Code:https://github.com/CameronDiao/relational-transformer
动机
标准的Transformer缺少relational indective biases,而这在GNN中是非常常见的。
Transformer的归纳偏置非常弱,几乎于没有,这允许entity携带像位置这样的领域具体属性,以被编码作为被应用于不同域的transformer架构的输入。这允许了Transformer目前在很多领域都取得了卓越的成果,但大部分领域的Transformer都成功在array-structured的数据,比如文本或图像。相比之下,图数据主要关注实体之间的pair-wise关系,用边和边属性表示。要知道,graphs比sets更普遍,且更具表现力,sets是graphs的特殊情况:一个没有边的图。也就是说,Transformer并没有以保存关系信息的的方式处理图数据。
因此,这篇文章要解决的事情就是将相关信息引入Transformer,以处理图结构任务。最近其实有一些Graph Transformer的文章,但是在这篇文章内,相比于他们,作者提出了一种数学上优雅的Transormer attention的扩展——relational attention,它将edge vectors作为一级模型组件。
Relational Transformer
首先,本文将输入的图定义为一个有向图G=(N, V),并采用 graph-to-graph 模式进行建模。即每一层的输入是一个图,输出也是一个图。graph-to-graph model的每一层由以下公式定义:
 其中,一个聚合函数 ⊕ \oplus ⊕和一个消息函数 ψ m \psi^m ψm,以及包含了两个更新函数 ϕ \phi ϕ ,分别用来更新节点和边向量。
其中,一个聚合函数 ⊕ \oplus ⊕和一个消息函数 ψ m \psi^m ψm,以及包含了两个更新函数 ϕ \phi ϕ ,分别用来更新节点和边向量。
消息函数可以获得出发节点和目标节点的特征信息,描述了需要发给目标节点做下一步计算的信息。消息函数将所有邻居节点的消息沿着对应的边发送到中心节点。相当于单个边上执行的一个算法。
聚合函数将所有发送到在中心节点的信息进行聚合,形成一个聚合后的信息。相当于对所有边执行的一个算法。
更新函数的作用是组合当前时刻节点的表示以及从aggregation function中获得的消息,更新当前时刻的节点表示。
在不同的网络中,区别是上面公式中的函数不同
一般的GNNs中 ϕ e \phi_e ϕe是一个identity 函数,相当于什么操作没有,也就是说下个阶段的边向量等于当前的边向量,也就是不对边做更新。
在GATs中,聚合函数 ⊕ \oplus ⊕是一个自注意力机制,消息函数 ψ m \psi^m ψm只在sender features上做特征的聚合,也就是说在邻居节点是乘以一个权重W。
在Message Passing Neural Networks (MPNN)中, ⊕ \oplus ⊕是一个最大池化操作。
如果想在Transformer的基础上做一个数学优雅的扩展,来将edge vectors整合为一级模型组件,那么需要满足一下设计准则:
- 保留Transformer的原始机制;
- 引入有向边向量表征实体间的关系;
- Condition transformer attention on the edge vectors;
- 扩展Transformer的层来consume edge vectors并更新它们;
- 保留Transformer 的 O ( N 2 ) O(N^2) O(N2)计算复杂度
1)Relational Attention
Relational Transformer的核心创新如下,就是condition QKV vectors on 节点间的有向边 e i j e_{ij} eij.

具体的操作是通过在线性变换之前将该edge vector与每个节点向量连接起来,如下:

这里面的W的尺寸是: ( d n + d e ) × d n (d_n+d_e)\times d_n (dn+de)×dn。 d n d_n dn和 d e d_e de分别是节点向量和边向量的尺寸。进一步地,为了有效而准确地实现这一点,作者将每个权值矩阵W分成两个单独的矩阵,分别用来投影节点和边向量,如下所示, W n , W e W_n, W_e Wn,We的尺寸分别为 d n × d n d_n\times d_n dn×dn和 d e × d n d_e\times d_n de×dn。

其实就是将边向量经过一个映射,转换为三种embedding,分别加到qkv上,再进行attention机制。
这个操作有些类似于用“相对关系”对qkv分别做一个position embedding,只不过这个position embedding是有向的,即不同的q对不同的kv,“相对关系”是不一样的。传统的position embedding和这里采用的都是是相加操作。这样做了以后,就实现了最初的设计理念,即:保留了Transformer的架构,引入entities之间的relative relation,并condition Transformer on these relations,还保存了Transformer的 O ( N 2 ) O(N^2) O(N2)计算复杂度。
2) 边更新
一个N个节点的图中,有N*N个边,如果更新每一条边时都attend这N个节点,那么计算复杂度将会变成 O ( N 3 ) O(N^3) O(N3),因此作者只从每条边的直接区域(相连的两个节点、本身和反向边)中聚合信息,来更新这条边。这样做感觉确实很合理,因为下个阶段两个节点的边只与这两个节点、和上个阶段的边有关。总的边更新函数如下:

中间的细节是,首先拼接这四个向量,经过一个线性层和ReLU函数,获取到聚合的信息:
![]()
有了聚合的信息后,再对上阶段的 e i j l e^l_{ij} eijl进行更新如下:
![]()
先前工作
按照 边向量合并方式 和 Transformer机制的保留程度,将之前的工作分类如下。
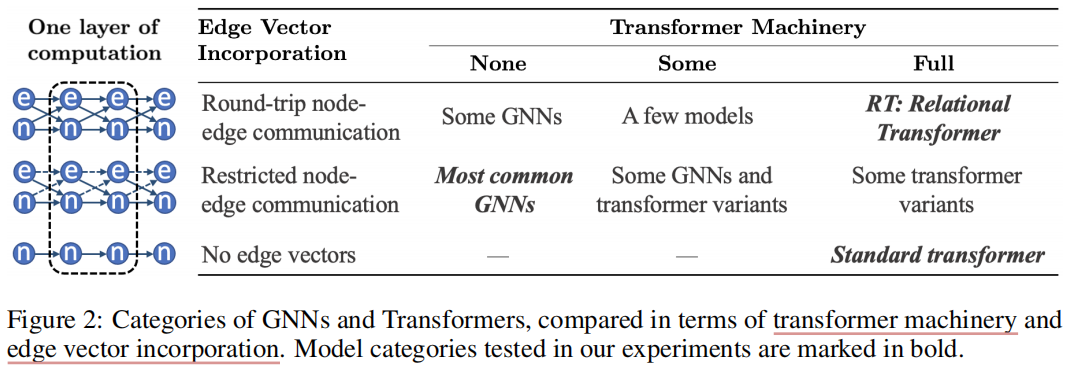
attentional GNNs只计算边向量上的attention,也就是说它们是受邻接矩阵的约束的,并且每一层中,边向量是不更新的。