paper:VarifocalNet: An IoU-aware Dense Object Detector
official implementation:https://github.com/hyz-xmaster/VarifocalNet
third-party implementation:mmdetection/vfnet_head.py at main · open-mmlab/mmdetection · GitHub
背景
目前的目标检测模型,大都是先生成一组冗余的检测框,然后通过NMS过滤掉同一对象的重复检测框,一般来说,NMS中都是用分类得分对检测框进行排序。但是这有可能会降低模型的性能,因为分类得分并不总是能很好的评估检测框的定位精度,而且精确定位但分类得分低的检测框有可能被NMS误删。
为了解决这个问题,现有的检测模型会预测一个额外的IoU score或centerness score来作为定位精度的评价指标,并把它们和分类得分相乘的结果作为NMS中排序的指标。这些方法可以缓解分类得分和定位准确度之间的不对齐misalignment问题,但结果是次优的sub-optimal,因为将两个不完美的预测结果相乘会得到一个更差的结果,并且作者通过实验证明了这种方法的性能上限是有限的。另外,添加一个额外的网络分支来预测定位得分并不是一个优雅的解决方案,而且会带来额外的计算。
本文的贡献
为了克服上述问题,自然会想问:与其额外预测一个定位精度得分,我们能否将其融入分类得分?即预测一个localization-aware或IoU-aware的分类得分(IACS),它可以同时表示某个对象的分类得分和定位精度得分。
本文的贡献具体如下
- 本文证明,准确地排序候选检测框对检测模型的性能至关重要,IACS实现了比其它方法更好的排序。
- 本文提出了一种新的损失函数Varifocal Loss来训练模型回归IACS。
- 本文设计了一种星状star-shaped的检测框表示方法,用于计算IACS以及精调refine检测框。
- 基于FCOS+ATSS和本文提出的新方法,设计了一个新的目标检测模型VarifocalNet,简称VFNet。
本文的方法如下图所示

Motivation
作者首先研究了FCOS模型的性能上限,确定了其主要的性能阻碍点,并展示了用IoU-aware的分类得分作为NMS排序指标的重要性。为了研究FCOS+ATSS的性能上限,作者交替用对应的ground truth值替换NMS之前foreground points预测的分类得分、距离偏移、centerness得分,并且评估其在COCO val2017上的AP。对于分类得分,有两个选择,一个是将gt位置处的元素替换为1或是预测框和对应gt框之间的IoU(即gt_IoU)。同时对于centerness score除了用真值替换外,也考虑用gt_IoU进行替换。
结果如表1所示,可以看出原始的FCOS+ATSS得到了39.2的AP,当用真值gt_ctr替换centerness时,AP只提升了2.0。同样,用gt_IoU(gt_ctr_iou)替换centerness得分时只得到了43.5的AP。这表明,无论是用预测的centerness得分和分类得分的乘积,还是IoU得分和分类得分的乘积作为排序的指标都无法带来显著的性能提升。


相比之下,用检测框的真值(gt_bbox)替换即使没有centerness得分(no w/ctr)AP也达到了56.1。但是如果用真值1替换分类预测得分,是否有centerness就变得很重要(43.1 AP vs 58.1 AP),这是因为centerness可以在一定程度上区分准确和不准确的检测框。
最令人惊讶的结果是用gt_IoU(gt_cls_iou)替换分类得分,在没有centerness的情况下,AP达到了74.7,明显高于其它实例。这实际上表明在大量候选框中已经包含了精确定位的检测框,实现高精度检测性能的关键是准确地从大量候选框中挑出高质量的检测框。上述结果表明,用gt IoU替换分类得分是效果最好的方法。作者将这种得分称为IoU-aware Classification Score(IACS)。
方法介绍
基于上述实验结果,作者基于FCOS+ATSS开发了一个新的检测模型VarifocalNet,去掉了centerness分支,相比于传统的FCOS+ATSS,VFNet有三个新的部分:varifocal loss、star-shaped bounding box feature representation、bounding box refinement。
IACS - IoU-Aware Classification Score
分类向量gt位置处的值由1改为预测框和对应gt框之间的IoU,其它位置为0。
Varifocal Loss
作者借鉴了focal loss的加权思想来处理训练时回归连续的IACS时的类别不平衡的问题,和focal loss不同的是,作者以一种非对称的方式对待正负样本,具体如下
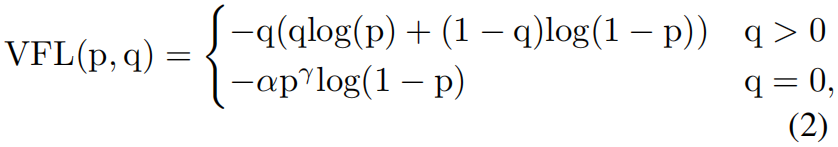
其中 \(p\) 是预测的IACS,\(q\) 是预测值。
从式(2)可以看出,varifocal loss只通过系数 \(p^{\gamma}\) 减少负样本(q=0)的贡献,而没有用同样的方法降低正样本的贡献,这是因为相比于负样本正样本数量非常少因此需要保留它们珍贵的学习信息。另一方面,受PISA的启发,作者用正样本的标签 \(q\) 对正样本进行加权,如果一个正样本的gt_IoU值很大,它对损失的贡献相对也会更大。这迫使模型更关注那些高质量的正样本,从而获得更高的AP。
