[大语言模型应用于推荐系统]Large Language Models are Competitive Near Cold-start Recommenders for Language- and Item-based Preferences
本文的主要贡献:
(1)设计了一个实验设计,可以直接将基于语言的物品推荐与最先进的基于物品的推荐方法进行比较,并提出了一种新颖的数据收集协议。
(2)为基于语言的物品推荐任务提出了各种提示方法。
(3)通过实验证明了所提出的基于提示的方法与一组强基线方法的比较,包括基于文本和基于物品的方法。最终,观察到纯基于语言的偏好描述的语言模型推荐方法提供了一种基于可解释和可审查的语言偏好表示的具有竞争力的近乎冷启动推荐系统。
下面为本文的具体内容:
原文地址: arxiv:2307.14225
传统的推荐系统利用用户的历史偏好来推荐用户可能喜欢的新内容。然而,现在用户可以使用语言的输入方式在来进行偏好输入。受最近大型语言模型的在推荐系统中的启发,本文将比较基于物品和基于语言偏好的推荐方法与最先进的基于物品的协同过滤(CF)的方法。为了支持这项研究,作者收集了一个新的数据集,其中包含从用户那里获取的基于物品和基于语言的偏好,以及他们对各种(有偏见的)推荐物品和(无偏见的)随机物品的评分。
在众多的实验结果中,作者发现在纯粹基于语言偏好(没有物品偏好)的近冷启动情况下,LLMs在推荐性能方面与基于物品的CF方法相比具有竞争力,尽管它们没有针对这个特定任务进行监督训练(零样本)或只有少量标签(少样本)。这一发现是很有用的,因为基于语言偏好的表示比基于物品或基于向量的表示更具解释性和可解释性。
1. 主要工作
主要问题
与仅基于物品的协同过滤方法相比,使用大型语言模型的提示策略对于基于自然语言偏好描述的推荐效果如何?
主要工作
作者在语言模型和基于提示的范式(例如LLMs)的最新进展基础上,解决了基于语言的物品推荐任务,这些进展在各种自然语言任务中取得了很好的结果,使得能够在统一的框架中利用丰富的正面和负面的描述性内容和物品偏好。
作者将这些新技术与传统的基于语言的信息检索技术和基于协同过滤的方法进行了对比。由于这是一个新的任务,目前还没有针对基于语言的物品推荐的数据集。作者提出了一种数据收集协议,并构建了一个测试集,其中包括自然语言偏好描述和物品评分。通过这样做,试图回答以下研究问题:
- RQ1:自然语言表达的偏好是否足以替代物品,特别是在近乎冷启动的推荐中?当语言与物品结合时,性能提升多少?
- RQ2:基于语言模型的推荐方法与基于物品的协同过滤方法相比如何?
- RQ3:哪种基于语言模型的提示方式(如补全、指令或少样本提示)效果最好?
- RQ4:是否包含自然语言的反向偏好可以提高基于语言的推荐效果?
