爬虫的任务就是两件事:请求网页和解析提取信息
爬虫三大库 Requests Lxml BeautifulSoup
Requests库:请求网站获取网页数据
import requests #from bs4 import BeautifulSoup headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"} res=requests.get("http://bj.xiaozhu.com/",headers=headers) #soup = BeautifulSoup(res.text, 'html.parser') try: #price=soup.select("#page_list > ul > li > div.result_btm_con.lodgeunitname > div > span > i") print(res) print(res.text) #print(soup.prettify()) #print(price) except ConnectionError: print("拒绝连接")
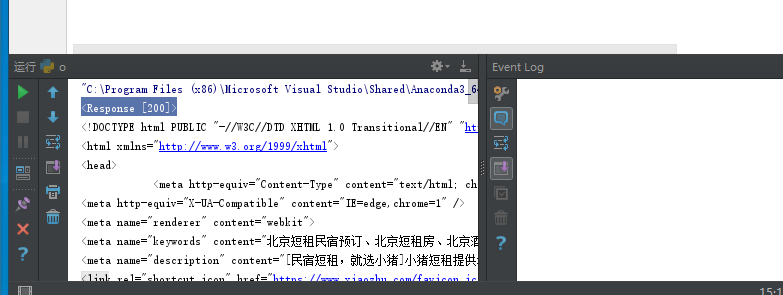
其中<Response [200]>表示请求网页成功
User-Agent可以通过http://www.user-agent.cn/ 查看
请求头
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"}
为get()方法加入请求头
res=requests.get("http://bj.xiaozhu.com/",headers=headers)
post()方法用于提交表单来爬取需要登录才能获得数据的网站
BeautifulSoup库:轻松的解析Requests库请求的网页,并把网页源码解析为Soup文档,以便过滤提取数据
import requests from bs4 import BeautifulSoup headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"} res=requests.get("http://bj.xiaozhu.com/",headers=headers) soup = BeautifulSoup(res.text, 'html.parser') print(soup.prettify())
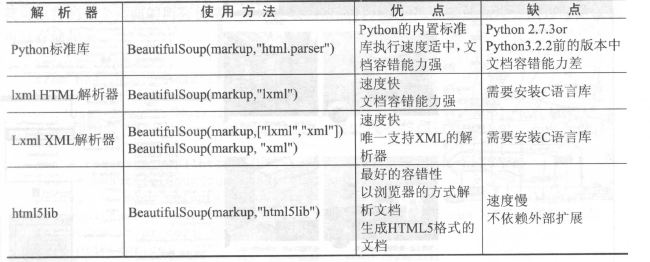
BeautifulSoup库主要解析器的优缺点
Soup文档可以使用find() find_all() selector()定位需要的元素
例子
import requests from bs4 import BeautifulSoup headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"} res=requests.get("http://bj.xiaozhu.com/",headers=headers) soup = BeautifulSoup(res.text, 'html.parser') try: price=soup.select("#page_list > ul > li > div.result_btm_con.lodgeunitname > div > span > i") #print(res) #print(res.text) #print(soup.prettify()) print(price) except ConnectionError: print("拒绝连接")
其中li:nth-child(1)在Python运行时会报错需要改为 li:nth-of-type(1).
也可以使用 get_text()方法获取中间的文字消息。