Bounding-Box Regression边界框回归的学习和理解
欢迎大家系统学习Faster RCNN原理的专题讲座:
Faster RCNN原理篇(二)——RoIPooling和RoIAlign的学习和理解
Faster RCNN原理篇(三)——区域候选网络RPN(Region Proposal Network)的学习、理解
引言
由于Faster RCNN = RPN + Fast RCNN,因此,为了学习和理解Faster RCNN,本人研究了RPN的实现原理,在学习RPN实现原理的过程中,又不可避免地开始深钻Bounding-Box Regression的设计原理和实现过程。最后,发现常见的目标检测算法如R-CNN、Fast RCNN中都用到了 Bounding-Box Regression,回归的目标是使得 预测的物体窗口Region Proposal 和 真实的物体窗口Ground Truth更加接近。
(备注: 关于Faster RCNN原理篇所涉及的各个知识点,本人会分章节进行学习和总结,并无偿分享给大家,以求共同学习进步~如有不足之处,还望批评指定,一起进步!!!)
话不多说,直接步入正题:
Bounding-Box Regression的学习和理解,可以围绕以下5个问题的解答进行详细展开:
- (Why?)为何要做边框回归?
- (What?)什么是边框回归?
- (How?)如何实现边框回归?
- 边框回归为什么使用相对坐标差?
- 为什么边框回归只能微调,且只有距离Ground Truth较近的时候才能生效?
1. (Why?)为何要做边框回归?

如上图所示,绿色的框代表实际飞机的Ground Truth,红色的框代表算法提取的Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5),那么这张图相当于没有正确的检测出飞机。如果我们能对红色的框进行微调,使得经过微调后的窗口跟Ground Truth更接近,这样岂不是定位会更准确。确实,Bounding-box regression 就是用来微调这个窗口的。
一句话总结:Bounding-box regression 是用来对算法提取的预测框Region Proposal进行微调,使其更加接近于物体的真实标注框Ground Truth。
参考链接:
人脸检测中的bounding box regression详解
2. (What?)什么是边框回归?
对于窗口一般使用四维向量 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽、高。 如下图所示:红色的框 P P P 代表原始的Region Proposal ,绿色的框 G G G 代表真实的Ground Truth, 我们的目标是寻找一种关系使得输入的原始窗口 P P P 经过映射得到一个跟真实窗口 G G G 更接近的回归窗口 G ^ Ĝ G^ 。
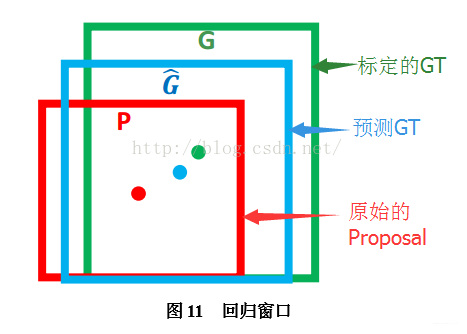
边框回归的目的: 给 定 ( P x , P y , P w , P h ) , 寻 找 一 种 映 射 f , 使 得 f ( P x , P y , P w , P h ) = ( G x ^ , G y ^ , G w ^ , G h ^ ) ≈ ( G x , G y , G w , G h ) 给定(P_x,P_y,P_w,P_h),寻找一种映射f, 使得f(P_x,P_y,P_w,P_h)=(\widehat{G_x},\widehat{G_y},\widehat{G_w},\widehat{G_h})≈(G_x,G_y,G_w,G_h) 给定(Px,Py,Pw,Ph),寻找一种映射f,使得f(Px,Py,Pw,Ph)=(Gx
,Gy
,Gw
,Gh
)≈(Gx,Gy,Gw,Gh)
3. (How?)如何实现边框回归?
