知识库可以分为两种类型,一种是以Freebase,Yago2为代表的Curated KBs,它们从维基百科和WordNet等知识库中抽取大量的实体及实体关系,可以把它们理解为是一种结构化的维基百科,被google收购的Freebase中包含了上千万个实体,共计19亿条triple。
知识库的另外一种类型,则是以Open Information Extraction (Open IE), Never-Ending Language Learning (NELL) 为代表的Extracted KBs,它们直接从上亿个网页中抽取实体关系三元组。与Freebase相比,这样得到的知识更加具有多样性,而它们的实体关系和实体更多的则是自然语言的形式,如“奥巴马出生在火奴鲁鲁。” 可以被表示为(“Obama”, “was also born in”, “ Honolulu”),当然,直接从网页中抽取出来的知识,也会存在一定的noisy,其精确度要低于Curated KBs。
Extracted KBs 知识库涉及到的两大关键技术是
- 实体链指(Entity linking) ,即将文档中的实体名字链接到知识库中特定的实体上。它主要涉及自然语言处理领域的两个经典问题实体识别 (Entity Recognition) 与实体消歧 (Entity Disambiguation),简单地来说,就是要从文档中识别出人名、地名、机构名、电影等命名实体。并且,在不同环境下同一实体名称可能存在歧义,如苹果,我们需要根据上下文环境进行消歧。
- 关系抽取 (Relation extraction),即将文档中的实体关系抽取出来,主要涉及到的技术有词性标注 (Part-of-Speech tagging, POS),语法分析,依存关系树 (dependency tree) 以及构建SVM、最大熵模型等分类器进行关系分类等。
属性和关系的最大区别在于,属性所在的三元组对应的,常常是一个实体和一个属性值,而关系所在的三元组所对应的是两个实体
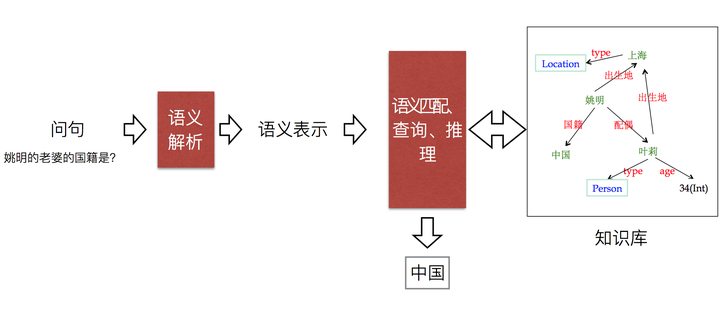
关于KB-QA的方法,个人认为 [1] ,传统的主流方法可以分为三类:
语义解析(Semantic Parsing):该方法是一种偏linguistic的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似lambda-Caculus)在知识库中进行查询,从而得出答案。下图红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。
向量建模(Vector Modeling): 该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示。模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。
KB-QA问题的Benchmark数据集——WebQuestion