编者按:目前大语言模型主要问答、对话等场景,进行被动回答。是否可以将大模型应用于推荐系统,进行主动推送呢?
这篇文章回顾了可以将大模型作为推荐系统的理论基础,并重点描述了基于英文和阿拉伯语的购物数据集微调T5-large模型,探索将LLMs用作推荐系统的实践。同时本文还介绍了LLMs作为推荐系统的优点和缺点,并提出建议和可行的方向。
以下是译文,Enjoy!
作者 | Mohamad Aboufoul
编译 | 岳扬
最近几个月,大型语言模型(LLMs)已经成为数据科学社区和新闻界的热门话题。自2017年Transformer架构问世以来,我们看到这些语言模型处理的自然语言任务复杂程度呈指数级增长。这些任务包括分类、意图和情感抽取,甚至它们被要求生成与人类自然语言相似的文本内容。
从应用角度来看,将LLMs与现有技术相结合,如果能够避免它们的缺陷(我最喜欢的组合是GPT + Wolfram Alpha[1],可用于处理数学和符号推理问题),那么其发展潜力似乎是无限的。
令我惊讶的是,LLMs即使在没有进行额外的特征工程或手动流程的情况下,也能作为独立的推荐系统使用。这种能力很可能是由于LLMs的预训练方式和操作方式。
内容提纲:
- 回顾LLMs以及Transformers的工作原理
- LLMs作为推荐系统
- 使用自定义数据实现/复制 P5
- 尝试用非英语的数据进行模型复制
- LLMs作为推荐系统的优点和缺点
- Final Thoughts 最后的思考
- Code 源代码
01 回顾LLMs以及Transformers的工作原理
语言模型本质上是概率模型,通过映射一系列tokens(如短语、句子中的单词)的概率来完成任务。它们在大量文本上进行训练,并相应地得出概率分布。对于可以处理的各种任务(如摘要、问答),它们使用条件概率反复迭代来选择最有可能的token/单词来完成任务。请参见以下示例:根据上下文的后续令牌概率示例(作者提供的图像)
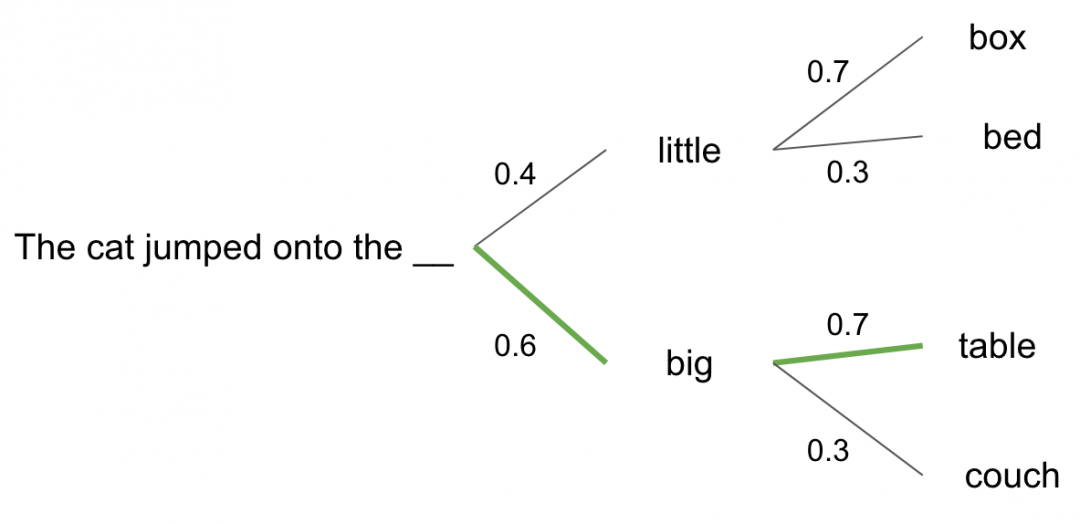
根据上下文的后续tokens概率示例图(作者提供的图像)
LLM是一种语言模型,它使用大量的计算资源和大型计算架构训练海量文本。LLMs通常采用Transformer结构,该结构由Google在其2017年的著名论文“Attention Is All You Need[2]”中公布。Transformer利用“自注意力”[3]机制,在预训练过程中允许模型学习不同token之间的关系。
在对足够大的文本集进行预训练后,相似的单词会有相似的嵌入(例如:“King”、“Monarch”),而不相似的单词将拥有更不同的嵌入(embeddings) 。此外,通过这些嵌入,我们可以看到单词之间的代数映射,使模型能够更好地确定序列的下一个正确的token。
这类似于Word2Vec中的“King - Man + Woman = Queen”[4]的经典示例。
自注意力嵌入(self-attention embeddings) 的另一个好处是,它们将因其周围的单词而异,从而使它们更符合语境中的含义。
斯坦福大学的Christopher Manning博士对LLM的工作原理进行了不错的概述。
02 LLMs作为推荐系统
2022年,来自罗格斯大学(Rutgers University)的研究人员发表了题为“Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) ”(作者:Geng等人)的论文。他们在文中介绍了一种“灵活而统一的text-to-text范式”,将多个推荐任务合并到了单个系统(P5)中。该系统可以通过自然语言序列(natural language sequences)执行以下操作:
● 序列推荐(Sequential recommendation)
● 评分预测(Rating prediction)
● 生成解释(Explanation generation)
● 评论摘要(Review summarization)
● 直接推荐(Direct recommendation)
让我们来看一下论文中的序列推荐任务的一个例子。
Input: "I find the purchase history list of user_15466:
4110 -> 4467 -> 4468 -> 4472
I wonder what is the next item to recommend to the user. Can you help
me decide?"