本文的主要贡献:
(1)设计了一个实验设计,可以直接将基于语言的物品推荐与最先进的基于物品的推荐方法进行比较,并提出了一种新颖的数据收集协议。
(2)为基于语言的物品推荐任务提出了各种提示方法。
(3)通过实验证明了所提出的基于提示的方法与一组强基线方法的比较,包括基于文本和基于物品的方法。最终,观察到纯基于语言的偏好描述的语言模型推荐方法提供了一种基于可解释和可审查的语言偏好表示的具有竞争力的近乎冷启动推荐系统。
2. 实验设置
为了研究基于物品和基于语言的偏好之间的关系,以及它们在推荐中的效用,需要来自相同评价者的平行语料库提供这两种类型信息,并且这些信息要尽可能一致。目前缺乏这种性质的现有平行语料库,因此作者设计了一个实验方案,可以收集到这种一致的信息。具体而言,设计了一个两阶段的用户研究,评价者在第一阶段被要求对物品进行评分,并用自然语言描述他们的偏好,然后在第二阶段,基于这两种类型的偏好生成的推荐被评价者统一进行评分。因为电影推荐对于众多用户研究参与者来说是熟悉的经常被用于研究,故采用电影来作为研究对象。
在这种平行语料库中的一个关键问题是,人们可能会说他们喜欢具有特定特征的物品,但实际上会消费并对完全不同的物品产生积极反应。例如,已经观察到人们表达了某种愿望(例如订阅特定的播客),但实际上却消费了完全不同的物品(例如听其他的)。这种语料库之间的差异可能导致对于特定信息在推荐任务中的效用进行不准确的预测。因此,作者考虑最大限度地提高一致性。
2.1 第一阶段:偏好获取
偏好获取阶段收集了评价者的自然语言描述,分别在问卷开始和结束时进行。具体而言,首先要求评价者撰写短段描述他们喜欢的电影类型以及不喜欢的电影类型(自由文本,最少150个字符)。评价者 r 的初始喜欢(+)和不喜欢(-)的描述分别表示为 desc(r+) 和 desc(r-)。
接下来,要求评价者列举出他们喜欢的五部电影的示例。这个步骤在在线查询系统(类似于现代搜索引擎)中实现,评价者可以开始输入电影的名称,系统会自动补全为具体的电影。自动完成的范围是 MovieLens 25M 数据集中的评分数量排名前1万部电影,以确保覆盖不常见的电影。当评价者做出选择时,这些选择会被放入一个列表中,然后可以进行修改。然后,要求每个评价者再选择他们不喜欢的五部电影。评价者 r 的喜欢(+)和不喜欢(-)的项目选择以及项目选择索引 j ∈ {1, . . . , 5} 分别表示为 item1 和 item2。
最后,评价者根据五部喜欢的电影,并再次要求他们撰写描述他们喜欢的电影类型的短段(称之为最终描述)。同样地,对于五部不喜欢的电影也是如此,重复相同的过程。
2.2 第二阶段:推荐反馈收集
