苹果研究团队在预印本平台 arxiv 发表论文《LLM in a flash》,介绍了一项全新的闪存技术,让苹果可以在其内存有限的设备上部署大语言模型。
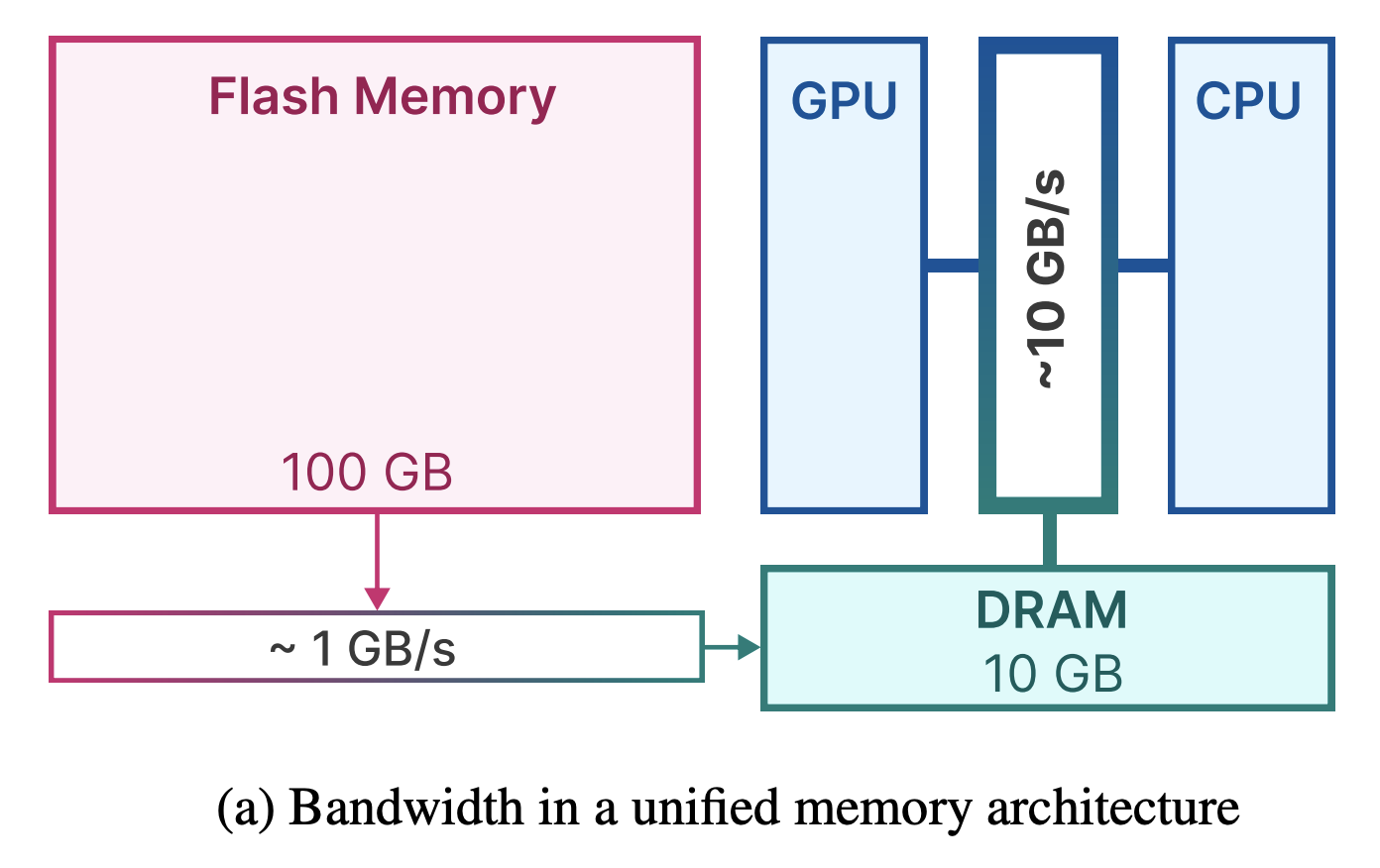
研究团队表示,他们通过将模型参数存储在闪存 (Flash Memory) 中——也就是储存应用和照片的地方,解决了有效运行大语言模型容量的挑战。