当众多chat-xxx和xxxGPT喷涌而出的时候,博主就在等它被做到推荐系统的这一天。本篇博文将简要看看一些文章的具体做法。
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
先上地址,
- https://arxiv.org/abs/2303.14524
LLM+推荐系统的结合点在哪?
虽然大型语言模型LLM已经证明了它们用于解决各种应用任务的巨大潜力,但它和推荐系统的结合点在哪?
- 推荐系统旨在根据用户的偏好和行为向用户推荐项目。传统上,这些系统都依赖于用户数据,如点击流和购买历史等等。
- NLP在扩大推荐系统用户数据的范围方面是有价值的。比如NLP技术可以用于分析用户生成的内容,如评论和社交媒体帖子,以深入了解用户的偏好和兴趣,提高整体用户体验和参与度。
然而,传统的推荐系统仍然面临着巨大的挑战,如缺少交互性、可解释性,缺乏反馈机制,以及冷启动和跨域推荐等长期问题。但LLM的出现为这些挑战提供了一个很有前途的解决方案。
- LLM可以生成更自然和可解释的建议,从而可以解决冷启动问题,并执行跨领域推荐。
- LLM具有更强的交互性和反馈机制,完全可以增强整体用户体验。
- 通过利用海量参数所承载的内部知识,LLM可以依靠外部检索器以进一步提高推荐系统的性能 。
推荐系统任务被制定为基于提示的自然语言任务,其中user-item信息和相应的特征与个性化的提示模板集成作为模型输入。然而,在目前的研究中,LLM仍然作为模型的一部分需要参与训练(不过博主个人观点并不觉得这是比较大的缺点,利用通用模型的能力+小部分参数训练到垂直领域效果一定更有保证,更多可以参考博主之前的文章门)。