Star-Shaped Box Feature Representation
作者设计了一个新的星状的检测框特征表示方法,如图(1)中的黄色圆圈所示,它利用可变形卷积使用9个固定点的特征来表示一个检测框。这种新的表示方法可以捕获边界框的几何形状及其附近的上下文信息,这对于编码预测框和gt框之间的偏移是非常重要的。
具体而言,给定特征图上的一个点 \((x,y)\),首先用3x3卷积回归一个初始框。和FCOS一样,这个检测框由一个4维向量 \((l',t',r',b')\) 编码,分别表示从这个点到检测框左边、上边、右边、下边的距离。利用这个距离向量,我们可以选择9个采样点:(x, y), (x-l', y), (x, y-t'), (x+r', y), (x, y+b'), (x-l', y-t'), (x+l', y-t'), (x-l', y+b'), (x+r', y+b'),然后将它们映射到特征图上。它们相对于点 \((x,y)\) 的偏移作为可变形卷积的偏移,然后对这9个点上的特征通过可变形卷积来表示一个检测框。
Bounding Box Refinement
作者进一步通过检测框的一个精调refinement步骤来提高定位精度,检测框精调在cascade r-cnn和single-shot refinement中用到过,但由于缺乏有效的object descriptor在密集目标检测模型中很少使用,但有了本文提出的星状表示方法,就可以在dense目标检测模型中高效的使用了。
作者将检测框的精调建模为一个残差学习问题,对于一个初始回归的检测框 \((l',t',r',b')\),首先提取star-shaped表示来进行编码。然后基于这种表示,再学习四个距离缩放因子 \((\triangle l,\bigtriangleup t,\bigtriangleup r,\bigtriangleup b)\) 来缩放初始的距离向量,最终精调的检测框可以表示为 \((l,t,r,b)=(\triangle l\times l',\triangle t\times t',\triangle r\times r',\triangle b\times b')\)。
VarifocalNet
将上述三部分添加到FCOS中并去掉centerness分支,就得到了本文提出的VarifocalNet。

VFNet的完整结构如图3所示,VFNet的骨干backbone网络和FPN网络和FCOS相同,区别在于head部分。VFNet的head部分包含两个子网络subnetworks,定位子网络执行边界框的回归以及随后的精调,它以FPN每个level的输出特征图作为输入,首先进行3个带有ReLu激活的3x3卷积,得到通道为256的feature map。然后定位子网络的一个分支再次进行卷积,然后在每个空间位置得到一个4维的距离向量 \((l',t',r',b')\) 表示初始检测框。根据这个初始检测框和3个3x3卷积的输出特征图,定位子网络的另一个分支对星状的9个采样点进行可变形卷积,得到距离缩放因子向量 \((\triangle l,\triangle t,\triangle r,\triangle b)\) ,然后与初始距离向量相乘就得到精调的检测框 \((l,t,r,b)\)。
另一个子网络用于预测IACS,它的结构和定位子网络相似除了它的输出向量长度为 \(C\) (类别数),其中每个元素是目标存在置信度和定位精度的联合表示。
Loss Function and Inference
VFNet的损失函数如下所示

其中 \(p_{c,i}\) 和 \(q_{c,i}\) 分别是FPN每层特征图上位置 \(i\) 处类别 \(c\) 的预测和真值IACS,\(L_{bbox}\) 是GIoU损失,\(bbox_{i}',bbox_{i},bbox_{i}^{*}\) 分别是初始、精调、gt检测框。作者用训练目标 \(q_{c^{*},i}\) 加权 \(L_{bbox}\),前景是gt_IoU背景是0。\(\lambda_{0}\) 和 \(\lambda_{1}\) 是权重系数在本文分别设置为1.5和2.0。\(N_{pos}\) 是前景点的总数。
实验结果
作者首先通过实验确定varifocal loss的两个超参 \(\alpha, \gamma\) 的值,结果如下。可以看到,当 \(\alpha=0.75,\gamma=2\) 时精度最高。
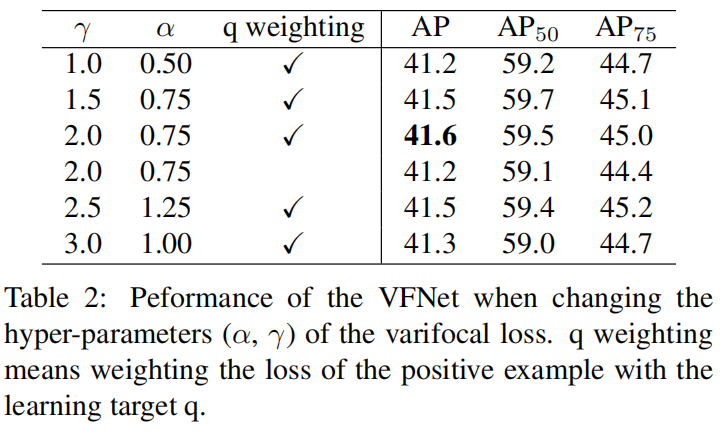
然后研究了每个组件的贡献,结果如下。可以看出三个部分都对性能的提升有贡献,且组合一起使用性能最高。

最后,和其它sota方法的对比如下,可以看出,在相同的配置下(backbone、是否用DCN、mstrain等)VFNet都获得了最高的精度。

代码解析
这里以mmdetection中的实现为例讲解一下实现细节,这里输入input_shape=(2, 3, 300, 300),backbone='resnet-50',经过FPN后P3~P7的输出大小为[(2,256,38,38),(2,256,19,19),(2,256,10,10),(2,256,5,5),(2,256,3,3)],VFNet的创新部分都在head中,如图3所示。以P3的输出为例,head部分的完整实现代码如下
def forward_single(self, x, scale, scale_refine, stride, reg_denom):
"""Forward features of a single scale level.
Args:
