上一篇:基于电影知识图谱的智能问答系统(五) --Spark朴素贝叶斯分类器
在上一篇博文中,我们利用朴素贝叶斯分类器(Naive Bayes Model)简单玩了一个男女性别分类的demo,如果你细心的从头到尾跟了一遍demo并进行本机测试后,你会发现,其实分类器的工作原理很简单,总结一下,主要有五点:
1、生成(或外部文件加载)训练集样本 【样本:LabelPoint类型,再细一点就是double数组构造的稠密/稀疏向量】
2、生成(或外部参数传进)测试数据样本【样本:LabelPoint类型,再细一点就是double数组构造的稠密/稀疏向量】
3、根据训练样本集合由SparkContext实例创建出一个可以被并行操作的分布式数据集JavaRDD
4、贝叶斯分类器训练RDD【注意:这一步必须把上一步的JavaRDD类型转RDD后在交由分类器进行训练(train)】
5、贝叶斯分类器拿着测试数据样本跟训练的数据进行概率预测(predict),最后返回我们定义的类别标签号
由于本系列文章是和电影知识挂钩的,前面基于此预热了好几篇了,一直没有进入正题(不预热不行啊,如果一上来就进入主题,估计大伙会吃不消,除非你自己私下里有进行预热, ),接下来,我们继续.....
),接下来,我们继续.....
一、敲定训练样本集【数据集在文章最后会提供链接供大家参考】
(1)电影评分 == 训练样本数据集如下
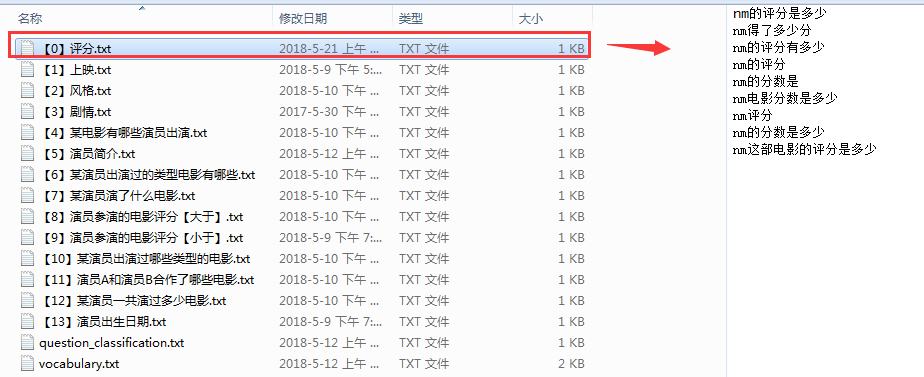
注:我先讲一下这个训练数据集是怎么敲定的,以及它的一些细节,比如,如果训练样本数据少了,会不会和其他的问题模板分类串频了,留个悬念,待会揭晓!!!
我们知道要想从电影知识系统里面查找某个电影的影评分数是多少,只需要确定两个字段条件就Ok了,比如,如果我知道电影名是《卧虎藏龙》,而我又知道查询的是这部电影的分数,那么,在neo4j中,就可以精确的match到答案了,如下:
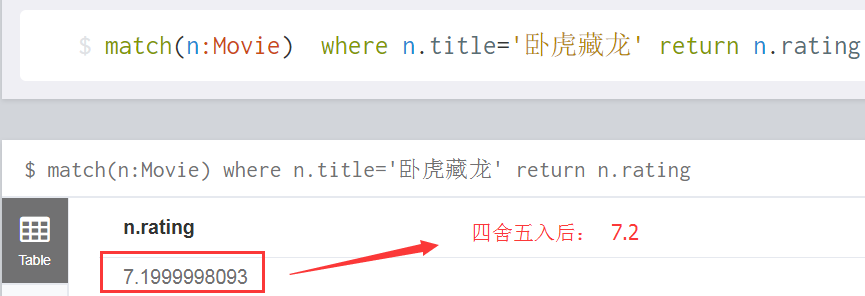
如何精准的从neo4j图库中匹配问题的答案呢?