为了实现基于物品和基于语言的推荐算法的公平比较,用户研究的第二阶段要求评价者根据第一阶段收集的信息评估一些推荐算法所产生的推荐质量。特别地,过去的研究观察到标签的完整性对于可靠地比较基本不同的算法是重要的。
推荐算法选择的期望标准:目标是选择一组基于物品、基于语言和无偏的推荐算法。因此,作者收集了用户的反馈(他们是否看过或者是否会观看,并在两种情况下给出1-5的评分)对于一个打乱顺序的包含40部电影的样本集(显示缩略图和简短情节概要)。这些电影来自以下四个样本池:
- SP-RandPop:无偏的热门物品样本集,包括10个随机选择的热门物品(根据MovieLens评分数量排名在1-1000之间);
- SP-RandMidPop:无偏的较不热门物品样本集,包括10个随机选择的较不热门物品(根据MovieLens评分数量排名在1001-5000之间);
- SP-EASE:个性化的基于物品的推荐算法,它是在强大的基线EASE [42]协同过滤推荐器的基础上生成的,使用了超参数 λ = 5000.0 \lambda = 5000.0 λ=5000.0,并在来自15个用户的保留样本数据集上进行了调优。
- SP-BM25-Fusion:个性化的基于语言的推荐算法,包括基于稀疏评论的后期融合检索方法的前10个推荐结果,类似于[3],它计算了亚马逊电影评论语料库(v2)中所有物品评论与评价者的自然语言偏好(desc+)之间的BM25匹配,并按照最大BM25得分对物品进行排序。
需要注意的是,SP-RandPop和SP-RandMidPop对于每个评价者来说有10部不同的电影,而且它们是完全无偏的(因为它们不利用任何用户信息,所以不能对更明显的推荐物品有偏好,或者其他潜在的偏见来源)。另一方面,SP-EASE包含了基于用户物品偏好的EASE推荐(有一定的偏见),作者也将其作为一个推荐算法进行评估。因此,在分析中,作者将SP-RandPop和SP-RandMidPop合并为一个无偏样本集,该样本集的性能对于结论至关重要。
2.3 设计结果
重要的是,为了确保基于语言和基于物品方法的最大程度公平比较,在数据收集方法中需考虑两种类型偏好的一致性。因此,作者直接从评价者那里按顺序获取了这两种类型的偏好,文本描述被收集了两次——在自选物品评分之前和之后。这种控制方式要求每个评价者的数据量必须很小。这也是在接近冷启动对话环境中,推荐接收者可能需要提供的偏好信息的现实量级。由于需要进行手动工作,作者招募评价者的数量也考虑到了算法比较所需的功效,关键贡献在于开发的协议,而不是数据规模。
因此,该方法与从在线内容中批量提取评论或偏好描述的替代方法(偏好不一定完全捕捉一个人的兴趣)以及依赖于随时间明确或隐含地表达的物品偏好(在此期间偏好可能会改变)形成对比。
3. 方法
鉴于拥有每个评价者的基于语言和基于物品的偏好和对40个物品的评分,作者用了多种方法来让被调查者回答作者的研究问题。作者首先提出了传统的基于物品或基于语言偏好的基线方法,然后使用新颖的LLM方法,包括仅使用物品、仅使用语言或物品和语言的组合。
3.1 基线方法
为了利用第一阶段获取的物品和语言偏好,作者评估了协同过滤(CF)方法以及之前被认为特别有效的基于语言的基线方法。大多数基线基于物品的CF方法使用了MyMediaLite中的默认配置,包括MostPopular:根据数据集中的评分数量对物品进行排名,Item-kNN:基于物品的k最近邻方法,WR-MF:加权正则化矩阵分解,是奇异值分解的正则化版本,以及BPR-SLIM:通过正则化优化方法学习对已评分物品进行稀疏加权的稀疏线性方法(SLIM)。作者还与更近期的基于物品的EASE推荐器进行了比较,使用作者自己实现的版本。作为基于语言的基线方法,作者与第3.2节中描述的BM25-Fusion进行了比较。最后,作者还评估了评价者池中物品的随机顺序(Random)作为对比这个无信息基线的校准。
3.2 提示方法
作者尝试了多种提示策略,使用了PaLM模型的变体(参数规模为620亿,训练了超过1.4万亿个标记),作者简称为LLM。在符号表示上,作者假设 t 是目标评价者(推荐的对象),r表示通用评价者。所有提示都由两部分组成:前缀和后缀,后缀始终是目标用户要评分的物品(电影)的名称,表示为 item_*^t。分数计算为后缀的对数似然,并用于对所有候选物品推荐进行排序。因此,作者可以评估LLM对数据收集第2阶段收集的40个目标物品集合中每个物品的分数。
在这种符号表示下,作者设计了仅使用物品、仅使用语言和物品+语言组合的完成(Completion)、零样本(Zero-shot)和少样本(Few-shot)提示模板,定义如下:
3.2.1 仅使用物品
方法类似于P5模型中使用的方法,不同之处在于作者使用了预训练的LLM而不是自定义训练的 transformer 模型。

3.2.2 仅使用自然语言

3.2.3 物品+自然语言信息

4. 结论
4.1 数据分析
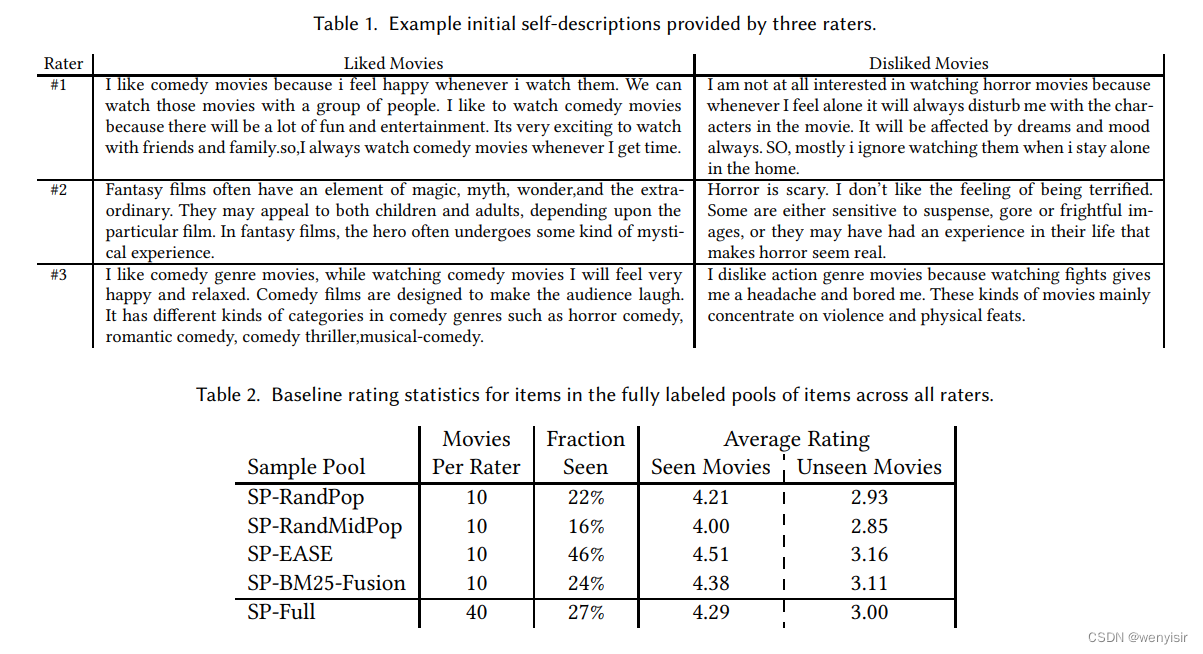
作者简要分析了从153名评分者那里收集到的偏好引导和评分过程中的数据。每个评分者在撰写他们喜欢的内容总结时,用时中位数为67秒,而撰写他们不喜欢的内容总结时,用时中位数为38秒(分别对应的中位数长度为241和223个字符)。提供五个喜欢和五个不喜欢的物品,分别需要中位数为174和175秒的时间。接着,撰写喜欢和不喜欢的最终描述,分别需要中位数为152和161秒的时间(分别对应的中位数长度为205和207个字符)。作者观察到,与提供5个示例物品相比,初始描述的产生速度快了3到4倍,大约在一分钟内完成。正如作者将在下文看到的,这种努力上的差异对于基于物品和基于描述的推荐在性能上的比较尤为重要。初始描述的样本如表1所示。