x (Tensor): FPN feature maps of the specified stride.
scale (:obj: `mmcv.cnn.Scale`): Learnable scale module to resize
the bbox prediction.
scale_refine (:obj: `mmcv.cnn.Scale`): Learnable scale module to
resize the refined bbox prediction.
stride (int): The corresponding stride for feature maps,
used to normalize the bbox prediction when
bbox_norm_type = 'stride'.
reg_denom (int): The corresponding regression range for feature
maps, only used to normalize the bbox prediction when
bbox_norm_type = 'reg_denom'.
Returns:
tuple: iou-aware cls scores for each box, bbox predictions and
refined bbox predictions of input feature maps.
"""
cls_feat = x # (2,256,38,38)
reg_feat = x
for cls_layer in self.cls_convs: # 3个3x3 conv
cls_feat = cls_layer(cls_feat)
# (2,256,38,38)
for reg_layer in self.reg_convs: # 3个3x3 conv
reg_feat = reg_layer(reg_feat)
# (2,256,38,38)
# predict the bbox_pred of different level
reg_feat_init = self.vfnet_reg_conv(reg_feat) # 3x3conv, (2,256,38,38)
if self.bbox_norm_type == 'reg_denom':
bbox_pred = scale(
self.vfnet_reg(reg_feat_init)).float().exp() * reg_denom # 3x3conv, 64, (2,4,38,38)
elif self.bbox_norm_type == 'stride':
bbox_pred = scale(
self.vfnet_reg(reg_feat_init)).float().exp() * stride
else:
raise NotImplementedError
# compute star deformable convolution offsets
# converting dcn_offset to reg_feat.dtype thus VFNet can be
# trained with FP16
dcn_offset = self.star_dcn_offset(bbox_pred, self.gradient_mul,
stride).to(reg_feat.dtype) # _, 0.1, 8, (2,18,38,38)
# refine the bbox_pred
reg_feat = self.relu(self.vfnet_reg_refine_dconv(reg_feat, dcn_offset)) # (2,256,38,38)
bbox_pred_refine = scale_refine(
self.vfnet_reg_refine(reg_feat)).float().exp() # (2,4,38,38)
bbox_pred_refine = bbox_pred_refine * bbox_pred.detach() # (2,4,38,38)
# predict the iou-aware cls score
cls_feat = self.relu(self.vfnet_cls_dconv(cls_feat, dcn_offset)) # (2,256,38,38)
cls_score = self.vfnet_cls(cls_feat) # (2,20,38,38)
if self.training:
return cls_score, bbox_pred, bbox_pred_refine
else:
return cls_score, bbox_pred_refine
首先分类和回归子网络一开始都是连续3个3x3卷积,即代码中的self.cls_convs和self.reg_convs。回归子网络下面的分支再经过一个3x3卷积self.vfnet_reg_conv之后再经过偏差预测3x3卷积self.vfnet_reg得到初始的边界框预测结果bbox_pred,即图3中间的橘色特征图,shape=(2, 4, 38, 38)。这里预测的是每个点到对应预测框四条边的距离,然后按照图1根据这个点的坐标以及到四边的距离得到star-shape representation的9个点,通过函数self.star_dcn_offset实现,代码如下。
def star_dcn_offset(self, bbox_pred, gradient_mul, stride):
"""Compute the star deformable conv offsets.