由于关于电影的分数自然语句的问法有好几种,比如上述中设定好的问题集合
nm的评分是多少
nm得了多少分
nm的评分有多少
nm的评分
nm的分数是
nm电影分数是多少
nm评分
nm的分数是多少
nm这部电影的评分是多少而我们需要精确的答案,针对上述这些问题集合,我们有必要将其归为一类,问来问去,其实主题思想就一个
nm 分数
如何进行问题模板的分类划分呢?
别忘了,上一篇我们可是预热过了朴素贝叶斯分类器的用法的,本篇直接拿来用!!!
(2)电影评分的分类Model == 标签号如下
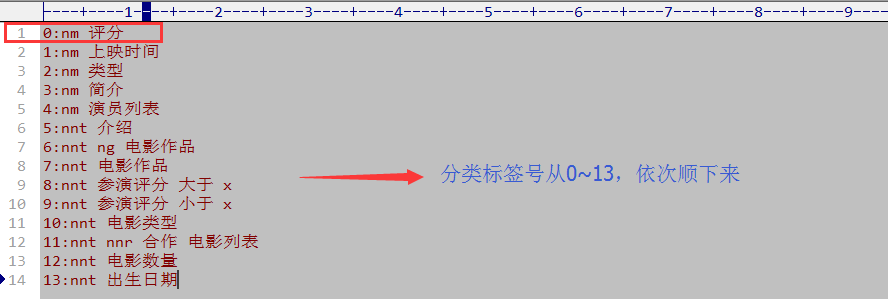
还记得上一篇这行demo吗?

对照我们设定的 0:nm 评分问题模板,可以在deom中替换成
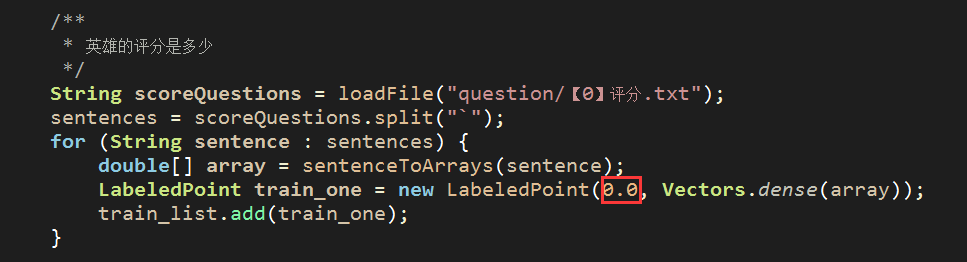
(3)如何构造稠密向量,也就是LabelPoint的第二个参数
我们需提取训练样本数据里面的关键特征词,如: “评分”、“多少”
就像上一篇样本数据集男性的特征有:“短发”、“喉结”、“运动鞋”一样
如何提取?
当然是采用HanLP进行分词提取了,而我们构造向量的时候,一定要有个词汇数据集进行比对,有的话,就置为1,没有话就默认0,像这样
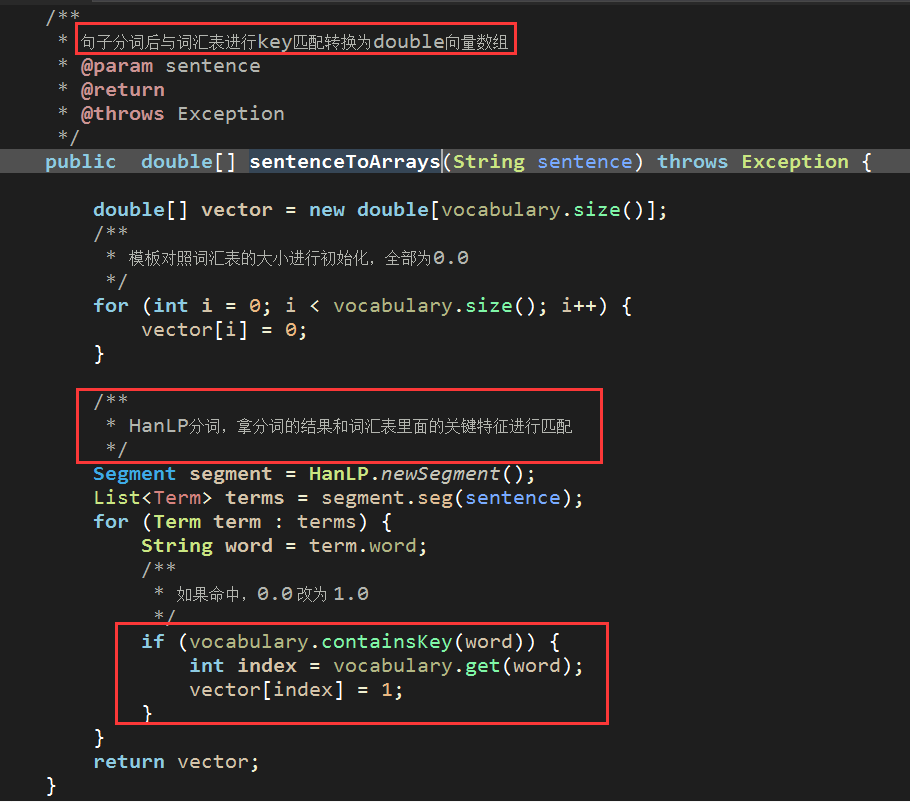
