下面我将介绍内嵌物理知识神经网络(PINN)求解微分方程。首先介绍PINN基本方法,并基于Pytorch的PINN求解框架实现求解含时间项的二维Navier-Stokes方程。
内嵌物理知识神经网络(PINN)入门及相关论文
深度学习求解微分方程系列一:PINN求解框架(Poisson 1d)
深度学习求解微分方程系列二:PINN求解burger方程正问题
深度学习求解微分方程系列三:PINN求解burger方程逆问题
深度学习求解微分方程系列四:基于自适应激活函数PINN求解burger方程逆问题
深度学习求解微分方程系列五:PINN求解Navier-Stokes方程正逆问题
1.PINN简介
神经网络作为一种强大的信息处理工具在计算机视觉、生物医学、 油气工程领域得到广泛应用, 引发多领域技术变革.。深度学习网络具有非常强的学习能力, 不仅能发现物理规律, 还能求解偏微分方程.。近年来,基于深度学习的偏微分方程求解已是研究新热点。内嵌物理知识神经网络(PINN)是一种科学机器在传统数值领域的应用方法,能够用于解决与偏微分方程 (PDE) 相关的各种问题,包括方程求解、参数反演、模型发现、控制与优化等。
2.PINN方法
PINN的主要思想如图1,先构建一个输出结果为 u ^ \hat{u} u^的神经网络,将其作为PDE解的代理模型,将PDE信息作为约束,编码到神经网络损失函数中进行训练。损失函数主要包括4部分:偏微分结构损失(PDE loss),边值条件损失(BC loss)、初值条件损失(IC loss)以及真实数据条件损失(Data loss)。

特别的,考虑下面这个的PDE问题,其中PDE的解 u ( x ) u(x) u(x)在 Ω ⊂ R d \Omega \subset \mathbb{R}^{d} Ω⊂Rd定义,其中 x = ( x 1 , … , x d ) \mathbf{x}=\left(x_{1}, \ldots, x_{d}\right) x=(x1,…,xd):
f ( x ; ∂ u ∂ x 1 , … , ∂ u ∂ x d ; ∂ 2 u ∂ x 1 ∂ x 1 , … , ∂ 2 u ∂ x 1 ∂ x d ) = 0 , x ∈ Ω f\left(\mathbf{x} ; \frac{\partial u}{\partial x_{1}}, \ldots, \frac{\partial u}{\partial x_{d}} ; \frac{\partial^{2} u}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} u}{\partial x_{1} \partial x_{d}} \right)=0, \quad \mathbf{x} \in \Omega f(x;∂x1∂u,…,∂xd∂u;∂x1∂x1∂2u,…,∂x1∂xd∂2u)=0,x∈Ω
同时,满足下面的边界
B ( u , x ) = 0 on ∂ Ω \mathcal{B}(u, \mathbf{x})=0 \quad \text { on } \quad \partial \Omega B(u,x)=0 on ∂Ω
PINN求解过程主要包括:
- 第一步,首先定义D层全连接层的神经网络模型:
N Θ : = L D ∘ σ ∘ L D − 1 ∘ σ ∘ ⋯ ∘ σ ∘ L 1 N_{\Theta}:=L_D \circ \sigma \circ L_{D-1} \circ \sigma \circ \cdots \circ \sigma \circ L_1 NΘ:=LD∘σ∘LD−1∘σ∘⋯∘σ∘L1
式中:
L 1 ( x ) : = W 1 x + b 1 , W 1 ∈ R d 1 × d , b 1 ∈ R d 1 L i ( x ) : = W i x + b i , W i ∈ R d i × d i − 1 , b i ∈ R d i , ∀ i = 2 , 3 , ⋯ D − 1 , L D ( x ) : = W D x + b D , W D ∈ R N × d D − 1 , b D ∈ R N . \begin{aligned} L_1(x) &:=W_1 x+b_1, \quad W_1 \in \mathbb{R}^{d_1 \times d}, b_1 \in \mathbb{R}^{d_1} \\ L_i(x) &:=W_i x+b_i, \quad W_i \in \mathbb{R}^{d_i \times d_{i-1}}, b_i \in \mathbb{R}^{d_i}, \forall i=2,3, \cdots D-1, \\ L_D(x) &:=W_D x+b_D, \quad W_D \in \mathbb{R}^{N \times d_{D-1}}, b_D \in \mathbb{R}^N . \end{aligned} L1(x)Li(x)LD(x):=W1x+b1,W1∈Rd1×d,b1∈Rd1:=Wix+bi,Wi∈Rdi×di−1,bi∈Rdi,∀i=2,3,⋯D−1,:=WDx+bD,WD∈RN×dD−1,bD∈RN.