Args:
bbox_pred (Tensor): Predicted bbox distance offsets (l, r, t, b). 这里应该是(l,t,r,b)
gradient_mul (float): Gradient multiplier.
stride (int): The corresponding stride for feature maps,
used to project the bbox onto the feature map.
Returns:
dcn_offsets (Tensor): The offsets for deformable convolution.
"""
dcn_base_offset = self.dcn_base_offset.type_as(bbox_pred)
bbox_pred_grad_mul = (1 - gradient_mul) * bbox_pred.detach() + \
gradient_mul * bbox_pred
# detach() 截断梯度
# map to the feature map scale
bbox_pred_grad_mul = bbox_pred_grad_mul / stride # (2,4,38,38)
N, C, H, W = bbox_pred.size()
x1 = bbox_pred_grad_mul[:, 0, :, :] # (2,38,38)
y1 = bbox_pred_grad_mul[:, 1, :, :]
x2 = bbox_pred_grad_mul[:, 2, :, :]
y2 = bbox_pred_grad_mul[:, 3, :, :]
bbox_pred_grad_mul_offset = bbox_pred.new_zeros(
N, 2 * self.num_dconv_points, H, W)
# 顺序为第一行从左到右、第二行从左到右、第三行从左到右。并且每个点先y坐标后x坐标
bbox_pred_grad_mul_offset[:, 0, :, :] = -1.0 * y1 # -y1
bbox_pred_grad_mul_offset[:, 1, :, :] = -1.0 * x1 # -x1
bbox_pred_grad_mul_offset[:, 2, :, :] = -1.0 * y1 # -y1
bbox_pred_grad_mul_offset[:, 4, :, :] = -1.0 * y1 # -y1
bbox_pred_grad_mul_offset[:, 5, :, :] = x2 # x2
bbox_pred_grad_mul_offset[:, 7, :, :] = -1.0 * x1 # -x1
bbox_pred_grad_mul_offset[:, 11, :, :] = x2 # x2
bbox_pred_grad_mul_offset[:, 12, :, :] = y2 # y2
bbox_pred_grad_mul_offset[:, 13, :, :] = -1.0 * x1 # -x1
bbox_pred_grad_mul_offset[:, 14, :, :] = y2 # y2
bbox_pred_grad_mul_offset[:, 16, :, :] = y2 # y2
bbox_pred_grad_mul_offset[:, 17, :, :] = x2 # x2
dcn_offset = bbox_pred_grad_mul_offset - dcn_base_offset
return dcn_offset
然后通过可变形卷积self.vfnet_reg_refine_dconv得到refine后的回归特征,再经过一个3x3卷积self.vfnet_reg_refine得到偏差的refine向量bbox_pred_refine,即上文提到的 \((\triangle l,\triangle t,\triangle r,\triangle b)\),然后与初始的bbox_pred相乘完成box refinement,得到了最终的偏差预测值。
分类子网络和回归子网络相似,不再细说。
最后是varifocal loss的实现,代码如下
def varifocal_loss(pred,
target,
weight=None,
alpha=0.75,
gamma=2.0,
iou_weighted=True,
reduction='mean',
avg_factor=None):
"""`Varifocal Loss <https://arxiv.org/abs/2008.13367>`_
Args:
pred (torch.Tensor): The prediction with shape (N, C), C is the
number of classes
target (torch.Tensor): The learning target of the iou-aware
classification score with shape (N, C), C is the number of classes.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
alpha (float, optional): A balance factor for the negative part of
Varifocal Loss, which is different from the alpha of Focal Loss.
Defaults to 0.75.
gamma (float, optional): The gamma for calculating the modulating
factor. Defaults to 2.0.
iou_weighted (bool, optional): Whether to weight the loss of the
positive example with the iou target. Defaults to True.
reduction (str, optional): The method used to reduce the loss into
a scalar. Defaults to 'mean'. Options are "none", "mean" and
"sum".
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
"""
# pred and target should be of the same size
assert pred.size() == target.size()
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
if iou_weighted:
focal_weight = target * (target > 0.0).float() + \
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
(target <= 0.0).float()
else:
focal_weight = (target > 0.0).float() + \
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
(target <= 0.0).float()
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weight
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss
其中iou_weighted=True,其中的target就是预测框和对应gt之间的IoU值。