一、什么是分词器?
分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具。到目前为止呢,分词器没有办法做到完全的符合人们的要求。和我们有关的分词器有英文的和中文的分词器:输入文本-关键词切分-去停用词-形态还原-转为小写中文的分词器分为:
单子分词 例:中国人 分成中,国,人
二分法人词 例:中国人 分成中国,国人
词典分词 例:中国人 分成中国,国人,中国人
现在用的是极易分词和庖丁分词
停用词:不影响语意的词
分词器有很多,比如中文分词器 IK Analyzer,有兴趣的可以看我的另一篇博文,其中有介绍它和Solr的结合使用
地址:Solr 7.2.1 配置中文分词器 IK Analyzer

欢迎你加入 邀请码 灵狐
二、什么是HanLP分词器?
首先:分词器≠自然语言处理!
其次:HanLP也是一种分词器
最后:HanLP不仅能够分词,而且还可以标注单词的词性(这个很关键的,后面章节会再次讲到这个特性)

比如,在Java中随便来个句子使用HanLP进行分词如下:
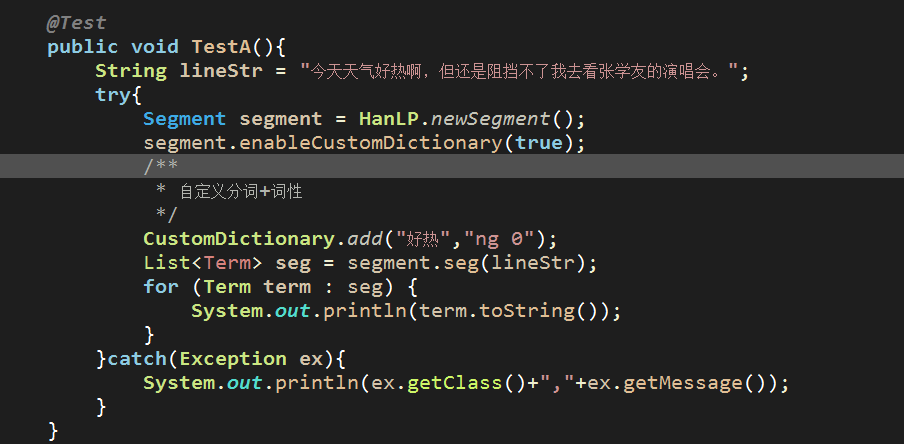
这里我们还额外添加了自己的分词,比如好热啊中的“好热”,我们添加后并标注其词性为ng,当然ng是我们随便起的
执行这段代码,分词效果如下

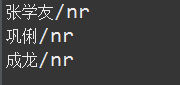
这种词性标注有什么好处呢? == 比如,所有人名均可以用nr这个标签来替代,思考下如下3个问题
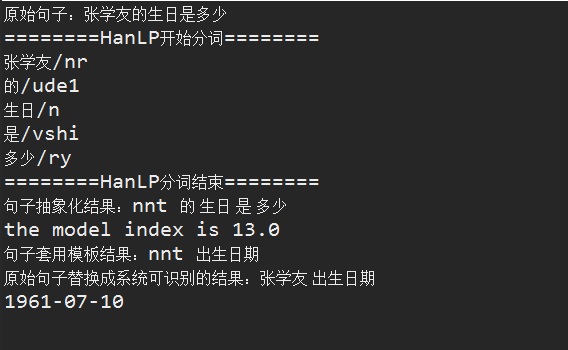
1、张学友的生日是什么时候
2、巩俐的生日是什么时候
