论文链接
论文代码
数据集:NYU-V2,Make3D,Sintel,Kitti
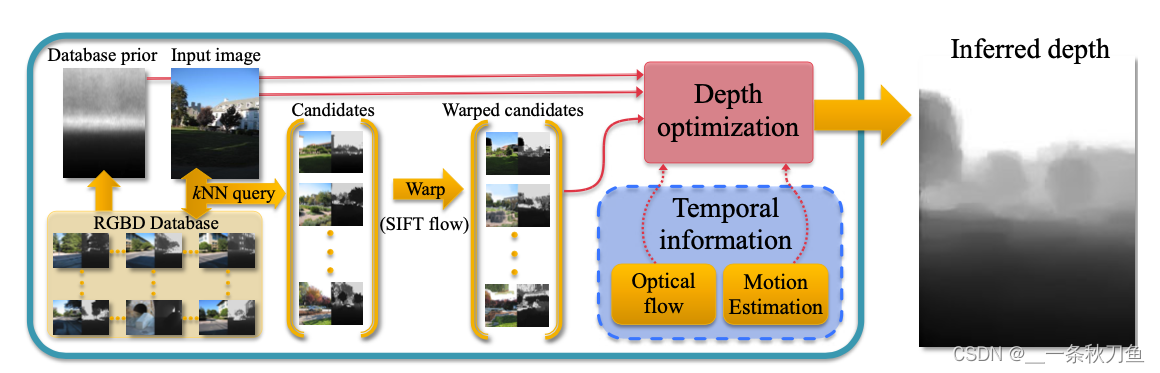
不同于其他主流方法以及深度学习方法,本文提出的方法并没有一个特定的模型完成深度估计,而是通过把已有的dataset标签数据与给定的待预测样本进行对应,并将深度信息进行迁移。
具体分为三个步骤:
- 在RGBD数据集中寻找多幅与待预测图像*高维特征(GIST和optical flow)*相似的图片。在这一步中,作者选出了7个相似帧,并且确保数据集中的每个视频最多贡献一张帧,以保证多样性。(但这一步会造成处理时间长?,并且十分依赖于给定的数据集?)
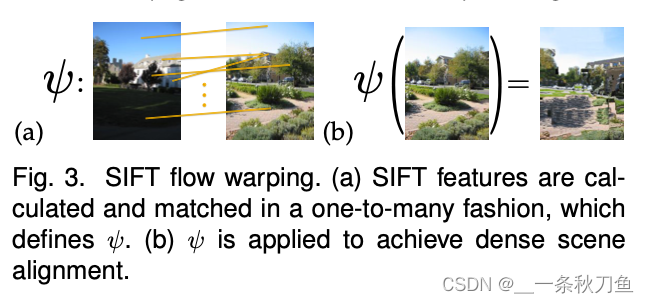
- 将选出的相似图片变形,使其与待预测图像对应,得到初步的深度估计结果。这里的变形引用SIFT (scale invariant feature transform)
- 进行全局优化,得到pixel level的深度图。
对于Video,作者也做了优化。如果是逐帧预测的话,可能会忽略视频原本的时间连续和时间依赖,因此对于video的energy function,作者加入了Ec: temporal coherence, Em: motion cues,系数分别是100和5。
与深度学习黑盒模型不同的是,这篇文章所用的方法是通过相似图片的匹配以及其深度图的迁移来计算待预测图像的深度图。