那么经过何种变换才能从图11中的窗口 P P P 变为窗口 G ^ Ĝ G^ 呢? 比较简单的思路就是: 位置平移+尺度放缩。具体过程如下:
-
位置平移 :首先做平移 ( Δ x , Δ y ) , Δ x = P w d x ( P ) , Δ y = P h d y ( P ) (Δx,Δy), Δx=P_wd_x(P),Δy=P_hd_y(P) (Δx,Δy),Δx=Pwdx(P),Δy=Phdy(P)这是R-CNN论文《Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)》的公式(1)、(2):
G ^ x = P w d x ( P ) + P x (1) \begin{aligned} &Ĝ_x=P_wd_x(P)+P_x\tag{1} \end{aligned} G^x=Pwdx(P)+Px(1)
G ^ y = P h d y ( P ) + P y (2) \begin{aligned} &Ĝ_y=P_hd_y(P)+P_y\tag{2} \end{aligned} G^y=Phdy(P)+Py(2) -
尺寸缩放 :然后做尺度缩放 ( S w , S h ) , S w = e x p ( d w ( P ) ) , S h = e x p ( d h ( P ) ) (S_w,S_h), S_w=exp(d_w(P)),S_h=exp(d_h(P)) (Sw,Sh),Sw=exp(dw(P)),Sh=exp(dh(P)), 对应论文中的公式(3)、(4):
G ^ w = P w e x p ( d w ( P ) ) (3) \begin{aligned} &Ĝ_w=P_wexp(d_w(P))\tag{3} \end{aligned} G^w=Pwexp(dw(P))(3)
G ^ h = P h e x p ( d h ( P ) ) (3) \begin{aligned} &Ĝ_h=P_hexp(d_h(P))\tag{3} \end{aligned} G^h=Phexp(dh(P))(3)
观察(1)-(4)我们发现, 边框回归学习的就是 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P), d_y(P), d_w(P), d_h(P) dx(P),dy(P),dw(P),dh(P)这四个变换。 下一步就是如何设计算法得到这四个映射。
当输入的Region Proposal 与 Ground Truth 相差较小时(RCNN设置是IOU>0.6),可以认为这种变换是一种线性变换,那么我们就可以使用线性回归来建模对窗口进行微调。
注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这个也是G-CNN: an Iterative Grid Based Object Detector多次迭代实现目标准确定位的关键。
线性回归 就是给定输入的特征向量 X X X, 学习一组参数 W W W, 使得经过线性回归后的值跟真实值 Y ( G r o u n d T r u t h ) Y(Ground \quad Truth) Y(GroundTruth)非常接近。即: Y ≈ W X Y≈WX Y≈WX 。 那么,Bounding-box 中我们的输入以及输出分别是什么呢?
- Input: R e g i o n P r o p o s a l → P = ( P x , P y , P w , P h ) Region \quad Proposal→P=(P_x, P_y, P_w, P_h) RegionProposal→P=(Px,Py,Pw,Ph)
输入就是这四个数值吗?其实 真正的输入是这个窗口对应的 CNN 特征,也就是 R-CNN 中的 Pool5 feature(特征向量)。 (注:训练阶段输入还包括 Ground Truth, 也就是下边提到的 t ∗ = ( t x , t y , t w , t h ) ) t_∗=(t_x, t_y, t_w, t_h)) t∗=(tx,ty,tw,th))
- Output: 需要进行的平移变换和尺度缩放 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P),d_y(P),d_w(P),d_h(P) dx(P),dy(P),dw(P),dh(P), 或者说是 Δ x , Δ y , S w , S h Δx, Δy, S_w, S_h Δx,Δy,Sw,Sh。
我们的最终输出不应该是 Ground Truth 吗? 是的, 但是有了这四个变换我们就可以直接得到 Ground Truth。这里还有个问题, 根据公式(1)~(4)我们可以知道, 原始输入 P P P 经过 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P), d_y(P), d_w(P), d_h(P) dx(P),dy(P),dw(P),dh(P)得到的并不是真实值 G G G, 而是预测值 G ^ Ĝ G^ 。 的确, 这四个值应该是经过 Ground Truth 和 Proposal 计算得到的真正需要的平移量 ( t x , t y ) (t_x, t_y) (tx,ty) 和尺度缩放 ( t w , t h ) (t_w, t_h) (tw,th)。