以及 σ \sigma σ 为激活函数, W W W 和 b b b 为权重和偏差参数。 - 第二步,为了衡量神经网络 u ^ \hat{u} u^和约束之间的差异,考虑损失函数定义:
L ( θ ) = w f L P D E ( θ ; T f ) + w i L I C ( θ ; T i ) + w b L B C ( θ , ; T b ) + w d L D a t a ( θ , ; T d a t a ) \mathcal{L}\left(\boldsymbol{\theta}\right)=w_{f} \mathcal{L}_{PDE}\left(\boldsymbol{\theta}; \mathcal{T}_{f}\right)+w_{i} \mathcal{L}_{IC}\left(\boldsymbol{\theta} ; \mathcal{T}_{i}\right)+w_{b} \mathcal{L}_{BC}\left(\boldsymbol{\theta},; \mathcal{T}_{b}\right)+w_{d} \mathcal{L}_{Data}\left(\boldsymbol{\theta},; \mathcal{T}_{data}\right) L(θ)=wfLPDE(θ;Tf)+wiLIC(θ;Ti)+wbLBC(θ,;Tb)+wdLData(θ,;Tdata)
式中:
L P D E ( θ ; T f ) = 1 ∣ T f ∣ ∑ x ∈ T f ∥ f ( x ; ∂ u ^ ∂ x 1 , … , ∂ u ^ ∂ x d ; ∂ 2 u ^ ∂ x 1 ∂ x 1 , … , ∂ 2 u ^ ∂ x 1 ∂ x d ) ∥ 2 2 L I C ( θ ; T i ) = 1 ∣ T i ∣ ∑ x ∈ T i ∥ u ^ ( x ) − u ( x ) ∥ 2 2 L B C ( θ ; T b ) = 1 ∣ T b ∣ ∑ x ∈ T b ∥ B ( u ^ , x ) ∥ 2 2 L D a t a ( θ ; T d a t a ) = 1 ∣ T d a t a ∣ ∑ x ∈ T d a t a ∥ u ^ ( x ) − u ( x ) ∥ 2 2 \begin{aligned} \mathcal{L}_{PDE}\left(\boldsymbol{\theta} ; \mathcal{T}_{f}\right) &=\frac{1}{\left|\mathcal{T}_{f}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{f}}\left\|f\left(\mathbf{x} ; \frac{\partial \hat{u}}{\partial x_{1}}, \ldots, \frac{\partial \hat{u}}{\partial x_{d}} ; \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{d}} \right)\right\|_{2}^{2} \\ \mathcal{L}_{IC}\left(\boldsymbol{\theta}; \mathcal{T}_{i}\right) &=\frac{1}{\left|\mathcal{T}_{i}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{i}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \\ \mathcal{L}_{BC}\left(\boldsymbol{\theta}; \mathcal{T}_{b}\right) &=\frac{1}{\left|\mathcal{T}_{b}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{b}}\|\mathcal{B}(\hat{u}, \mathbf{x})\|_{2}^{2}\\ \mathcal{L}_{Data}\left(\boldsymbol{\theta}; \mathcal{T}_{data}\right) &=\frac{1}{\left|\mathcal{T}_{data}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{data}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \end{aligned} LPDE(θ;Tf)LIC(θ;Ti)LBC(θ;Tb)LData(θ;Tdata)=∣Tf∣1x∈Tf∑∥∥∥∥f(x;∂x1∂u^,…,∂xd∂u^;∂x1∂x1∂2u^,…,∂x1∂xd∂2u^)∥∥∥∥22=∣Ti∣1x∈Ti∑∥u^(x)−u(x)∥22=∣Tb∣1x∈Tb∑∥B(u^,x)∥22=∣Tdata∣1x∈Tdata∑∥u^(x)−u(x)∥22
w f w_{f} wf, w i w_{i} wi、 w b w_{b} wb和 w d w_{d} wd是权重。 T f \mathcal{T}_{f} Tf, T i \mathcal{T}_{i} Ti、 T b \mathcal{T}_{b} Tb和 T d a t a \mathcal{T}_{data} Tdata表示来自PDE,初值、边值以及真值的residual points。这里的 T f ⊂ Ω \mathcal{T}_{f} \subset \Omega Tf⊂Ω是一组预定义的点来衡量神经网络输出 u ^ \hat{u} u^与PDE的匹配程度。 - 最后,利用梯度优化算法最小化损失函数,直到找到满足预测精度的网络参数 KaTeX parse error: Undefined control sequence: \theat at position 1: \̲t̲h̲e̲a̲t̲^{*}。
值得注意的是,对于逆问题,即方程中的某些参数未知。若只知道PDE方程及边界条件,PDE参数未知,该逆问题为非定问题,所以必须要知道其他信息,如部分观测点 u u u 的值。在这种情况下,PINN做法可将方程中的参数作为未知变量,加到训练器中进行优化,损失函数包括Data loss。
3.求解问题定义——正、逆问题
不可压缩流体可以由如下NS方程求解:
u t + λ 1 ( u u x + v u y ) = − p x + λ 2 ( u x x + u y y ) v t + λ 1 ( u v x + v v y ) = − p y + λ 2 ( v x x + v y y ) \begin{aligned} &u_t+\lambda_1\left(u u_x+v u_y\right)=-p_x+\lambda_2\left(u_{x x}+u_{y y}\right) \\ &v_t+\lambda_1\left(u v_x+v v_y\right)=-p_y+\lambda_2\left(v_{x x}+v_{y y}\right) \end{aligned} ut+λ1(uux+vuy)=−px+λ2(uxx+uyy)vt+λ1(uvx+vvy)=−py+λ2(vxx+vyy)