接下来,作者将对第3节中描述的四个物品池中电影所收集的评分进行分析。从表2中,作者观察到以下几点:(1) EASE推荐系统几乎将评分者已经看过的物品的推荐率提高了近两倍,这反映了它所训练的有监督数据,其中评分者只对他们所看到的物品进行评分;(2) 对于评分者已经看过的电影,存在固有的积极倾向,导致他们倾向于给予较高的评分,如此时的平均评分为4.29;(3) 相比之下,对于未看过的物品,平均评分降至中性的3.00分。
4.2 推荐的物品
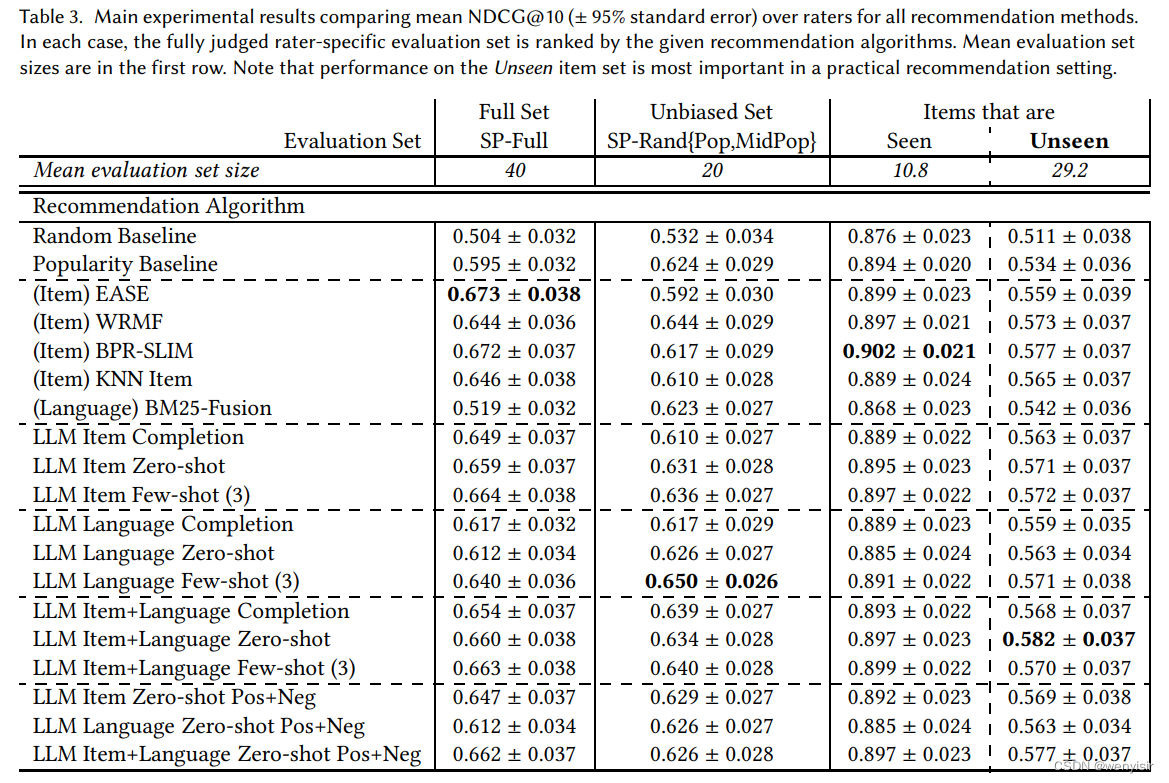
作者的主要实验结果在表中展示,使用NDCG@10指标并采用指数增益(对于评分s<3的部分增益为0,对于评分s>=3的部分增益为 2 s − 3 2^{s-3} 2s−3)。作者比较了使用基于物品和/或语言偏好的不同方法的平均性能(如第3.1节所述),并对40个完全被评判的测试推荐物品中的四个不同池子进行排名(如第3.2节所述)。需要注意的是,每个评分者的池子是针对该评分者个性化定制的。语言偏好的结果仅使用评分者最初的自然语言描述,这些描述的产生速度比喜欢和不喜欢的物品选择或最终描述要快得多,但在性能上与最终描述相当。
首先,注意到每个物品子集中的NDCG@10得分范围差异较大,这是由于NDCG的标准化参数通常随着更大的评估集大小而增加,以及每个池子的平均评分。作者之前观察到在表2中,Seen推荐子集的物品池最小,并且存在较高的正向评分偏差,这使得很难在这个子集上区分推荐算法的性能。然而,正如[35]最近所指出的,在推荐设置中,物品通常只被消费一次(比如电影),作者更关心Unseen子集相对于Seen子集的推荐性能。类似地,作者还关心Unbiased子集的性能,因为该子集涵盖了广泛的流行度范围,并且不倾向于基于物品的协同过滤方法。
为了解在第1节提出的研究问题:
RQ1:语言偏好能否替代或改进基于物品的偏好?首先,从观察到LLM语言Few-shot(3)方法在这种近似冷启动的设置中与大多数传统的基于物品的协同过滤方法竞争力相当,作者得出了初步的积极答案。这一点很重要,因为正如在第5.1节中观察到的,相比于基于物品的偏好,语言偏好的获取时间更短。此外,语言偏好是透明且可解释的[37]。然而,结合语言和基于物品的偏好似乎并没有明显的好处,因为Item+Language LLM方法在性能上并没有显著提升。