3、成龙的生日是什么时候
如果用HanLP分词后,相信 张学友 、巩俐、成龙的词性均是nr,不信的话,请看下面的截图
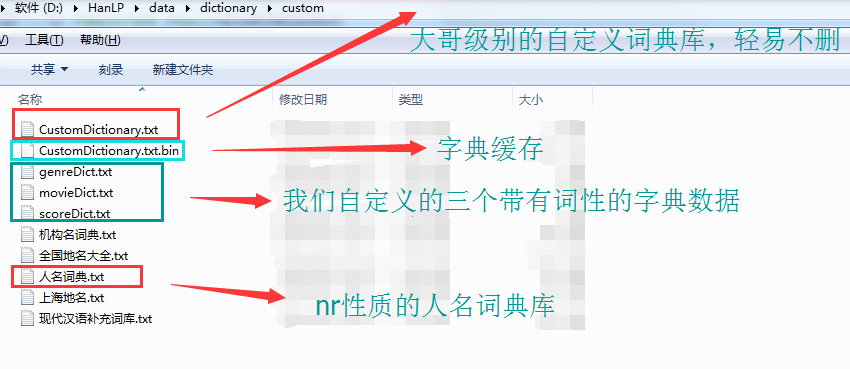
为什么HanLP会有这种能力呢? (博文下面会讲到如何在Spring-Boot项目中集成HanLP)
因为其有一堆的字/词典数据集,其中就包括了人名这个dict,如下
因此,针对1、2、3的问题,我们可以将其做成一个问题模板,如下
nr的生日是什么时候
于是乎,不管你问上述三个哪一个问题,我得到最终答案的步骤如下:
1、拿到原始句子(问题)
2、对原句子进行抽象,将人名用nr替换并抽象句子,比如张学友的生日是多少替换成nr的生日是多少
3、抽象句子匹配问题模板(一堆问题数据集合由Spark进行训练并计算),比如 nr 生日
4、问题模板还原成最终的问题,比如 nr 生日,替换其中的nr=张学友,最后效果就是 张学友 生日
5、拿到问题后,去图形数据库neo4j中查找问题的答案,比如

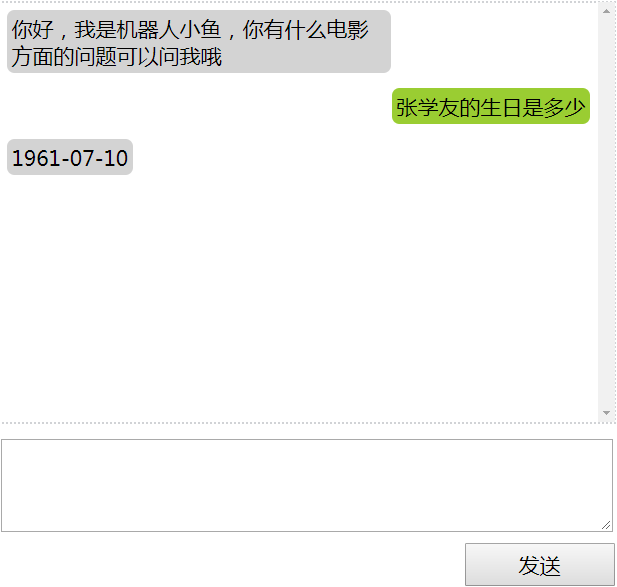
项目中使用HanLP+Spark的效果如下
前端展示如下
三、HanLP下载安装
官网下载地址:HanLP-汉语言处理包
这里我们采用第二种方式下载
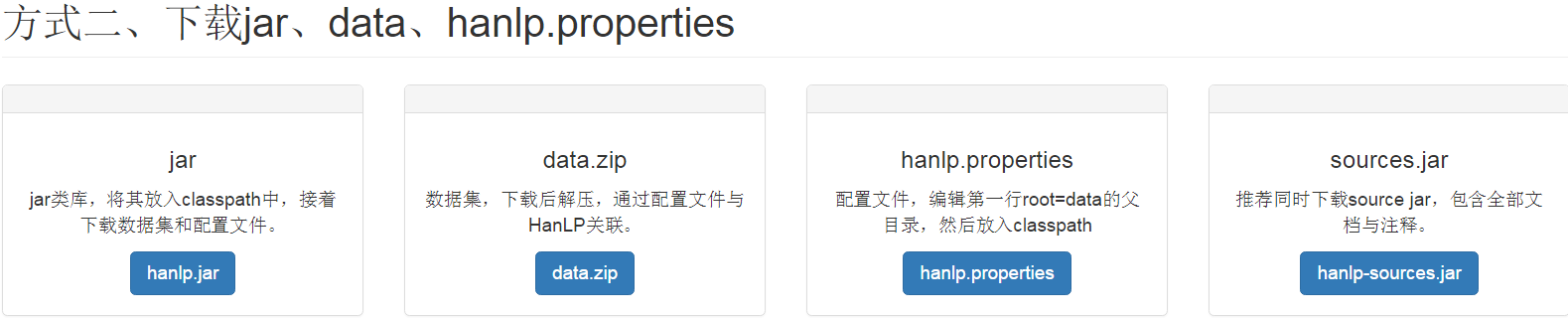
(1)由于我们要集成到Spring-Boot中,因此,我们不需要下载jar包,而是通过pom依赖进行jar添加,而这里,我们需要下载hanlp的配置文件
(2)下载完配置文件后,我们需要下载HanLP的字典数据集
github下载地址:https://github.com/hankcs/HanLP/releases
