a=document.getElementsByTagName(\'a\');for(var i=0,len=a.length;i<len;i++){if(a[i].href==gcn.HOMEPAGE_DEST){a[i].href=gcn.IMAGES_DEST}}}}();gcn.listen=function(a,e,b){if(a.addEventListener){a.addEventListener(e,b,false)}else if(a.attachEvent){var r=a.attachEvent(\'on\'+e,b);return r}};gcn.stopDefaultAndProp=function(e){if(e&&e.preventDefault){e.preventDefault()}else if(window.event&&window.event.returnValue){window.eventReturnValue=false;return false}if(e&&e.stopPropagation){e.stopPropagation()}else if(window.event&&window.event.cancelBubble){window.event.cancelBubble=true;return false}};gcn.resetChildElements=function(a){var b=a.childNodes;for(var i=0,len=b.length;i<len;i++){gcn.listen(b[i],\'click\',gcn.stopDefaultAndProp)}};gcn.redirect=function(){window.location=gcn.DEST_URL};gcn.setInnerHtmlInEl=function(a){if(gcn.IS_IMAGES){var b=document.getElementById(a);if(b){b.innerHTML=b.innerHTML.replace(gcn.READABLE_HOMEPAGE_URL,gcn.READABLE_IMAGES_URL)}}};\n gcn.listen(document, \'click\', gcn.redirect);\n gcn.setInnerHtmlInEl(\'target\');\n </script>\n'
二、这是一个简单的html页面,请保持字符串,完成后面的计算要求。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id=first>我的第一个段落。</p > </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
a.打印head标签内容和学号后两位
b.获取body标签的内容
c.获取id为first的标签对象
d.获取并打印html页面中的中文字符
代码如下:

import requests from bs4 import BeautifulSoup soup = BeautifulSoup("<!DOCTYPE html><html><head><meta charset=‘utf-8‘>\ <title菜鸟教程(rounoob.com)</title></head><body>\ <h1>我的第一标题</h1>\ <p id='first'>我的第一个段落。</p></body>\ <table border=‘1‘><tr><td>row 1,cell 1\ </td><td>row 1,cell 2</td></tr><tr><td>row 2,cell 1\ </td><td>row 2,cell 2</td></tr</table></html>") print(soup.head,"39") #获取并打印head标签的内容和学号后两位 print(soup.body) #获取并打印body的内容 print(soup.find_all(id="first")) #获取并打印id为first的文本 print(soup.h1.string,soup.p.string) #获取并打印html页面中的中文字符
结果如下:

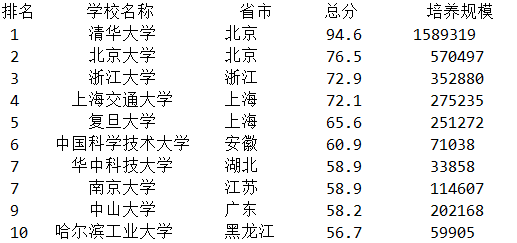
三、爬取中国大学排名2019
代码如下:
import requests from bs4 import BeautifulSoup allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding='utf-8' return r.text except: return "" def fillUnivList(soup): data=soup.find_all('tr') for tr in data: ltd=tr.find_all('td') if len(ltd)==0: continue singleUniv=[] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养规模")) for i in range(num): u=allUniv[i] print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288),u[0],u[1],u[2],u[3],u[6])) def main(num): url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html' html=getHTMLText(url) soup=BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(10)
运行结果如下: