语义解析KB-QA的思路是通过对自然语言进行语义上的分析,转化成为一种能够让知识库“看懂”的语义表示,进而通过知识库中的知识,进行推理(Inference)查询(Query),得出最终的答案。简而言之,语义解析要做的事情,就是将自然语言的问题,转化为一种能够让知识库“看懂”的语义表示,这种语义表示即逻辑形式(Logic Form)。
逻辑形式的具体内容参考: Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[J]. Proceedings of Emnlp, 2013.
解析的过程可以看作是自底向上构造语法树的过程,树的根节点,就是该自然语言问题最终的逻辑形式表达。整个流程可以分为两个步骤:
词汇映射:即构造底层的语法树节点。将单个自然语言短语或单词映射到知识库实体或知识库实体关系所对应的逻辑形式。我们可以通过构造一个词汇表(Lexicon)来完成这样的映射。
构建(Composition):即自底向上对树的节点进行两两合并,最后生成根节点,完成语法树的构建。这一步有很多种方法,诸如构造大量手工规则,组合范畴语法(Combinatory Categorical Grammars,CCG)等等,而我们今天要讲的这篇论文,采用了最暴力的方法,即对于两个节点都可以执行上面所谈到的连接Join,求交Intersection,聚合Aggregate三种操作,以及这篇文章独创的桥接Bridging操作(桥接操作的具体方式稍后会提到)进行结点合并。显然,这种合并方式复杂度是指数级的,最终会生成很多棵语法树,我们需要通过对训练数据进行训练,训练一个分类器,对语法树进行筛选。
构建词汇表
词汇表即自然语言与知识库实体或知识库实体关系的单点映射,这一操作也被称为对齐(Alignment)。可以使用一些简单的字符串匹配方式进行映射。
但是要将自然语言短语如“was also born in”映射到相应的知识库实体关系,如PlaceOfBirth, 则较难通过字符串匹配的方式建立映射。直觉上来说,在文档中,如果有较多的实体对(entity1,entity2)作为主语和宾语出现在was also born in的两侧,并且,在知识库中,这些实体对也同时出现在包含PlaceOfBirth的三元组中,那么我们可以认为“was also born in”这个短语可以和PlaceOfBirth建立映射。
待补充三元组统计的Trick
在实际使用中,我们可以通过词性标注(POS)和命名实体识别(NER)来确定哪些短语和单词需要被词汇映射(Lexicon),从而忽略对一些skipped words进行词汇映射。并且,作者还建立了18种手工规则,对问题词(question words)进行逻辑形式的直接映射.
构建语义树
完成词汇表的构建后,仍然存在一些问题。比如,对于go,have,do这样的轻动词(light verb)难以直接映射到一个知识库实体关系上,其次,有些知识库实体关系极少出现,不容易通过统计的方式找到映射方式,还有一些词比如actress实际上是两个知识库实体关系进行组合操作后的结果(actor\cap gender.female)(作者最后提到这个问题有希望通过在知识库上进行随机游走Random walk或者使用马尔科夫逻辑Markov logic解决),因此我们需要一个补丁,需要找到一个额外的二元关系来将当前的逻辑形式连接起来,那就是桥接。
训练分类器
分类器的任务是计算每一种语义解析结果d(Derivation)的概率.作者通过discriminative log-linear model进行modeling,使用Softmax进行概率归一化
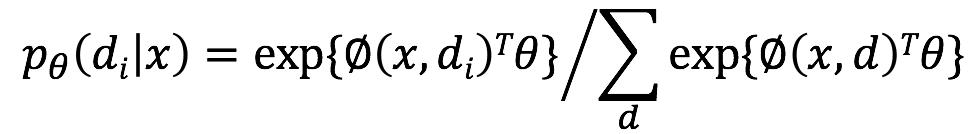
其中x代表自然语言问题,
是一个从语义解析结果
和x中提取出来的b维特征向量(该特征向量包含了构造该语法树所有操作的对应特征,每种操作的具体特征之后会提到),
是b维的参数向量。 对于训练数据问题-答案对
,最大化log-likelihood损失函数,通过AdaGrad算法(一种动态调整学习率的随机梯度下降算法)进行参数更新。
该方法有些什么缺陷?
首先,词汇映射是整个算法有效(work)的基点,然而这里采用的词汇映射(尤其是关系映射)是基于比较简单的统计方式,对数据有较大依赖性。最重要的是,这种方式无法完成自然语言短语到复杂知识库关系组合的映射(如actress 映射为(actor cap gender.female))。
其次,在答案获取的过程中,通过远程监督学习训练分类器对语义树进行评分,注意,这里的语义树实际的组合方式是很多的,要训练这样一个强大的语义解析分类器,需要大量的训练数据。我们可以注意到,无论是Free917还是WebQuestion,这两个数据集的问题-答案对都比较少。