打开地址,我们找到数据包的下载链接:
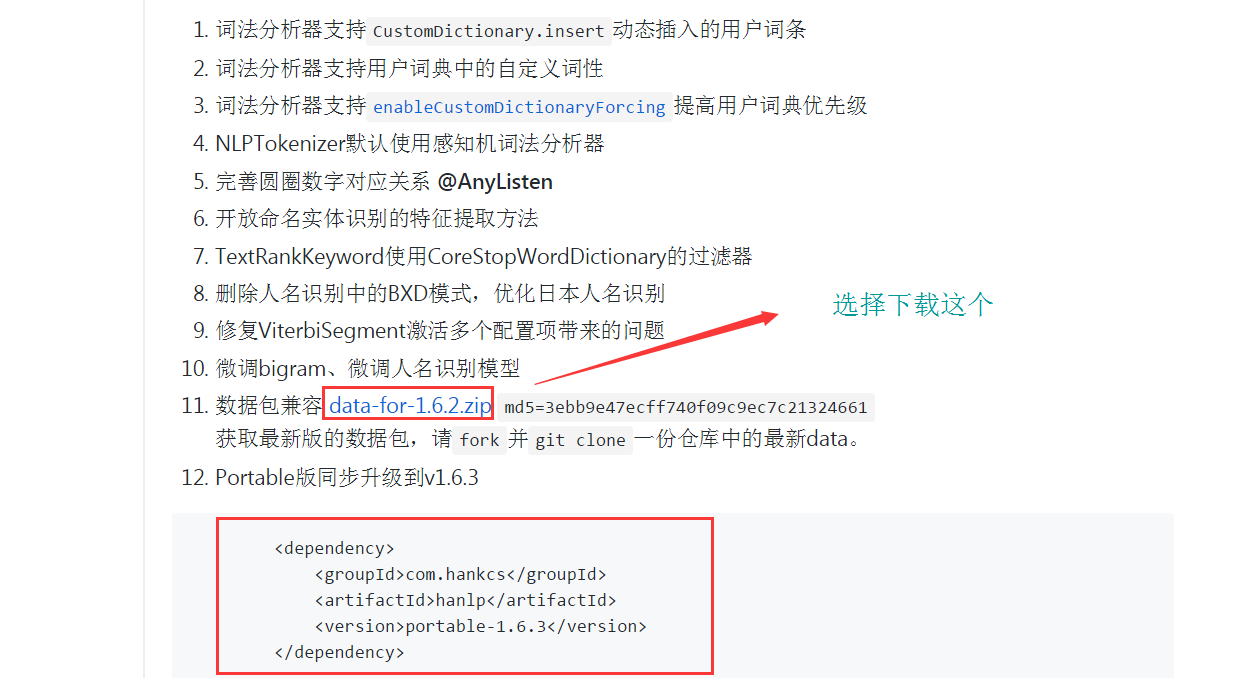
这个数据集有点大,下载会慢一点,请耐心等待下载完成
(3)上述两步完成后,接下来就是集成到我们的项目中使用了
四、Spring-Boot集成HanLP
(1)pom依赖
- <!-- JUnit单元测试 -->
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- </dependency>
- <!-- HanLP汉语言处理包 -->
- <dependency>
- <groupId>com.hankcs</groupId>
- <artifactId>hanlp</artifactId>
- <version>portable-1.6.3</version>
- </dependency>
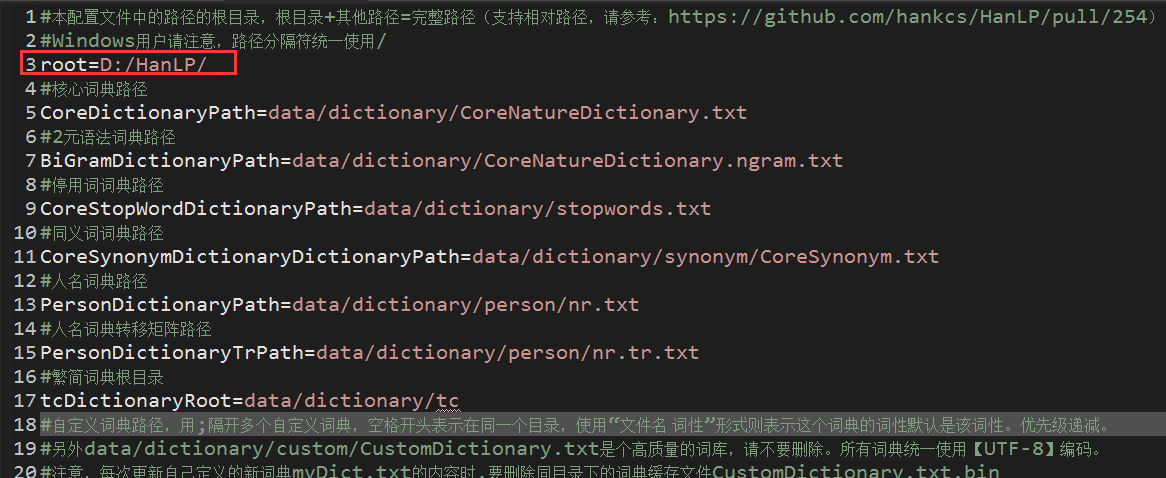
(2)添加HanLP属性配置文件【基于上述下载下来的】
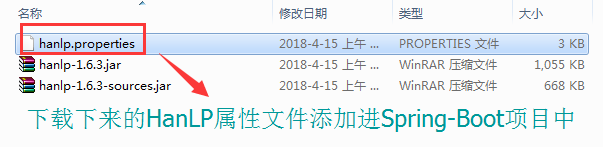
(3)hanlp.properties属性文件说明
其实也没有上面好说明的,文件里面的注释已经很详细了,唯一注意一点的是这个地方:
!每次更新自定义的新词典xxx.txt的内容时,要删除同目录下的词典缓存文件CustomDictionary.txt.bin!
删除后,重启项目会报一个警告的错误,我们不用理会,由于HanLP会加载数据集到内存中,因此启动的过程会有点慢,等待HanLP加载完数据后,我们就可以使用它了
五、HanLP单元测试
HanLPTest.java
- import com.hankcs.hanlp.HanLP;
- import com.hankcs.hanlp.dictionary.CustomDictionary;
- import com.hankcs.hanlp.seg.Segment;
- import com.hankcs.hanlp.seg.common.Term;
- public class HanLPTest {
- @Test
- public void TestA(){
- String lineStr = "明天虽然会下雨,但是我还是会看周杰伦的演唱会。";
- try{
- Segment segment = HanLP.newSegment();
- segment.enableCustomDictionary(true);
- /**
- * 自定义分词+词性
- */
- CustomDictionary.add("好热","ng 0");
- List<Term> seg = segment.seg(lineStr);
- for (Term term : seg) {
- System.out.println(term.toString());
- }
- }catch(Exception ex){
- System.out.println(ex.getClass()+","+ex.getMessage());
- }
- }
- }
执行结果如下:
- 明天/t
- 虽然/c
- 会/v
- 下雨/vi
- ,/w
- 但是/c
- 我/rr
- 还是/c
- 会/v
- 看/v
- 周杰伦/nr
- 的/ude1
- 演唱会/n
- 。/w