正问题:
- 参数 λ 1 = 1 \lambda_{1}=1 λ1=1, λ 2 = 0.01 \lambda_{2}=0.01 λ2=0.01为已知参数,该问题为已知边界条件和微分方程,求解 u,v,p 。
逆问题: - 参数 λ 1 , λ 2 \lambda_{1},\lambda_{2} λ1,λ2为未知参数,该问题为已知边界条件和微分方程,,但方程中参数未知,求解 u,v,p 以及方程参数。
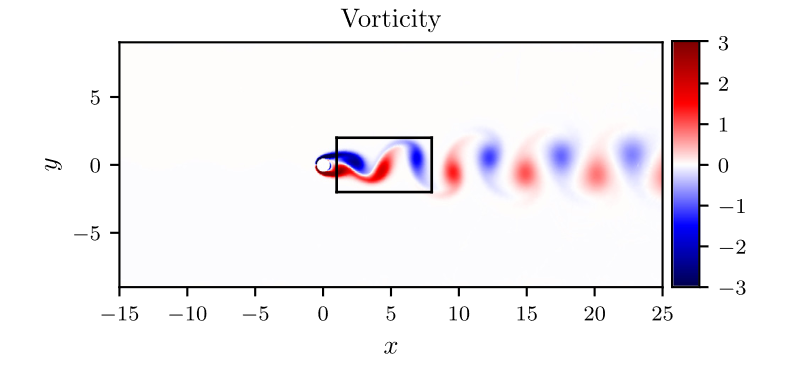
考虑如图2所示长方形区域内,求解不可压缩流场,特别地,流体方程的解同时满足divergence-free functions,可以表述为:
u x + v y = 0 u_x+v_y=0 ux+vy=0
网络,输出应该为三维( u , v , p u,v,p u,v,p ),但在求解过程,可引入latent function, ψ ( x , y , t ) \psi(x,y,t) ψ(x,y,t) ,满足,
u = ψ y , v = − ψ x u=\psi_y, \quad v=-\psi_x u=ψy,v=−ψx
网络输出,则可表示为二维( ψ , p \psi,p ψ,p)。