Output: “1581”
研究人员为用户和每个物品分配了唯一的ID。使用包含数千个用户(及其购买历史记录)和独特物品的训练集,LLM能够学习到某些物品彼此是相似的,某些用户对某些物品有偏好(由于自注意力机制的特性)。在这些购买序列(purchase sequences)的预训练过程中,模型实质上经历了一种协同过滤(collaborative filtering)[5]的形式。模型可以看到哪些用户购买了相同的物品,以及哪些物品往往会一起购买。再加上LLM生成上下文嵌入(contextual embeddings)的能力,就可以得到一个非常强大的推荐系统。
在上面的例子中,虽然我们不知道每个ID对应哪个物品,但我们可以推断出物品“1581”是由其他用户与“user_15466”已经购买的任何物品一起购买的。
关于P5的体系结构,可以阅读“utilizes the pretrained T5 checkpoints as backbone”(作者:Geng等人)。
T5是谷歌几年前发布的另一个LLM[6]。它被设计用来处理多种类型的sequence-to-sequence任务,因此将其用作这种系统的起点是有道理的。
03 使用自定义数据实现/复制 P5
我对这篇论文印象深刻,想要了解是否可以在更小的数据规模下复制其序列推荐功能。因此我打算使用开源的T5模型(T5-large)[7]进行微调,来生成适合推荐的内容。为此我准备了一个自定义的数据集,包括了100多个体育器材的购买案例和下一个购买的物品。举个例子:
Input: “Soccer Goal Post, Soccer Ball, Soccer Cleats, Goalie Gloves”
Target Output: “Soccer Jersey”
当然,为了让该模型具有更强的鲁棒性(robust),我决定使用更加明确的prompt。以下是我使用的具体prompt:
Input: “ITEMS PURCHASED: {Soccer Goal Post, Soccer Ball, Soccer Cleats, Goalie Gloves} — CANDIDATES FOR RECOMMENDATION: {Soccer Jersey, Basketball Jersey, Football Jersey, Baseball Jersey, Tennis Shirt, Hockey Jersey, Basketball, Football, Baseball, Tennis Ball, Hockey Puck, Basketball Shoes, Football Cleats, Baseball Cleats, Tennis Shoes, Hockey Helmet, Basketball Arm Sleeve, Football Shoulder Pads, Baseball Cap, Tennis Racket, Hockey Skates, Basketball Hoop, Football Helmet, Baseball Bat, Hockey Stick, Soccer Cones, Basketball Shorts, Baseball Glove, Hockey Pads, Soccer Shin Guards, Soccer Shorts} — RECOMMENDATION: ”
Target Output: “Soccer Jersey”
可以在上方看到用户目前已购买的物品清单,接下来是尚未购买的(即整个库存中)候选推荐物品列表。
在使用Hugging Face的Trainer API[8](Seq2SeqTrainer)对T5模型进行微调(10轮左右)之后,我获得了一些特别出色的成果!以下是一些示例评估:
Input: “ITEMS PURCHASED: {Soccer Jersey, Soccer Goal Post, Soccer Cleats, Goalie Gloves} — CANDIDATES FOR RECOMMENDATION: {Basketball Jersey, Football Jersey, Baseball Jersey, Tennis Shirt, Hockey Jersey, Soccer Ball, Basketball, Football, Baseball, Tennis Ball, Hockey Puck, Basketball Shoes, Football Cleats, Baseball Cleats, Tennis Shoes, Hockey Helmet, Basketball Arm Sleeve, Football Shoulder Pads, Baseball Cap, Tennis Racket, Hockey Skates, Basketball Hoop, Football Helmet, Baseball Bat, Hockey Stick, Soccer Cones, Basketball Shorts, Baseball Glove, Hockey Pads, Soccer Shin Guards, Soccer Shorts} — RECOMMENDATION: ”
Model Output: “Soccer Ball”
Input: “ITEMS PURCHASED: {Basketball Jersey, Basketball, Basketball Arm Sleeve} — CANDIDATES FOR RECOMMENDATION: {Soccer Jersey, Football Jersey, Baseball Jersey, Tennis Shirt, Hockey Jersey, Soccer Ball, Football, Baseball, Tennis Ball, Hockey Puck, Soccer Cleats, Basketball Shoes, Football Cleats, Baseball Cleats, Tennis Shoes, Hockey Helmet, Goalie Gloves, Football Shoulder Pads, Baseball Cap, Tennis Racket, Hockey Skates, Soccer Goal Post, Basketball Hoop, Football Helmet, Baseball Bat, Hockey Stick, Soccer Cones, Basketball Shorts, Baseball Glove, Hockey Pads, Soccer Shin Guards, Soccer Shorts} — RECOMMENDATION: ”