因此,我们需要提供demo中的vocabulary数据集,而这个数据集我已经添加过了,如下:


这样的话,nm的评分是多少构建向量的效果如下:
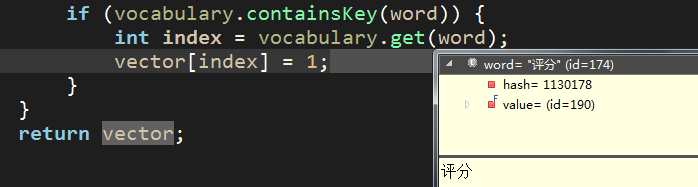
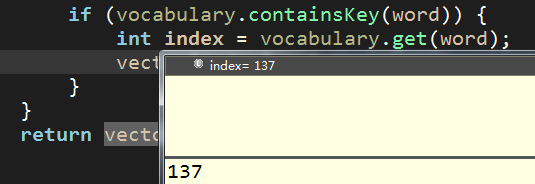
index = 137 【对应词汇表中的key值】
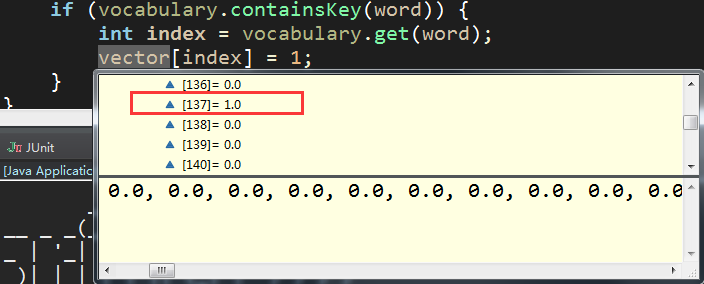
找到后,double向量数组该处设置为1 【其余分词特征不再一一演示说明】
(4)利用Spark朴素贝叶斯分类器对问题测试数据进行分类
注:测试数据也是需要构造向量的,构造向量的方法和训练样本构造向量的方式一样,都是对数据先进行HanLP分词拿到特征词后,与特征词汇表进行比对构造double数组的,如下【sentenceToArrays为数据转double数组的通用方法】:

万事俱备,只欠东风! == 有了样本集,也有了测试数据,我们来演示一下贝叶斯分类器如何对测试数据进行问题模板的分类
测试demo截图如下:【文章最后会放出数据集和贝叶斯分类器核心单元ModelProcess】
运行效果如下:

注:由于在测试单元中我们没有对HanLP的自定义词典进行个性化设置,因此,这里的卧虎藏龙没有被完整的识别,请忽略!