在这篇文章中,作者介绍了一种新的方法来做会话推荐系统(从而能与LLM更紧密的结合),它具有交互式和可解释的能力,即LLMs 增强传统推荐的范式 Chat-Rec(ChatGPT Augmented Recommender System),不需要训练(本质就是直接拿chatGPT做接口,设计预/后处理),而是只依赖于上下文学习,从而产生更有效的结果。
- 使用LLM增强的推荐系统,有利于在对话过程中了解用户的偏好。
- 在对话的每一步之后,可以迭代用户偏好,更新候选推荐结果。
- 此外,用户与产品之间的偏好是紧密链接的,从而允许更好的跨领域产品推荐。
Chat-Rec的模型结构如下图所示,
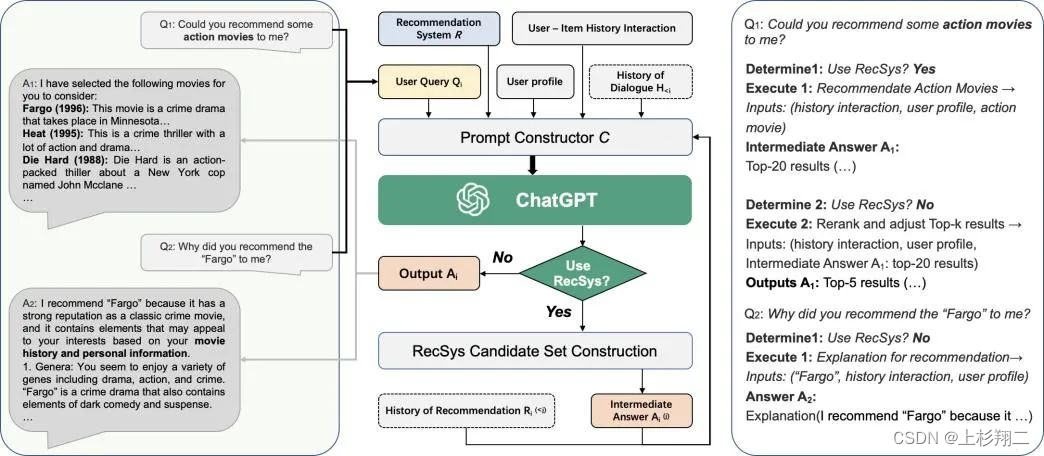
左边是用户和 ChatGPT 之间的对话。中间是Chat-Rec的主要贡献,即链接推荐系统和 ChatGPT。右边是策略执行具体过程,即
- 对于一个用户query:“你能推荐一些动作片给我吗?”。
- 确定这个query是否是一个推荐任务【ChatGPT来判断】
-
- 如果是推荐任务,则使用该输入来执行“推荐动作电影”模块。但由于推荐空间是巨大的,所以该模块需要分为两个步骤:1推荐系统产生一个少量的候选得到top20的推荐结果,2然后再进行重新排序和调整【ChatGPT来重排】,以生成top5的最终输出。这种方法可以确保向用户展示一个更小、更相关的物品集,增加他们找到自己喜欢的东西的可能性。