与传统用于运行大语言模型的 RAM 相比,闪存在移动设备中容量要大得多。
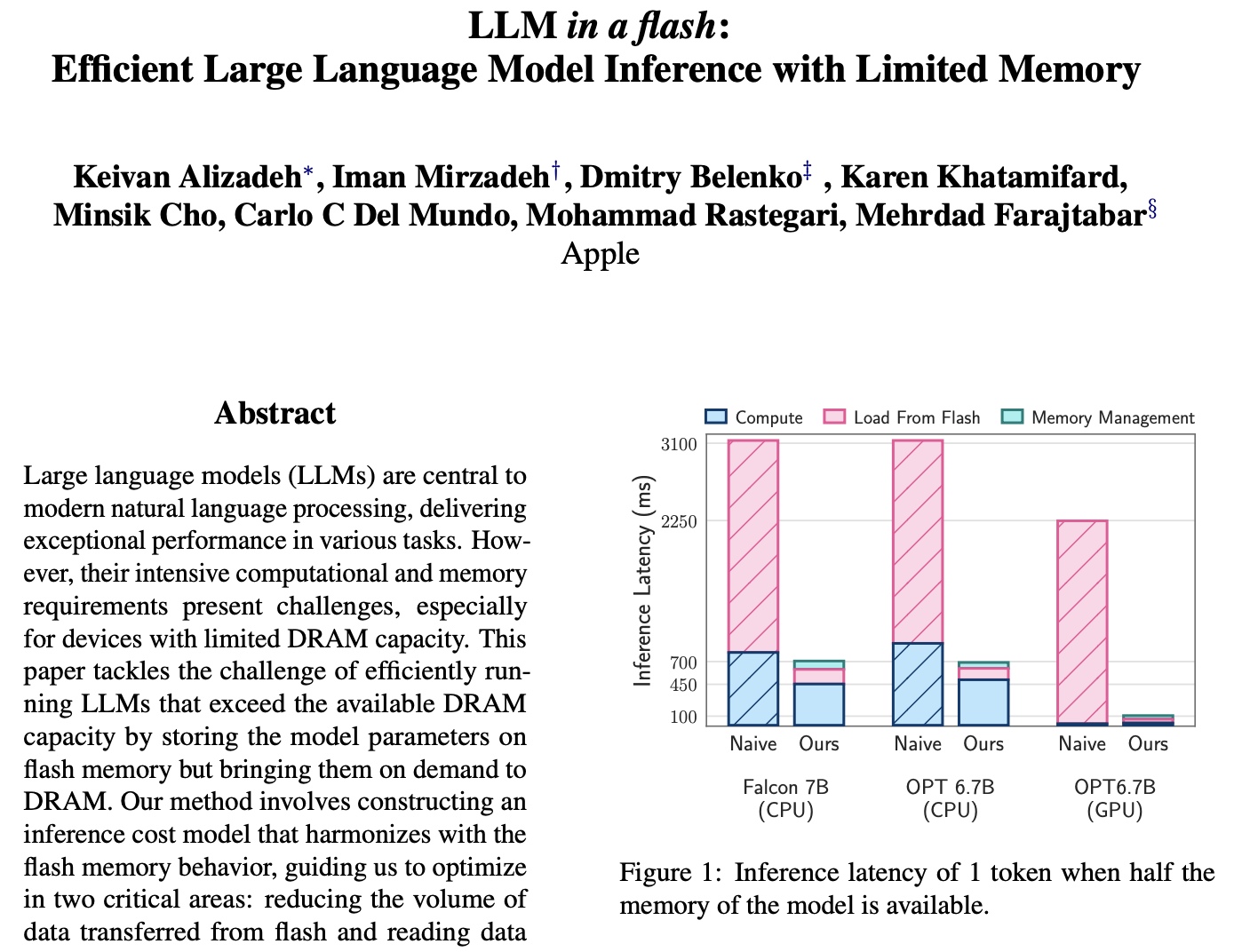
论文指出,这项技术可以让 AI 模型的运行规模达到 iPhone 可用内存的两倍。在这项技术的加持之下,LLM 的推理速度在 Apple M1 Max CPU 上提高了 4-5 倍,在 GPU 上提高了 20-25 倍。
延伸阅读