这是我很久之前看的一篇文章,内容挺简单的,好复现。
可以在arxiv上找找看。
摘要
Abstract—Video compression aims to remove spatial-
temporal redundancies where the encoded bitstream, particu-
larly the motion vectors, may not represent the actual motions
in the video. Hence, moving object detection in the compressed
video stream is a technically challenging task. In this work, we
propose a novel moving object detection algorithm using frame
sub-sampling method in the state-of-the-art HEVC video coding
standard. Specifically, the number of frames is reduced by
means of (temporal) sub-sampling. The frames are re-encoded
using HEVC with the same environmental setting to amplify the
motion of the moving objects. Sub-sampling effectively increases
the motion intensity of the objects, which can be the significant
cue for detecting moving object while motions in the back-
ground still remain small. Motion vectors and INTRA coding
units of moving object obtained via frame sub-sampling and re-
encoding are selectively utilized to separate the background and
moving objects in the video. The segmented results are refined
and compared with the result without performing frame sub-
sampling. Results show that the sub-sampling method achieves
higher accuracy, with an improvement greater than 0.35 in
terms of F-measure
视频压缩关键是在消除编码比特流(尤其是运动矢量)可能不代表视频中实际运动的空间时间冗余。因此,压缩视频流中的运动对象检测是一项技术上具有挑战性的任务。在这项工作中,我们提出了一种新的运动对象检测算法,采用最先进的HEVC视频编码标准中的帧子采样方法。具体而言,通过(时间)子采样来减少帧的数量。使用具有相同环境设置的HEVC对帧进行重新编码以放大运动对象的运动。子采样有效地增加了物体的运动强度,这可能是检测运动物体的重要线索,而背景中的运动仍然很小。通过帧次采样和重编码获得的运动目标的运动矢量和帧内编码单元被选择性地用于分离视频中的背景和运动目标。分割的结果被细化并且与没有执行帧子采样的结果进行比较。结果表明,子采样方法实现了更高的准确性,就F度量而言,其改进大于0.35。
主要内容
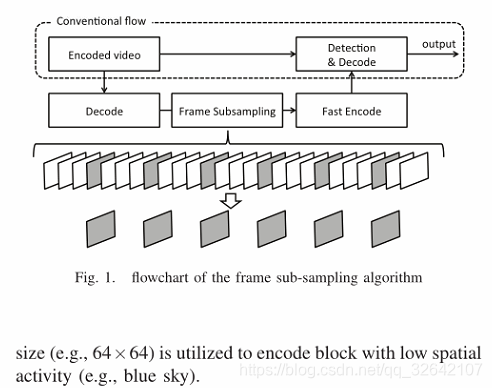
HEVC中帧间DCT系数出现了较大的数目,并不代表视频的实际纹理信息,因为它们是原始运动估计CU与运动估计CU之间差异的DCT。因此,我们利用编码CU模式和MV来分割运动物体和背景区域。
在帧间,CU有两种编码模式,即:(i)帧内CU,其由帧内预测处理不具有任何MV(ii)帧间CU,其中MV(s)通过参考其参考帧被编码用于运动补偿。图2示出了在帧子采样之后CU和MV的结构的示例。这里,红色块表示帧内CU,绿色块表示帧间CU,绿色箭头表示MVs。
当CU以帧内模式编码时,这表明该CU与前一帧显着不同,因此,使用运动估计和存储估计误差编码成本更高。例如,当物体的移动非常大或物体意外出现时,采用这种编码方法。因此,我们直接选择以帧内模式编码的CU作为前景区域(即移动物体)。对于帧间CU,运动物体的MV通过帧子采样方法放大(在第三节中)。因此,由MVs组成的、幅度大于阈值TH的CUs被认为是运动目标区域。
具体而言,用MV表示的MVt(x,y)的量值用于分类,其中(x,y)是帧的空间位置,并且t是子采样帧索引。MVt(x,y)随后在帧t中由MV值MVMaxt的最大量值进行归一化,如下进一步的阈值处理:

TH是Otsu’s算法的阈值。当归一化MV大于阈值TH时,当前CU被标记为前景。 否则它被标记为背景。
背景和移动物体区域的分割通过简单的后处理进一步细化。这里,连接的前景区域被认为是要被消除的候选者。原始编码块大小(64×64,32×32,… 8×8)被直接视为检测输出,从而计算连续连接块的面积以去除背景中的错误检测区域。 如果连接的前景区域的面积小于16个8×8块的等效尺寸,则它将被消除(即,被认为是背景),否则它将保持为前景。 此外,如果小区域被分类为背景,但其周围区域被分类为前景,则小区域也将被标记为前景。
实验结果

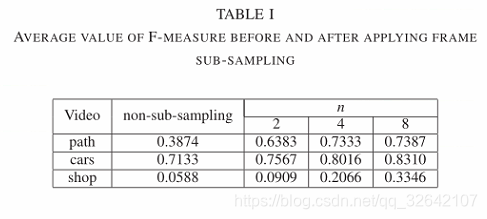
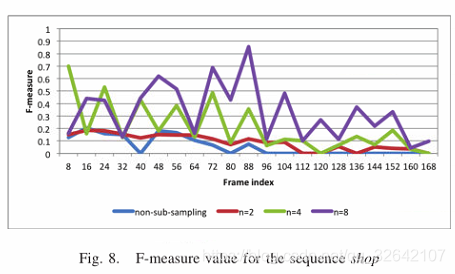
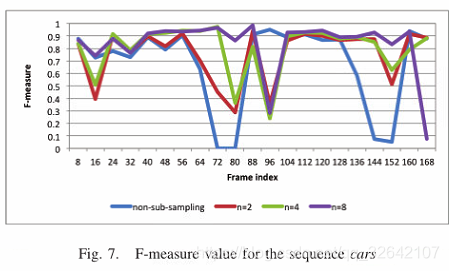
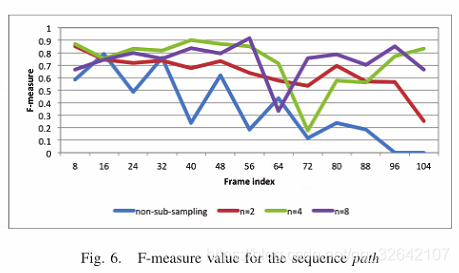
表1比较了应用提出的子采样方法之前和之后的不同参数值n的平均性能。在每个视频序列中,观察到具有二次采样的F测量的平均值高于非二次采样的平均值。此外,尽管F测量得分在序列路径和汽车中在n = 8处几乎饱和,但F越大,n越高。因此,我们得出这样的结论:通过执行所提出的帧子采样方法可以实现运动对象检测的更高性能。