Model Output: “Basketball Shoes”
由于推荐结果并非二元的成功或失败,我们其实只能根据主观感觉来做出评判,但是推荐结果与用户已经购买的物品非常相似,这一现象仍然令人印象深刻。
04 尝试用非英语的数据进行模型复制
接着,我尝试对阿拉伯语数据进行同样的操作。我将数据集进行了翻译,并寻找适合处理阿拉伯文本的开源T5模型(如AraT5[9]、MT5[10]等)。然而,经过尝试了Hugging Face Hub[11]上十几个相关变体模型后,我发现没有得到符合要求的结果。即使使用微调的模型,在无论某商品过去是否购买过的基础上,也仅推荐相同的1或2件物品,通常是“كرة القدم”(足球)(也许该模型知道阿拉伯语言人士喜欢足球,并一直在搜索足球相关物品)。即使尝试使用更大规模的T5模型,如MT5-xl,仍然得到相同的结果。这可能是因为这些语言模型对英语以外的数据支持不足。
为了尝试进行改进,我决定使用Google翻译API以及我已经微调的英文T5模型进行操作。具体步骤如下:
● 将阿拉伯输入文本翻译为英文。
● 将翻译后的英文文本输入到已经微调的英文模型中。
● 获取模型在英文上的预测结果。
● 将预测结果翻译回阿拉伯语。
然而,这一过程并没有带来太大帮助,因为翻译工具也会犯一些错误(比如说,“كرة القدم”,谷歌翻译将其翻译成“足球”,但它实际上的意思是“橄榄球”),这导致了模型出现了误差,最终结果是始终推荐相同的1-2件物品。
05 LLMs作为推荐系统的优缺点
这种技术最主要的优点在于其能够作为一个独立的系统(stand-alone system.)来实现,便利性很高。 由于LLMs和预训练技术拥有的特性,我们可以避免大量手动的特征工程(manual feature engineering)要求。因为该模型应该能够自然地学习表征(representations)和关系(relationships)。此外,我们也可以在一定程度上避免新推出的物品面临的“冷启动”问题。我们可以通过提取出新物品的名称/描述,并将其自然地与用户已经购买/选择的现有物品相关联。
然而,这种方法也存在一些缺点(不要把你现有的推荐系统丢弃!)。主要表现为对推荐内容缺乏控制:
● 由于用户浏览商品和购买商品的不同行为/事件(actions/events)没有进行加权,我们完全依赖于LLM去预测最有可能的下一个token或token组,来进行推荐。这种方法无法考虑用户的收藏、浏览历史、购物车等行为。
● 此外,因为这些LLM大部分推荐都是基于相似度,即与迄今购买过的商品语义相似的商品,存在一定风险。然而,我认为通过大量的用户购买历史数据,可以采用此方法所模拟的“协同过滤”方法来改善这个问题。
● 最后,由于LLM在理论上可以生成任何文本,推荐的内容可能并不完全匹配商品库存中的项目。不过,我认为这种情况发生的可能性较低。
06 Final Thoughts 最后的思考
基于P5论文的结果以及我尝试在T5模型上通过微调和Prompt来进行复制的经理,我推断这种技术可以用于许多语言模型。如果微调模型的数据足够大,Prompt技术得到完善,使用更强大的sequence-to-sequence模型可以显著增强效果。
然而,我不会建议单独使用这种方法。我建议将其与其他推荐系统技术结合起来使用,这样就可以避免上面提到的缺点并同时获得更好的效果。 如何做到这一点我不确定,但我认为只要有创造力,将LLM技术与其他推荐系统技术相结合可能会很有帮助(例如,可以提取基于嵌入的特征(embedding-based features)用于协同过滤(collaborative filtering) ,或与 “Two Tower”架构结合使用等等)。
07 Code
-
我实现的 T5 推荐系统(在 Github 仓库中)[12]
-
我在 Hugging Face 平台微调过的 T5 模型(Hugging Face Hub)[13]
END
参考资料
1.https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/
2.https://arxiv.org/pdf/1706.03762.pdf
3.https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
4.https://kawine.github.io/blog/nlp/2019/06/21/word-analogies.html
5.https://developers.google.com/machine-learning/recommendation/collaborative/basics
6.https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
7.https://huggingface.co/t5-large
8.https://huggingface.co/docs/transformers/main_classes/trainer
9.https://huggingface.co/UBC-NLP/AraT5-base
10.https://huggingface.co/google/mt5-large
11.https://huggingface.co/models
12.https://github.com/Mohammadhia/t5_p5_recommendation_system
13.https://huggingface.co/mohammadhia/t5_recommendation_sports_equipment_english
14.S. Geng, S. Liu, Z. Fu, Y. Ge, Y. Zhang, Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) (2023), 16th ACM Conference on Recommender Systems
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/using-large-language-models-as-recommendation-systems-49e8aeeff29b