-
- 如果不是推荐任务,如用户询问“为什么会推荐你会推荐fargo电影给我”。系统将使用电影标题、历史记录交互和用户配置文件作为输入来执行对推荐模块的解释【ChatGPT来生成解释】。
由于ChatGPT的输入是自然语言文本,所以中间模块的主要目标就是如何利用用户与物品的历史交互、用户档案、用户查询和对话历史 (如果有的话)等等多个输入ChatGPT来生成一个自然语言段落,以捕捉用户的查询和推荐信息。
- User-item history interactions:用户与物品的历史交互,指的是用户过去与物品的互动,比如他们点击过的物品,购买过的物品,或者评价过的物品。
- User profile:用户画像,其中包含关于用户的人口统计和偏好信息,如年龄、性别、地点和兴趣。
- User query Q i Q_i Qi:查询句子,可能是推荐任务也可能是通用任务。
- History of dialogue H < i H_{<i} H<i:用户和chatGPT之间的所有上下文对话。
对于topk推荐任务来说,生成的prompt例子是:

对于评分任务来说,生成的prompt例子是:

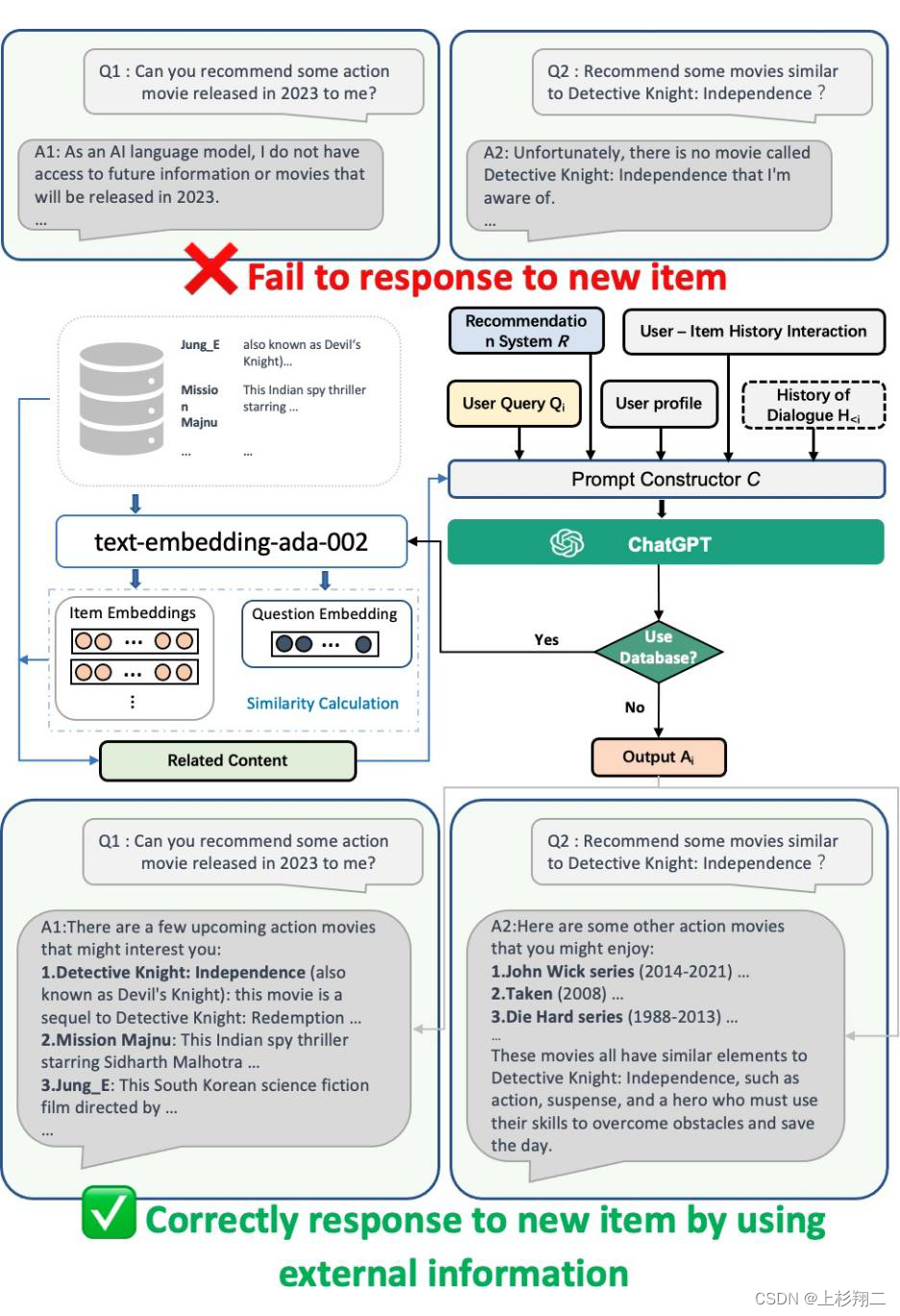
如何解决冷启动
大模型中拥有很多知识,利用商品的文字描述就能够借助LLM的力量来帮助推荐系统缓解新项目的冷启动问题,即没有大量用户互动也可以得到embedding。
如上图所示,最上展示了两种chatGPT难以执行推荐场景:
