原文链接:https://arxiv.org/abs/2205.07246
代码链接:https://github.com/microsoft/Semi-supervised-learning 作者视频讲解链接:https://www.bilibili.com/video/BV14L411k7De/?spm_id_from=333.999.0.0&vd_source=90e27a3caa4ef021dcfe32a4f91dd316
相关讲解文章:
(1)https://www.163.com/dy/article/HUQFU9B20511CQLG.html
(2)https://zhuanlan.zhihu.com/p/592850395
【作者视频讲解的笔记】:
半监督学习的背景
半监督学习:在少量样本标签的引导下,能够充分利用大量无标签样本提高学习性能,避免了数据资源的浪费,同时解决了有标签样本较少时监督学习方法泛化能力不强和缺少样本标签引导时无监督学习方法不准确的问题。
定义:

图:SSL的目标是使用少量标记数据和大量未标记数据进行学习。
大量的标记数据通常是费力和昂贵的获取。为了减轻对标记数据的依赖,开发了半监督学习(SSL),通过利用大量无标记数据来提高模型的泛化性能。
范式:
关键是模型应该在不同扰动下对相同的未标记数据产生相似的预测或相同的伪标签。
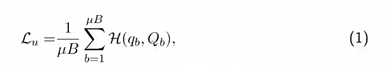

当模型的输入是同一张照片(文本、音频)的两种不同的增强方式(数据增强或模型增强)模型应该输出相同的概率
基线
(1)FixMatch(NeurIPS 2020):
如何安全地利用可能给训练带来大量噪音的未标记数据?包括FixMatch在内的阈值方法可以过滤不自信的未标记数据使用固定的(预定义的)高阈值可以减轻噪声。
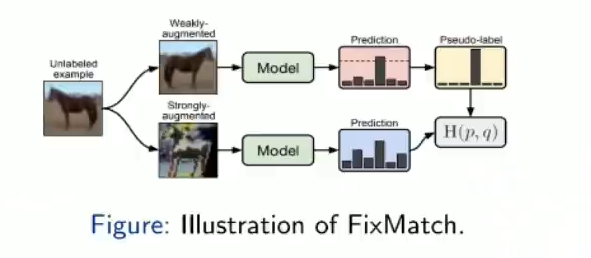
引入了弱增强和强增强,用强增强对弱增强进行学习,因为弱增强的数据输出一般比较稳定,强增强一般会有比较大的振动,让强增强向弱增强靠近
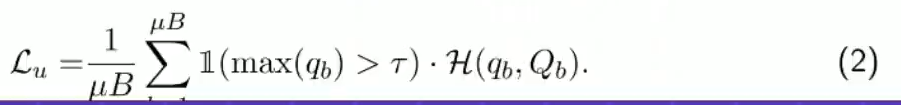
(2)Dash(ICML 2021)
Dash:逐渐增加固定的(预定义的)全局(特定于数据集的)阈值。


不同于其中fixmatch用于一个预定义的固定阈值,在训练过程中缓慢的增长这个阈值,(文章中较多的理论性证明,证明其收敛性和idea的有效性,每个类的不同阈值)
(3)FlexMatch(NeurIPS 2021)也是本篇作者的文章
FlexMatch :将固定的(预定义的)全局(特定于数据集的)阈值映射到根据学习效果不同的局部(特定于类别)阈值。
之前的算法是将一个固定的阈值给所有的数据去过滤,观察到每个类的学习难度不一样,那些难学习的类需要调低阈值,易学习的类调高阈值,使得学习更加的平衡
观察到当前的类超过预定义的阈值,如果有很多超过预定义阈值则很好学,通过数量进行mapping match得出每个类有不同的阈值

问题和挑战:
问题:现有的方法可能无法采用合适的阈值,因为它们要么使用预定义/固定阈值或特别阈值调整方案。
挑战:
(1):是否需要根据模型的学习状态来确定阈值?
(2):如何自适应地调整阈值以获得最佳的培训效率?
提议方法:FreeMatch
理论分析:
将介绍一个二进制分类示例来激励阈值调整方案,尽管简化了实际模型和训练过程,但分析导致了一些有趣的含义,并提供了关于如何设置阈值的见解。
目的是证明自适应性和增加的粒度在SSL的置信阈值的必要性



存在全局阈值,随着训练的增加全局阈值会随着置信度增加而增加的,每个类都有自己的动态变化的;实现阈值定义的自动化(不需要预定义阈值)
公式:

为了克服伪标签的不平衡性,引入自适应公平性


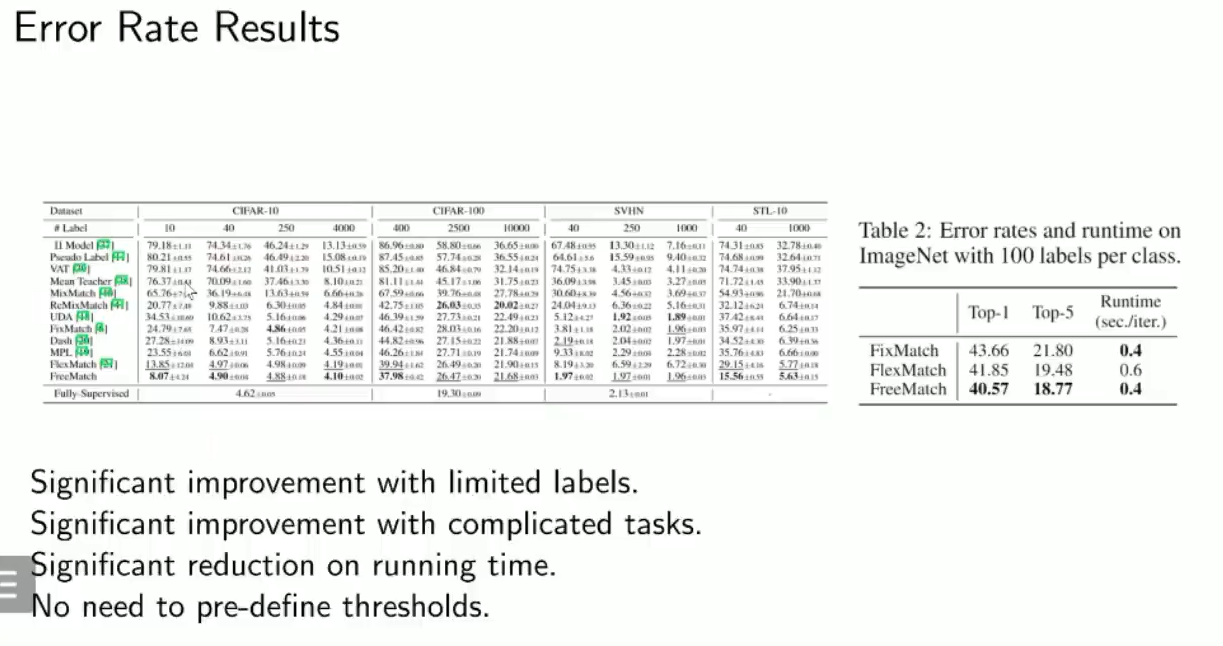
实验:FreeMatch