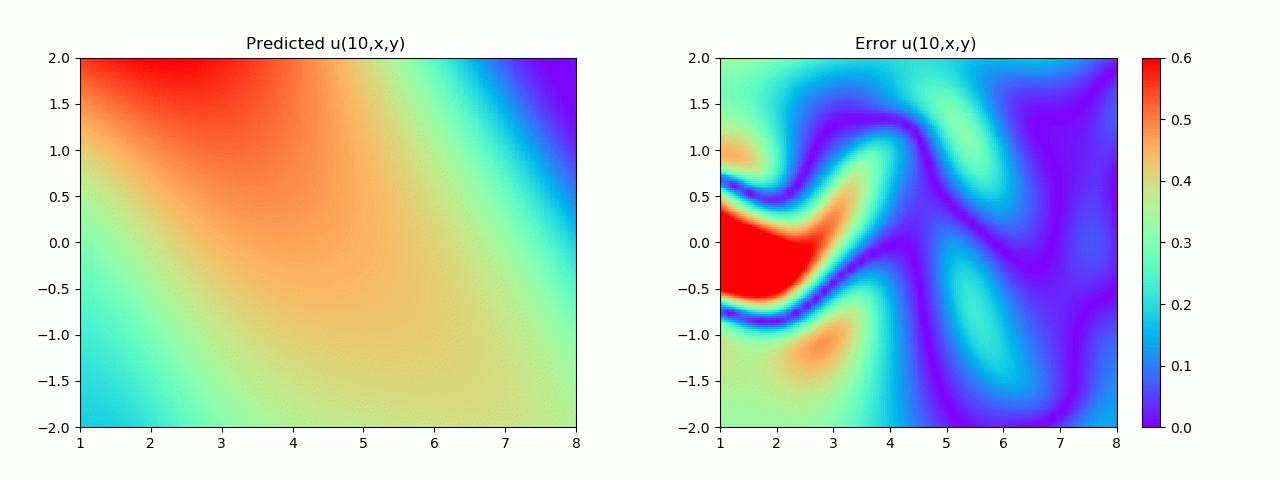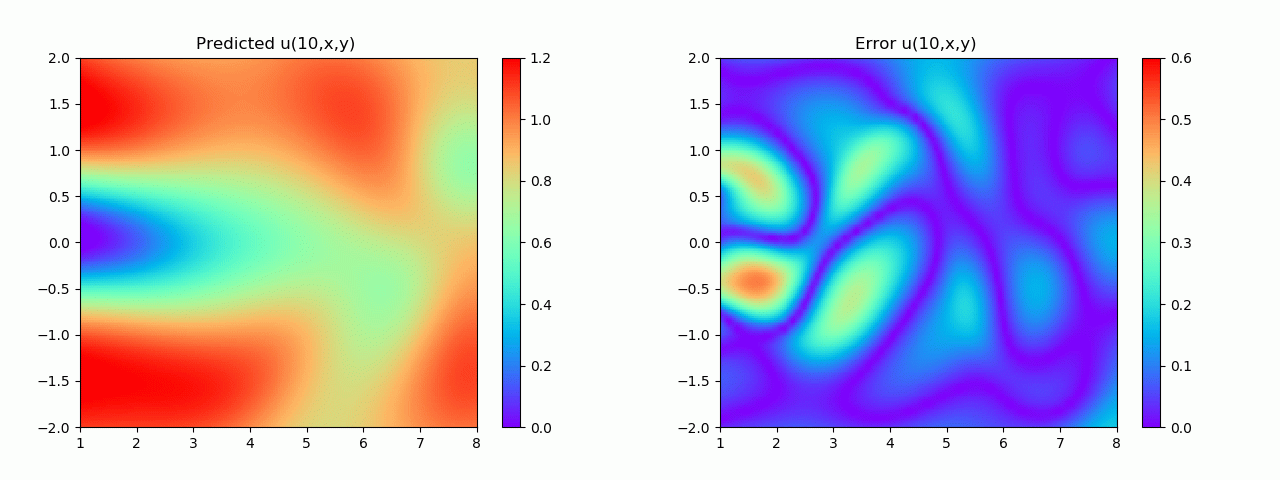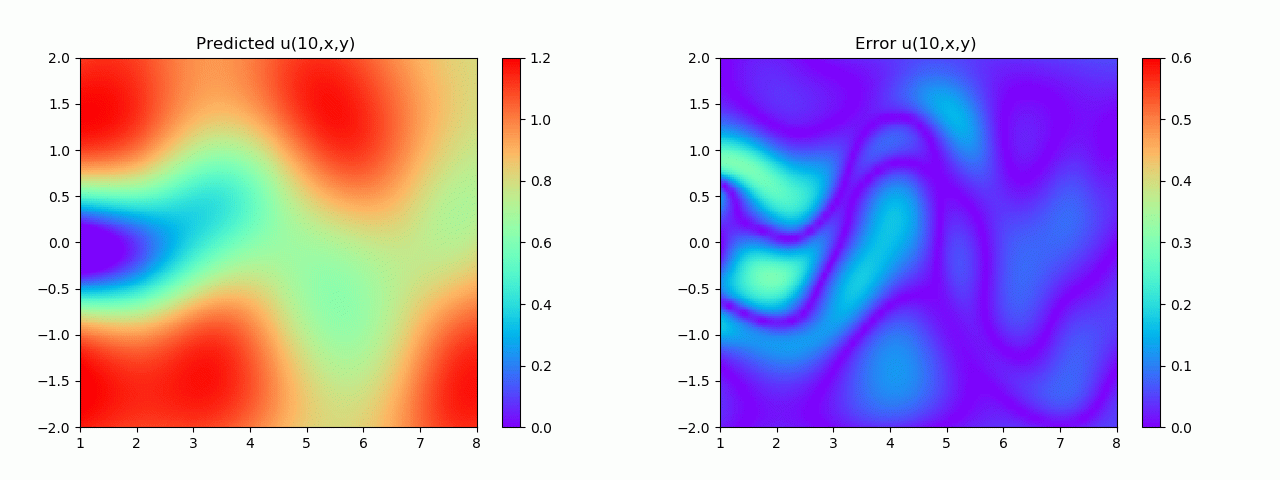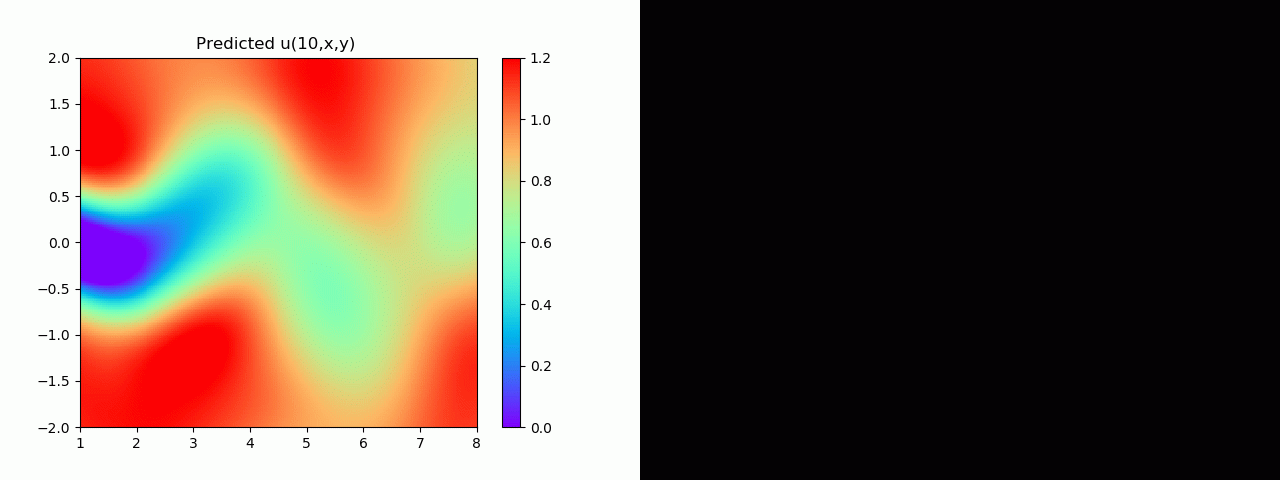
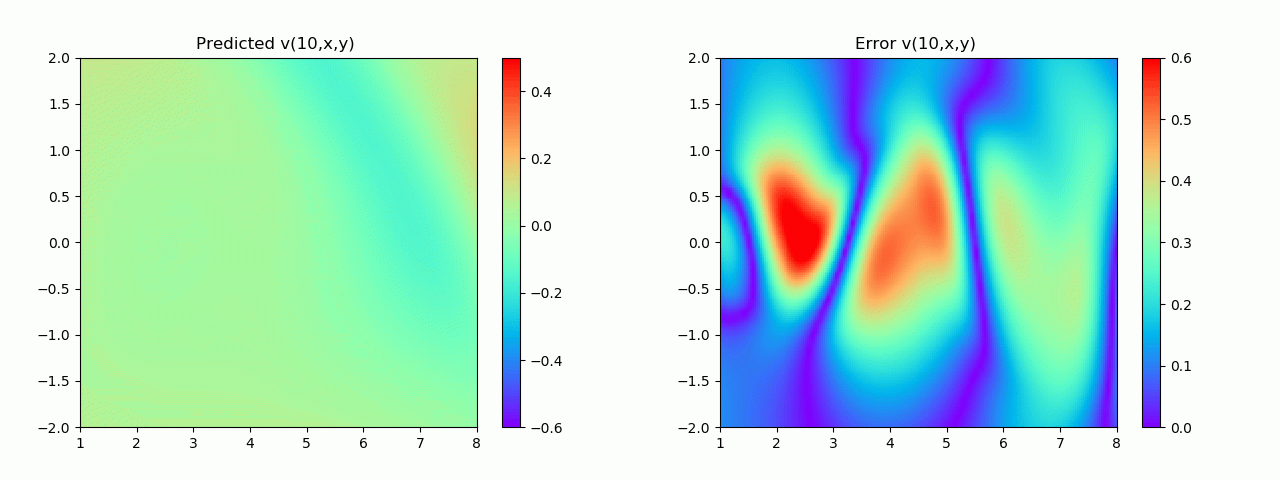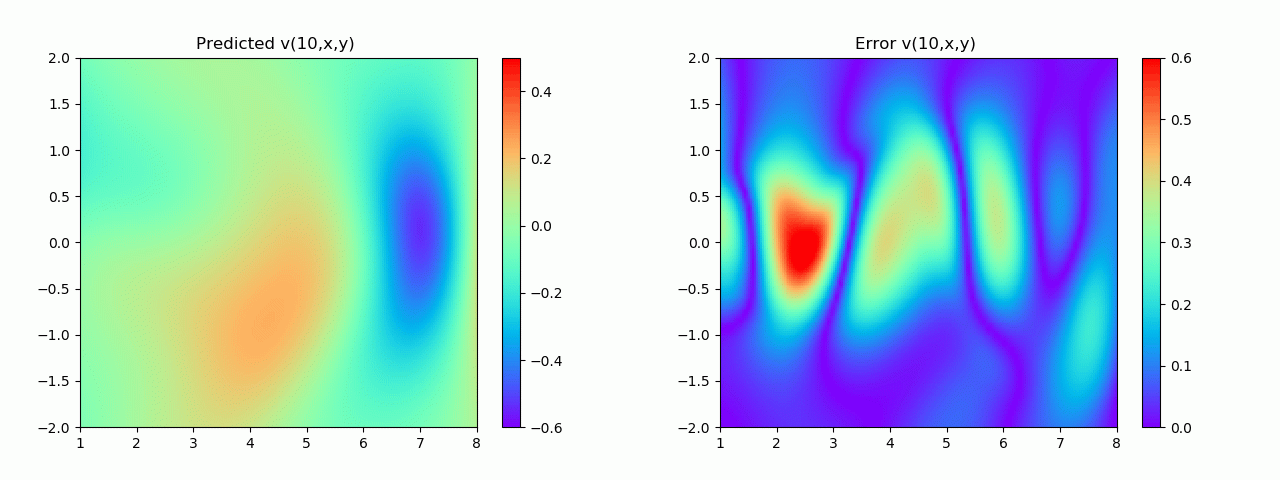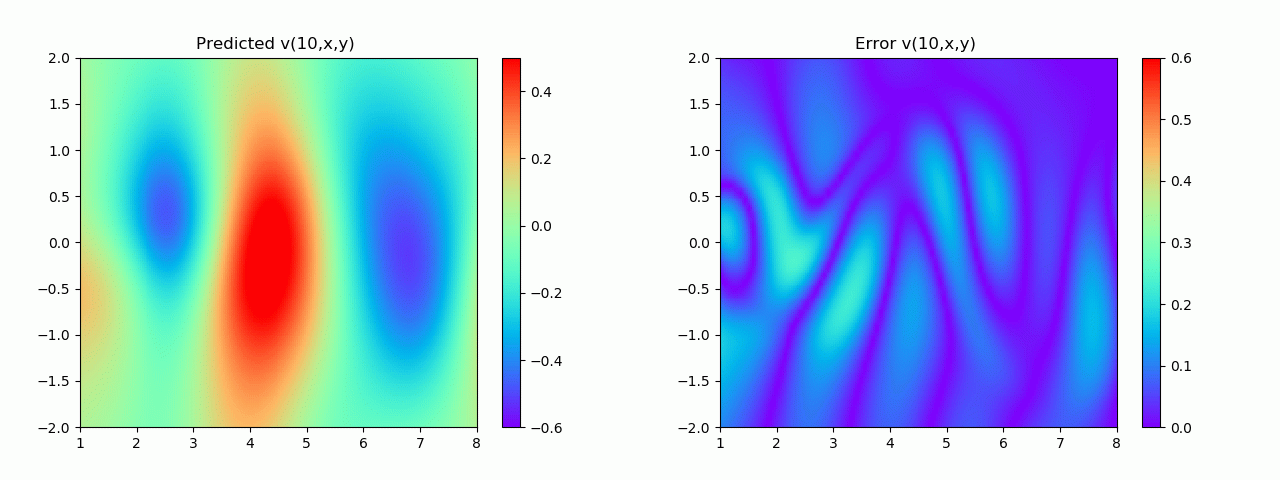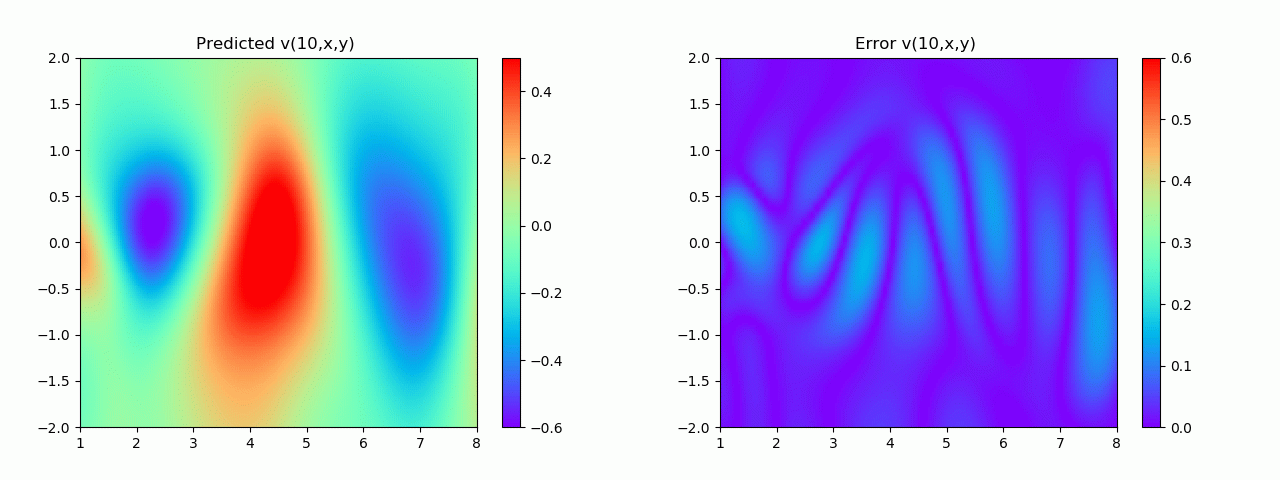
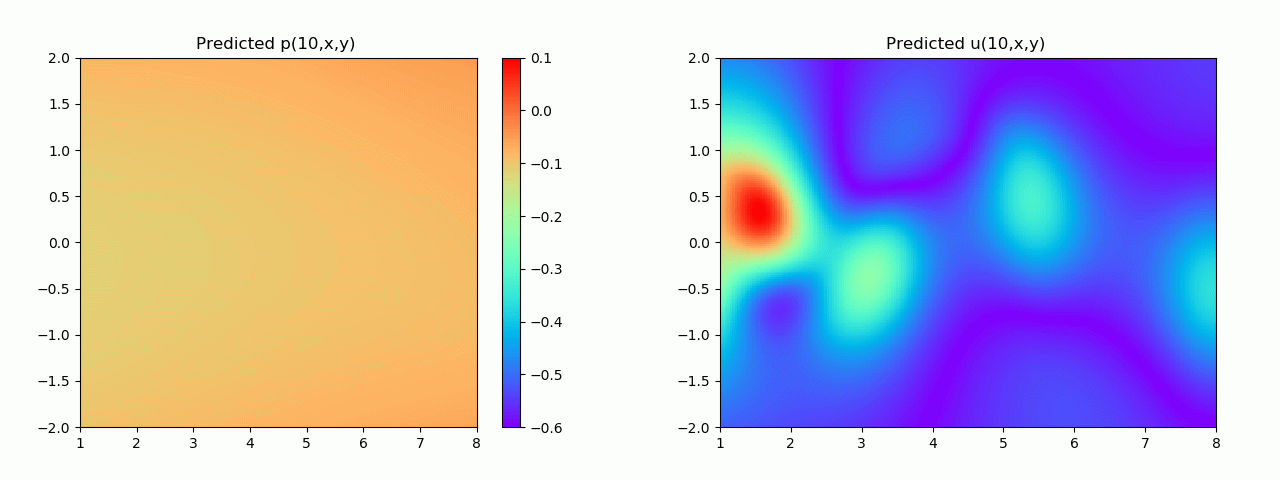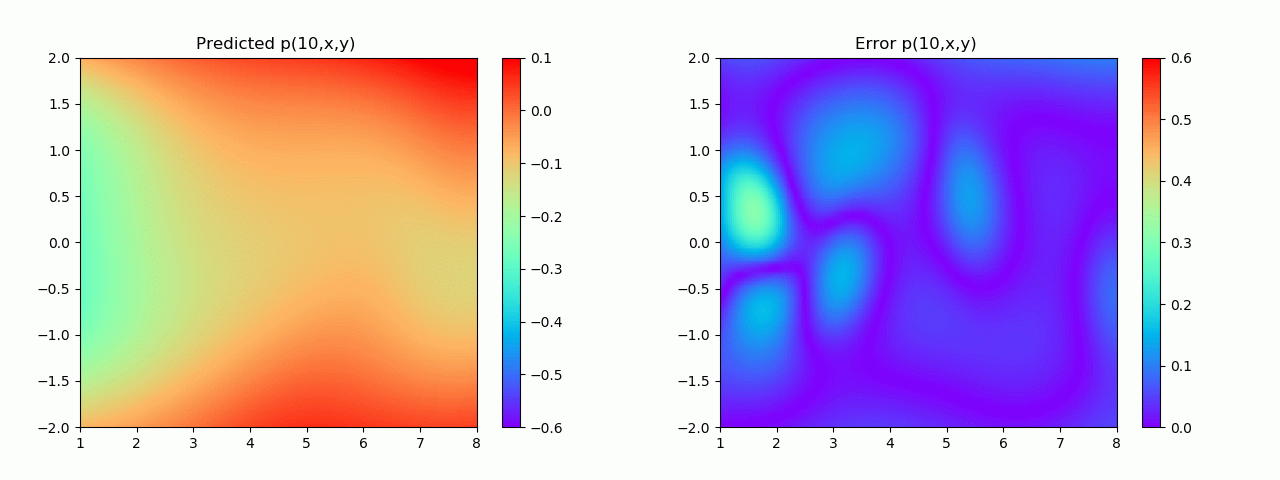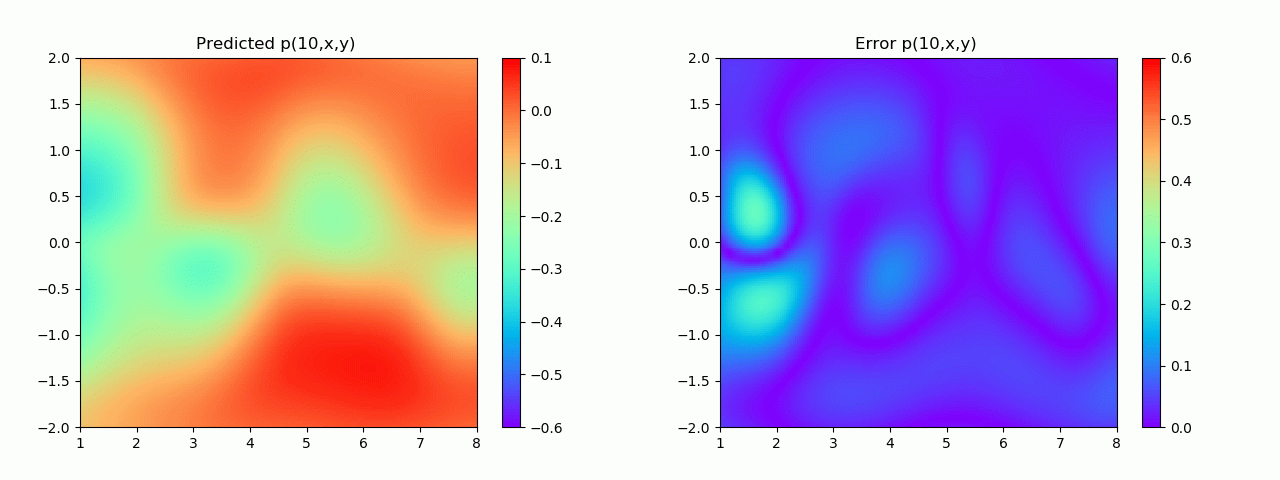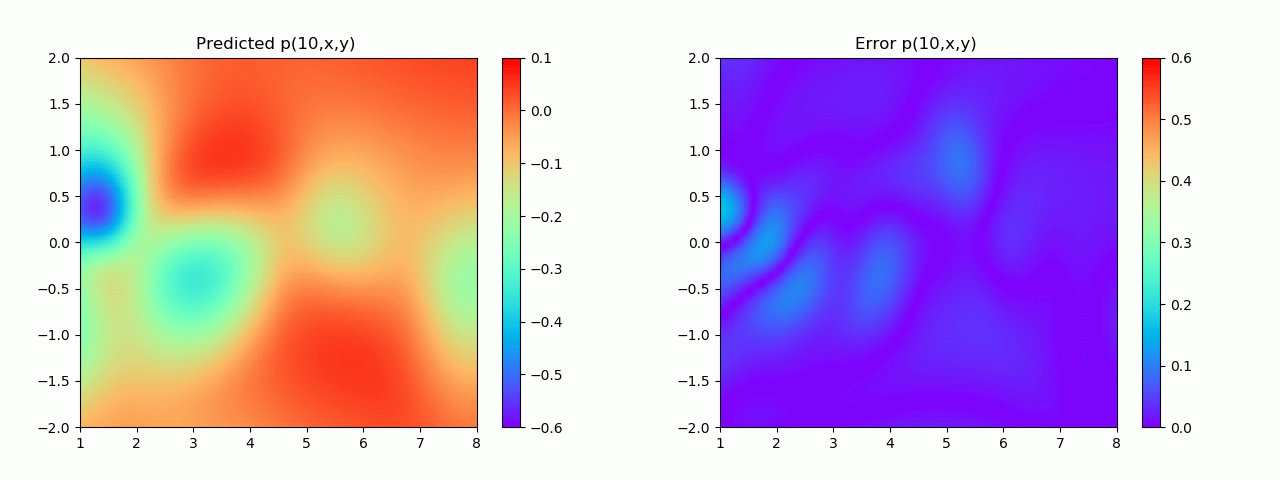
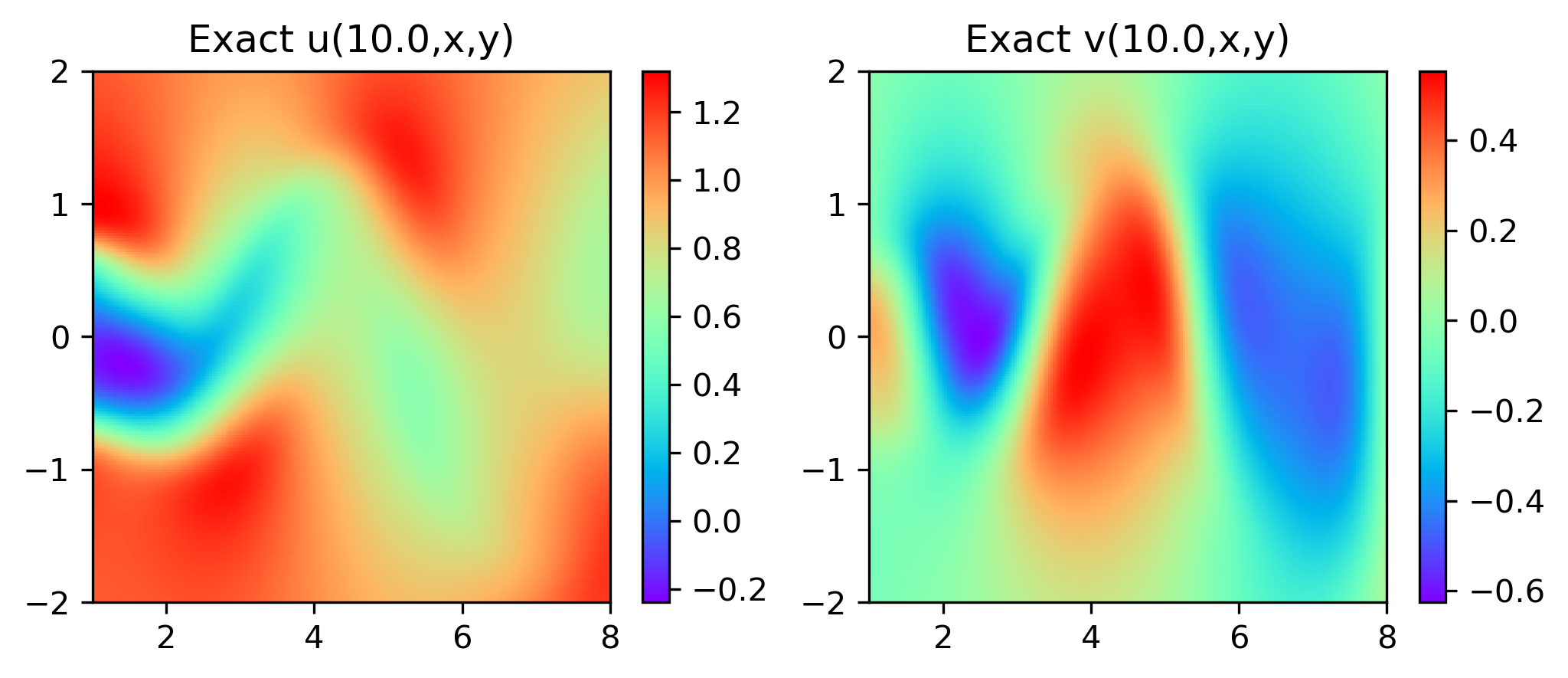
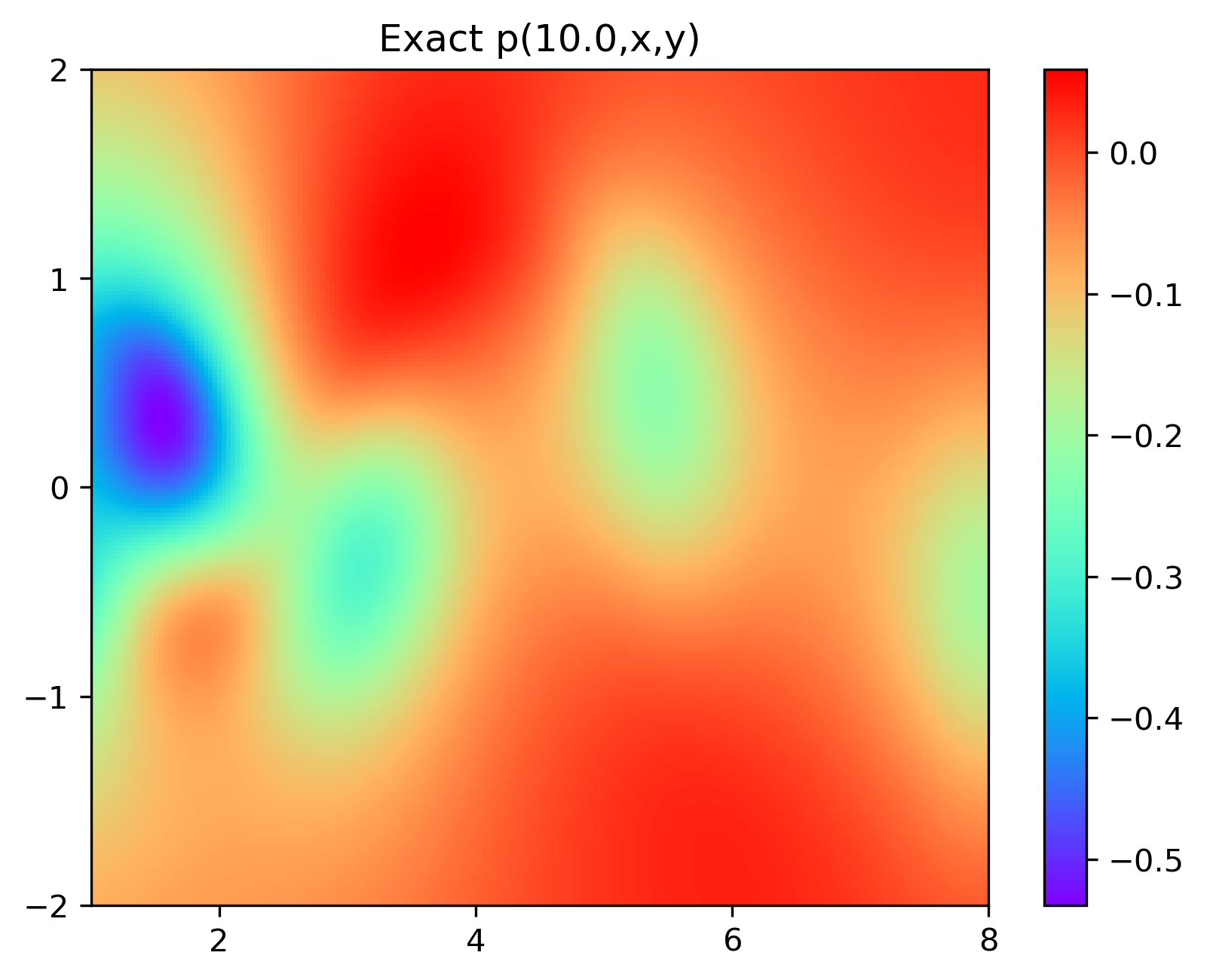
特别地,为了展示效果,这里我们选择10s下的流场对比预测效果。
4.结果展示
4.1 正问题实验结果
实验结果如图6-8所示,通过训练,PINN能实现u,v,p的准确预测