- 1 让不能联网的chatGPT推荐2023最新的动作电影;
- 2 让chatGPT推荐一个它知识储备中没有的动作电影。
因此,作者们的做法是离线利用LLM来生成相应的embedding表征并进行缓存。从而在当chatGPT遇到新的物品推荐时,会首先计算离线商品特征和用户query特征之间的相似性,然后检索最相关商品一起输入到 ChatGPT 进行推荐。
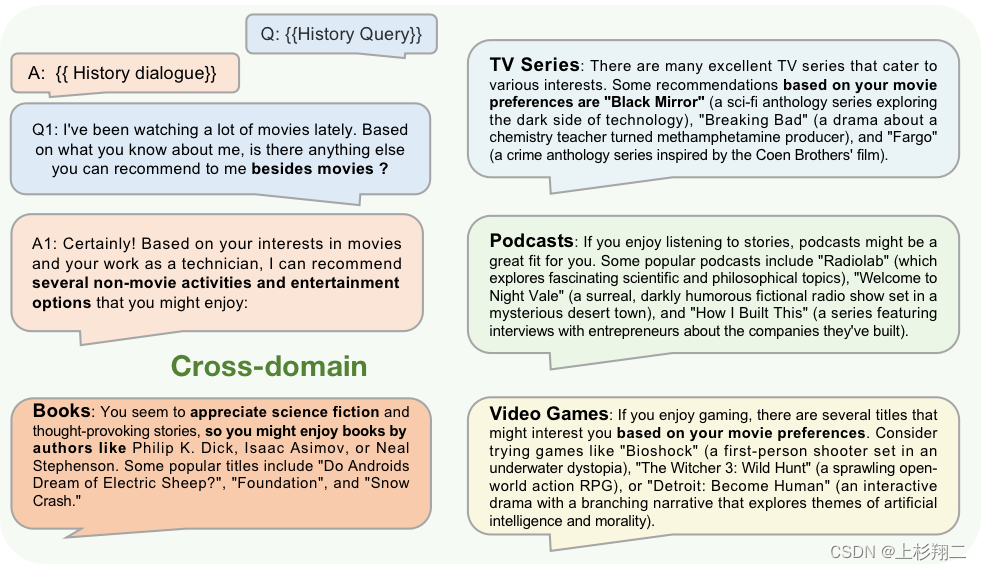
如何解决跨域推荐
类似的,LLM中的知识可以很方便对不同领域的商品有认知,如电影,音乐和书籍等等,并且还能够分清楚在不同领域产品之间的关系。
因此,如上图所示,作者们的做法是直接依靠chatGPT啦,把上下文对话输入一起编码进chatGPT的输入后,就能在用户询问关于其他类型作品的建议时,实现跨域推荐,如对书籍、电视剧、播客和视频游戏进行推荐。
实验
backbone选了GPT-3 和 GPT-3.5 系列中的三个模型
- gpt-3.5-turbo,即chatGPT。
- text-davinci-003。
- text-davinci-002。
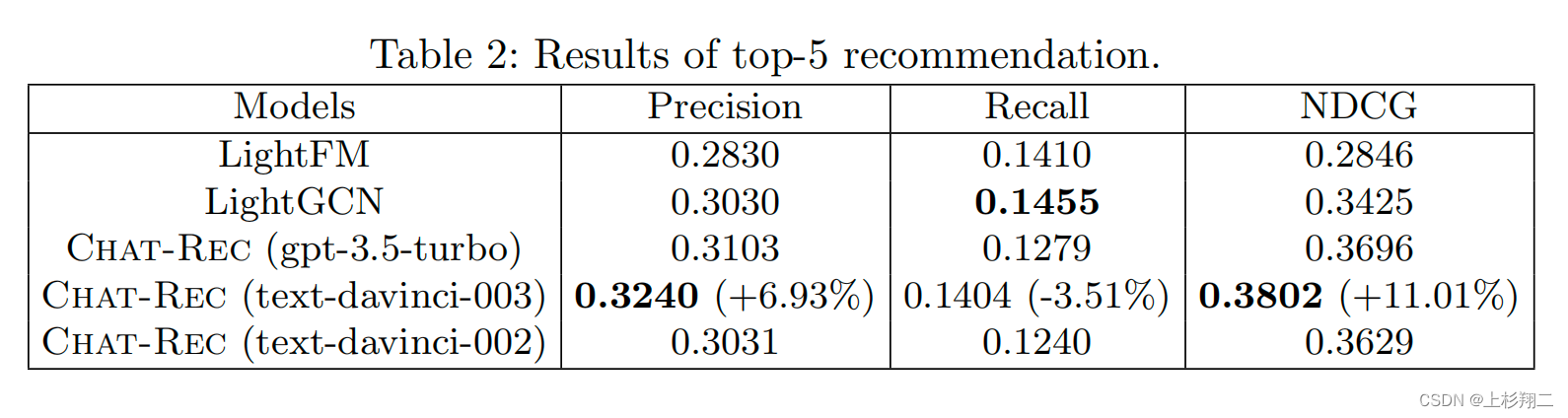
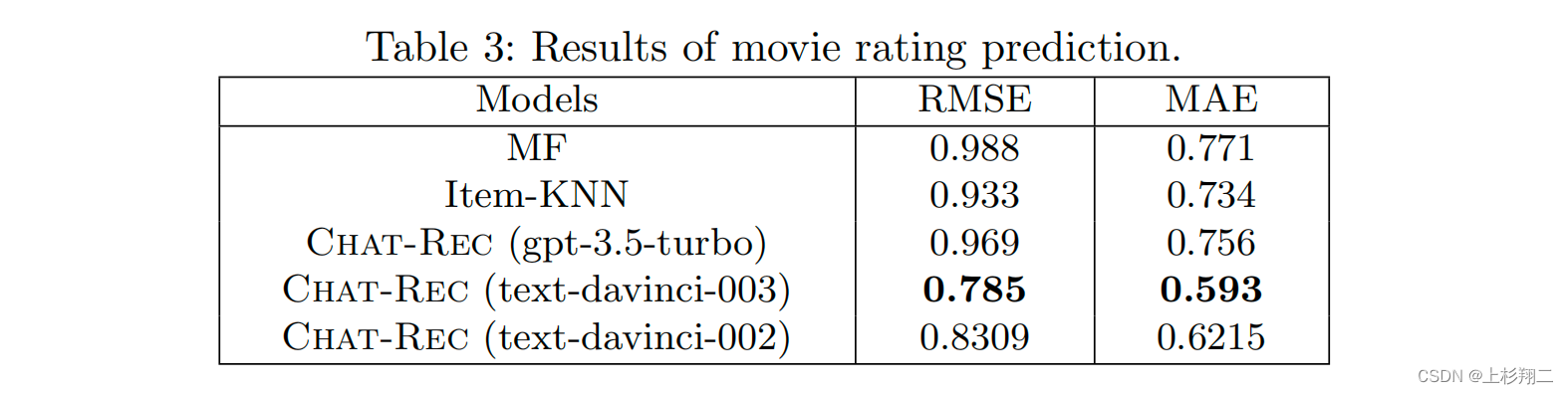
从top5推荐和评分预测这个俩结果上来看,似乎text-davinci-003才是最好的。。
可能说明基础表征能力够了,对这俩任务来说是足够的。不过作者没有其他任务的实验结果,比如上面说的冷启动、跨域、可解释似乎都无,继续观望吧。