RQ2:基于LLM的方法与基于协同过滤(CF)的方法相比如何? RQ1已经证明了对于LLM的语言变体,基于LLM的方法通常与基于物品的CF方法具有相当的竞争力。然而,值得注意的是,在许多情况下,LLM-based方法甚至可以与仅使用基于物品的偏好(即首选电影的名称)的CF方法相比性能相当。一个关键且令人惊讶的结果是,预训练的LLM在没有用于训练CF方法的大量监督数据的情况下,仍然能够提供具有竞争力的推荐结果。
RQ3:最佳的提示方法是什么?Few-shot(3)提示方法通常优于Zero-shot和Completion提示方法。Zero-shot和Completion提示方法之间的差异较小。虽然由于篇幅限制没有显示,但增加Few-shot示例的数量并没有改善性能。
RQ4:是否包含不喜欢的物品对推荐有帮助?在表3的最后三行中展示了包含负面物品或语言偏好对LLM-based推荐器的影响。在这些LLM配置中,包含正面和负面偏好(Pos+Neg)并没有比仅包含正面偏好有实质性的改进。虽然由于篇幅限制没有显示,但省略正面偏好并仅使用负面偏好会导致性能等于或低于流行度基准(popularity baseline)。
5. 道德考虑
作者简要考虑了可能存在的道德问题。首先,重要的是考虑推荐的物品是否存在偏见。例如,研究如何衡量语言驱动的推荐系统是否比传统推荐系统更容易出现意外偏见,例如是否倾向于某些类别的物品而不是其他类别的物品,将是很有价值的。作者的任务是对一组固定的物品进行排序。因此,模型考虑并对所有物品进行评分。如果存在强烈的偏见,整体性能指标可能会受到影响,尽管在作者的实验规模下,无法排除存在偏见的可能性。需要更大规模的研究来限制任何可能存在的偏见。
此外,作者的结论是基于相对较小的153名评分者的偏好数据。实验规模的限制和仅限于英语偏好意味着作者无法评估相同的结果是否会在其他语言或文化中得到相同的结果。
最后,作者需要指出的是,偏好数据是由付费承包商提供的。他们按照标准合同规定的工资支付,其工资水平高于所在国家的生活工资水平。
6. 结论
本文中,作者收集了一个包含基于物品和基于语言偏好的评分者数据集,并包含了他们对一组独立的物品推荐的评分。利用大规模语言模型(LLMs)中的多种提示策略,这个数据集使得作者能够公平且定量地比较纯粹基于物品偏好、纯粹基于语言偏好以及它们的组合对推荐效果的影响。在作者的实验结果中,作者发现LLMs中的零样本和少样本策略在纯粹基于语言偏好(无物品偏好)的推荐性能方面表现出色,特别是在近似冷启动的情况下,与基于物品的协同过滤方法相比较,表现竞争力十足。尤其值得注意的是,尽管LLMs是通用型的模型,当利用基于物品或基于语言的偏好时,其性能与完全监督的基于物品的协同过滤方法相当。最后,作者观察到这种基于LLM的推荐方法提供了一种具有竞争力的近似冷启动推荐系统,基于可解释且可解读的基于语言的偏好表示,为利用语言偏好的有效和创新的LLM-based推荐系统提供了可能性。