完整演示如下【先忽略查询结果,这个放在下一篇结合neo4j的查询语句再一起讲】:

二、训练样本集不容忽视的问题
上一篇我们提到了,要想分类的结果更精确,就只能让训练样本集更加的多,还拿电影评分这个训练集来说,如果我们把样本数据改为一行的话,如下

我们看一下,再问一次:卧虎藏龙的分数是多少,会出现什么情况
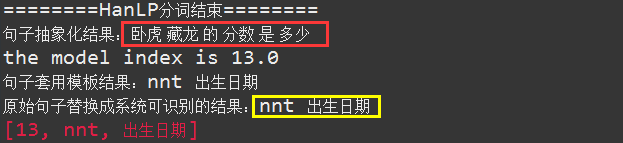
我去,这回分类的结果居然匹配到了问题模板13,我们看一下13这个训练集样本都有哪些

首先这个13的训练样本有好几个,而且其中关于“多少”的特征词有两个【还不包括“的”、“是”】,如果比命中数的话,肯定是分类13对应的概率高一些,信不信我们看数据说话,如下:
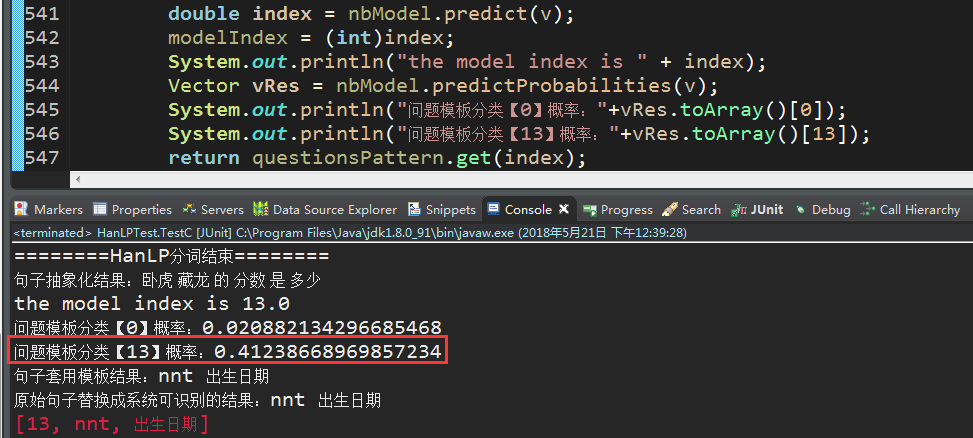
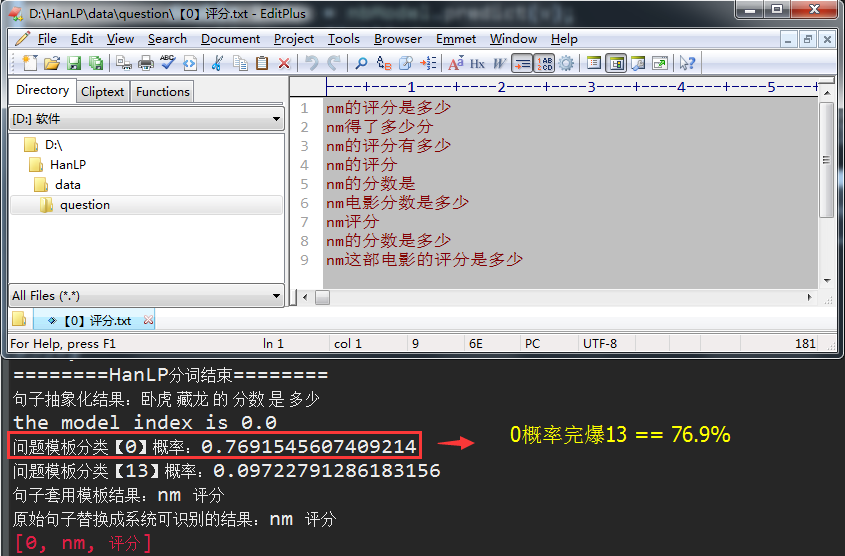
由于分类0的训练集太少了,导致最后的结果串频了,不是我们想要的,唯一补救的措施,就是不断的调整训练集的样本数,使得问题的归类结果更加的精确,比如,恢复到之前的样本数据集,我们再来测试一遍:
三、样本数据集和贝叶斯分类器核心代码下载链接

CSDN积分下载:电影知识图谱智能问答系统问题数据集+核心Core
百度云盘永久链接:电影知识图谱智能问答系统问题数据集+核心Core
四、最后附上本篇的单元测试demo
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.classification.NaiveBayes;
import org.apache.spark.mllib.classification.NaiveBayesModel;
import org.apache.spark.mllib.linalg.Vector;
import org.apache.spark.mllib.linalg.Vectors;
import org.apache.spark.mllib.regression.LabeledPoint;
import org.junit.Test;
import com.appleyk.process.ModelProcess;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.CustomDictionary;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.Term;
public class HanLPTest {
@Test
public void TestA(){
String lineStr = "明天虽然会下雨,但是我还是会看周杰伦的演唱会。";
try{
Segment segment = HanLP.newSegment();
segment.enableCustomDictionary(true);
/**
* 自定义分词+词性
*/
CustomDictionary.add("虽然会","ng 0");
List<Term> seg = segment.seg(lineStr);
for (Term term : seg) {
System.out.println(term.toString());
}
}catch(Exception ex){
System.out.println(ex.getClass()+","+ex.getMessage());
}
}
@Test
public void TestB(){
HanLP.Config.Normalization = true;
CustomDictionary.insert("爱听4G", "nz 1000");
System.out.println(HanLP.segment("爱听4g"));
System.out.println(HanLP.segment("爱听4G"));
System.out.println(HanLP.segment("爱听4G"));
System.out.println(HanLP.segment("爱听4G"));
System.out.println(HanLP.segment("愛聽4G"));
}
@Test
public void TestC() throws Exception{
ModelProcess query = new ModelProcess("D:/HanLP/data");
String[] questionArr = new String[] {"卧虎藏龙的分数是多少"};
for(String que: questionArr){
