上一篇: 基于电影知识图谱的智能问答系统(二) -- Neo4j导入CSV文件
由于该项目后期会涉及到spark的朴素贝叶斯分类器,而该分类器可以通过训练问题集合进行问题模板概率匹配,因此,系统中是否搭建了spark环境对项目是否能run起来至关重要。
一、工具包及环境搭建简易说明
由于工具包比较大,涉及scala语言安装包、hadoop安装包以及spark-hadoop安装包,故只提供百度网盘的下载链接
下载地址:https://pan.baidu.com/s/10XUKpYBXqQ16UqDRTFerWg
二、Windows下Spark环境的搭建
本想着自己写个搭建过程,但是感觉没什么必要了,都是流水账了,推荐看下下面提供的博文,非常详细
三、验证Spark环境是否搭建成功
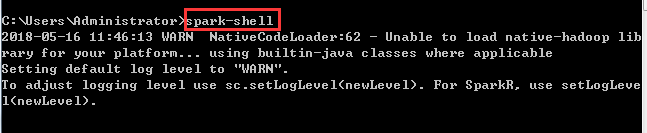
(1)任意目录下,运行 Win+R,并输入spark-shell脚本命令,测试spark
什么是spark-shell?
spark-shell是提供给用户即时交互的一个命令窗口,你可以在里面编写spark代码,然后根据你的命令进行相应的运算
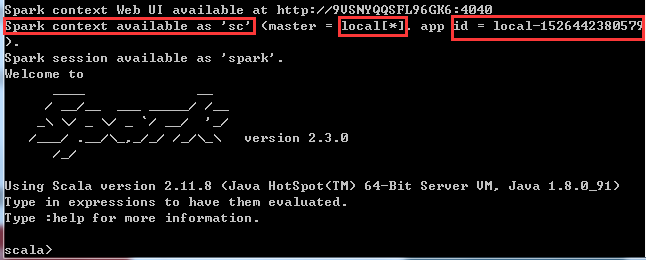
(2)实例化SparkContext对象
什么是SparkContext?
SparkContext是编写Spark程序用到的第一个类,其中包含了Spark程序用到的几乎所有的核心对象,可见其重要性
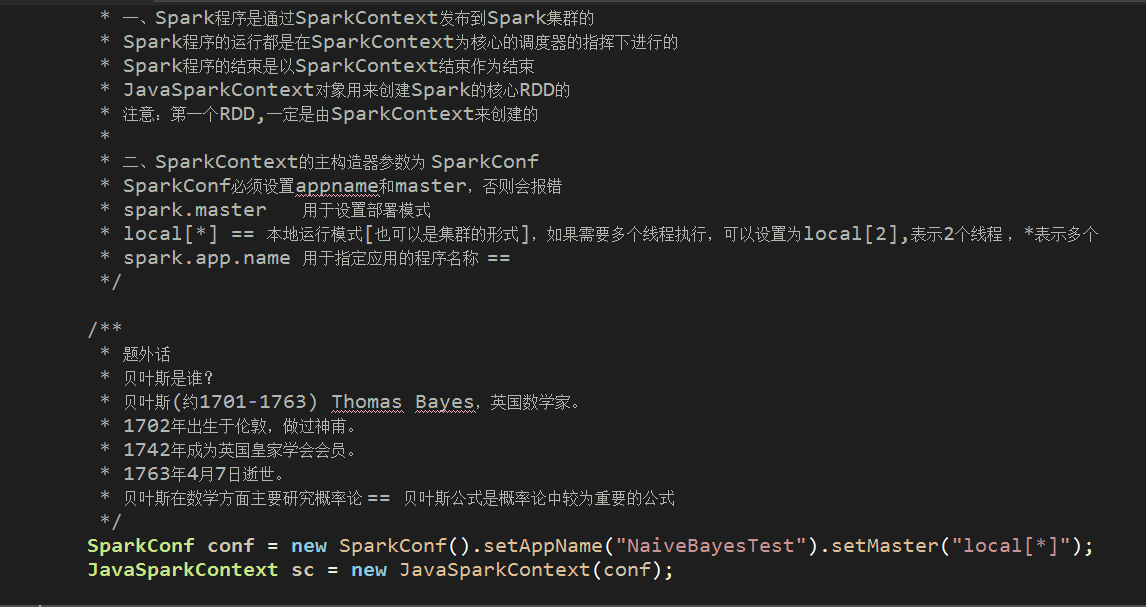
master:local[*] == 本地运行模式[也可以是集群的形式],*表示多个线程并行执行
在Java中实例化SparkContext对象的demo如下
(3)通过scala语言,编写spark代码,利用reduce计算集合1,2,3,4,5的和
通过调用SparkContext的parallelize方法,在一个已经存在的Scala集合上创建一个Seq对象。集合的对象将会被拷贝,创建出一个可以被并行操作的分布式数据集RDD
体现在Java中的demo如下

体现在脚本语言中如下:
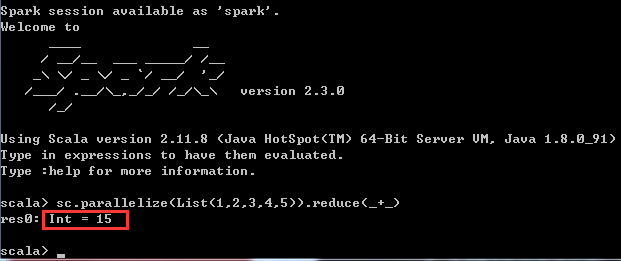
关于reduce,有点类似于Python的高阶函数reduce,有兴趣的可以参考我的博文:Python3学习(12)--高阶函数 (二)