下面是一个简单的示意图:
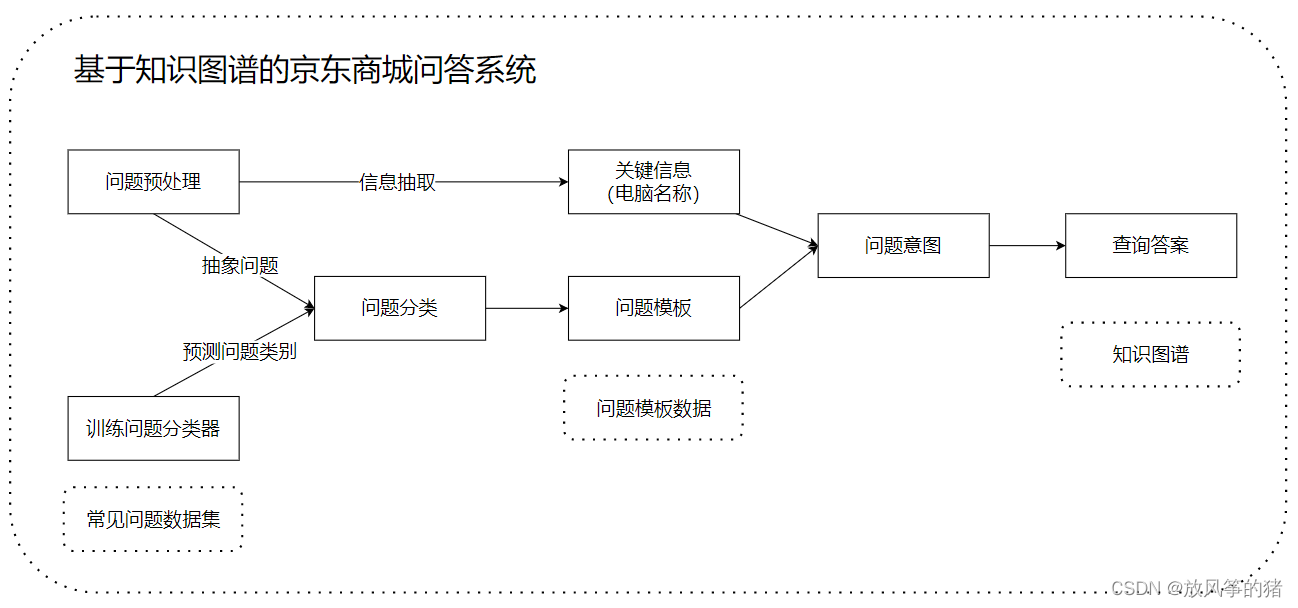
从示意图中可以看出:
主要的流程就是实现框的内容,不过在此之前需要做一些准备,就是虚线框中的内容。
- 问题预处理
问题预处理要做些什么事呢,这就要看看我们想要从问题中获取点什么东西了,首先我们想获取问题中的询问对象是什么,也就是主语,是那个名称的电脑,这就涉及到自然语言处理中的命名实体识别;接着我们还想从问题中了解到用户想问什么,也就是用户的意图,要了解用户意图,这就涉及到文本表示问题,最最基本的文本表示方法是one-hot形式,在试验中使用的是sklearn中的tfidf工具。
- 抽取关键信息
对于关键信息抽取中的命名实体识别,在实验过程中,在这一部分我们其实用的词性标注,因为词性标注工具可以把电脑名称标注出来,如下:
nm 评论只要我们把问题词性标注后,找到对应的nm对应的单词,那就是电脑名了。
- 训练问题分类器
我们要想搞清楚用户到底想问啥,是问购买电脑后的评论情况,还是某某电脑的配置怎么样?想想我们在思考这个疑问的过程中是不是把问题在脑海里面进行的分类处理,其实在自然语言处理中很多问题都可以抽象成分类问题。好,我们现在把用户想问啥抽象成了分类问题,那用户问题主要涉及到哪些方面,可以分成多少类呢?以及我们怎么识别这个用户问题属于那一类呢?一种最直接的方法就是把用户会问到的各个方面都列出来,然后分门别类,这样就解决了前两个问题。对于怎么识别用户的问题属于那一类呢?当然选择分类器啦,但是等等,训练分类器需要数据咋办。解决办法就是前面不是把用户问题分成了很多类嘛,对于每一类问题,想想用户会以什么样的方式来提问,然后我们把这些提问方式记录下来,这样得到了该类别问题所对应的训练数据。
nm的评论是多少
nm得了多少分
nm的评论有多少
nm的评分
nm的评论数是
nm电脑评论数是多少
nm评论
nm的评论数是多少
nm这太电脑的评论数是多少
nm的好评
nm好评率
nm好评
nm差评
nm速度
nm运行速度
nm反应
nm外观
nm画质
nm清晰
nm舒适
nm好评度
nm的好评度是多少
nm买的人多吗- 问题模板
在前面训练问题分类器中,我们把用户的问题归纳成了很多类,在这个模块下,我们要做的事就是对各个类别进行抽象,比如对于用户询问某某电脑的配置等一系列问题,我们可以把它抽象成:
nm 电脑配置这个nm,nnt只是个标签,是可以随便改的。
0:nm 评论
1:nm 价格
2:nm 类型
3:nm 简介
4:nm 配置
5:nnt 介绍
6:nnt 电脑重量
7:nnt 电脑评论数 大于 x
8:nnt 电脑好评度 大于 x
9:nnt 颜色
10:nnt 处理器
11:nnt 显卡
12:nnt 包邮
13:nnt 有货
14:nnt 快递
15:nnt 屏幕刷新率
16:nnt 固态
17:nnt 产地
18:nnt 厚度
19:nnt 屏幕色域- 查询答案
在知道用户想问啥的时候,我们就可以根据用户的要求来查询,得到答案返回,这部分主要是如何对图数据库进行操作。
好了,到了现在,你对主要的模块都了解了,然后最后我来串一哈,首先得到用户的问题,从用户的问题中得到问题的关键信息,主要电脑名称,接着是对问题进行分类,看问题想问什么,预测出问题模板,在得到问题模板后,使用人名或电影名等具体信息来替换模板中的抽象信息,得到一个新的问题,下面是一个实际的例子:
result=que.question_process("联想小新Pro14好评率")获取关键信息:联想小新Pro14
问题分类得到问题模板:0:nm 评论
进行替换得到新的问题:
联想小新Pro14 好评率
然后就根据这个新的问题来查询,获得答案返回。