ArrayList<String> question = query.analyQuery(que);
System.err.println(question);
}
}
@Test
public void TestRDD(){
SparkConf conf = new SparkConf().setAppName("NaiveBayesTest").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
/**
* MLlib的本地向量主要分为两种,DenseVector和SparseVector
* 前者是用来保存稠密向量,后者是用来保存稀疏向量
*/
/**
* 两种方式分别创建向量 == 其实创建稀疏向量的方式有两种,本文只讲一种
* (1.0, 0.0, 2.0)
* (2.0, 3.0, 0.0)
*/
//稠密向量 == 连续的
Vector dense = Vectors.dense(1.0,0.0,2.0);
System.out.println(dense);
//稀疏向量 == 间隔的、指定的,未指定位置的向量值默认 = 0.0
int len = 3;
int[] index = new int[]{0,1};
double[] values = new double[]{2.0,3.0};
Vector sparse = Vectors.sparse(len, index, values);
/**
* labeled point 是一个局部向量,要么是密集型的要么是稀疏型的
* 用一个label/response进行关联
* 在MLlib里,labeled points 被用来监督学习算法
* 我们使用一个double数来存储一个label,因此我们能够使用labeled points进行回归和分类
* 在二进制分类里,一个label可以是 0(负数)或者 1(正数)
* 在多级分类中,labels可以是class的索引,从0开始:0,1,2,......
*/
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稠密向量模式 ,1.0:类别编号
LabeledPoint train_one = new LabeledPoint(1.0,dense); //(1.0, 0.0, 2.0)
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稀疏向量模式 ,2.0:类别编号
LabeledPoint train_two = new LabeledPoint(2.0,sparse); //(2.0, 3.0, 0.0)
//训练集生成 ,规定数据结构为LabeledPoint == 构建方式:稠密向量模式 ,3.0:类别编号
LabeledPoint train_three = new LabeledPoint(3.0,Vectors.dense(1,1,2)); //(1.0, 1.0, 2.0)
//List存放训练集【三个训练样本数据】
List<LabeledPoint> trains = new ArrayList<>();
trains.add(train_one);
trains.add(train_two);
trains.add(train_three);
//获得弹性分布式数据集JavaRDD,数据类型为LabeledPoint
JavaRDD<LabeledPoint> trainingRDD = sc.parallelize(trains);
/**
* 利用Spark进行数据分析时,数据一般要转化为RDD
* JavaRDD转Spark的RDD
*/
NaiveBayesModel nb_model = NaiveBayes.train(trainingRDD.rdd());
//测试集生成
double [] dTest = {2,1,0};
Vector vTest = Vectors.dense(dTest);//测试对象为单个vector,或者是RDD化后的vector
//朴素贝叶斯用法
System.err.println(nb_model.predict(vTest));// 分类结果 == 返回分类的标签值
/**
* 计算测试目标向量与训练样本数据集里面对应的各个分类标签匹配的概率结果
*/
System.err.println(nb_model.predictProbabilities(vTest));
//最后不要忘了释放资源
sc.close();
}
}下一篇:基于电影知识图谱的智能问答系统(七) -- Neo4j语句那点事