这也就是R-CNN论文《Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)》的公式(6)~(9):
t x = ( G x − P x ) / P w (6) \begin{aligned} t_x=(G_x−P_x)/P_w\tag{6} \end{aligned} tx=(Gx−Px)/Pw(6)
t y = ( G y − P y ) / P h (7) \begin{aligned} t_y=(G_y−P_y)/P_h\tag{7} \end{aligned} ty=(Gy−Py)/Ph(7)
t w = l o g ( G w / P w ) (8) \begin{aligned} t_w=log(G_w/P_w)\tag{8} \end{aligned} tw=log(Gw/Pw)(8)
t h = l o g ( G h / P h ) (9) \begin{aligned} t_h=log(G_h/P_h)\tag{9} \end{aligned} th=log(Gh/Ph)(9)
那么目标函数可以表示为 d ∗ ( P ) = w ∗ T Φ 5 ( P ) d_∗(P)=\mathbf{w}^T_∗\mathbf{Φ}_5(P) d∗(P)=w∗TΦ5(P), Φ 5 ( P ) \mathbf{Φ}_5(P) Φ5(P)是输入 Proposal 的特征向量, w ∗ \mathbf{w}_∗ w∗是要学习的参数( ∗ * ∗ 表示 x , y , w , h x,y,w,h x,y,w,h, 也就是每一个变换对应一个目标函数) , d ∗ ( P ) d_∗(P) d∗(P) 是得到的预测值。 我们要让预测值跟真实值 t ∗ = ( t x , t y , t w , t h ) t_∗=(t_x, t_y, t_w, t_h) t∗=(tx,ty,tw,th)差距最小, 得到损失函数为:
L o s s = ∑ i N ( t ∗ i − w ^ ∗ T ϕ 5 ( P i ) ) 2 \begin{aligned} Loss=∑_i^N(t^i_∗−ŵ ^T_∗ϕ_5(P^i))^2 \end{aligned} Loss=i∑N(t∗i−w^∗Tϕ5(Pi))2
函数优化目标为:
w ∗ = a r g m i n w ^ ∗ ∑ i N ( t ∗ i − w ^ ∗ T Φ 5 ( P i ) ) 2 + λ ∣ ∣ w ^ ∗ ∣ ∣ 2 \mathbf{w}_∗=argmin_{\mathbf{ŵ}_∗}^{}∑_i^N(t^i_∗−\mathbf{ŵ}^T_{∗}\mathbf{Φ}_5(P^i))^2+λ||\mathbf{ŵ} _∗||^2 w∗=argminw^∗i∑N(t∗i−w^∗TΦ5(Pi))2+λ∣∣w^∗∣∣2
利用梯度下降法或者最小二乘法就可以得到 w ∗ \mathbf{w}_∗ w∗。
4. 边框回归为什么使用相对坐标差?
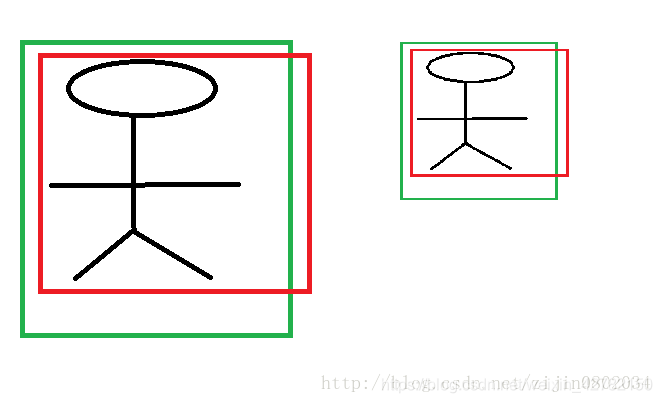
CNN具有尺度不变性, 以下图为例:
- x , y x,y x,y 坐标除以宽、高的原因:
进行尺度归一化,解决输入图像的尺寸大小不等的问题。 如:上图中两个人的尺度不同,但他都是人。所以,根据CNN具有尺度不变性,可知:我们得到的特征相同。
反证法证明:
我们假设经过CNN提取得到的特征分别为 ϕ 1 , ϕ 2 ϕ_1, ϕ_2 ϕ1,ϕ2,同时,我们假设 x i x_{i} xi为第 i i i 个真实目标框的 x x x 坐标, p i p_{i} pi为第 i i i 个候选目标框的 x x x 坐标,边界框回归的映射关系为 f f f。那么我们可以得出:
{ f ( ϕ 1 ) = x 1 − p 1 f ( ϕ 2 ) = x 2 − p 2 (1) \begin{cases} f(ϕ_1)=x_1-p_1\\[2ex] f(ϕ_2)=x_2-p_2 \end{cases} \tag{1} ⎩⎨⎧f(ϕ1)=x1−p1f(ϕ2)=x2−p2(1)
由于CNN具有尺度不变性,因此满足 ϕ 1 = ϕ 2 ϕ_1=ϕ_2 ϕ1=ϕ2。
如果我们直接学习坐标差值,以 x x x坐标为例,假设 x i , p i x_i,p_i xi,pi 分别代表第 i i i 个框的 x x x 坐标,学习到的映射为 f f f, 则 f ( ϕ 1 ) = x 1 − p 1 f(ϕ_1)=x_1−p_1 f(ϕ1)=x1−p1,同理 f ( ϕ 2 ) = x 2 − p 2 f(ϕ_2)=x_2−p_2 f(ϕ2)=x2−p2。显然, x 1 − p 1 ≠ x 2 − p 1 x_1−p_1≠x_2−p_1 x1−p1=x2−p1,那么理论上也应满足 x 1 − p 1 = x 2 − p 2 x_1 − p_1 = x_2 − p_2 x1−p1=x2−p2 。
但是,观察上图,可知 x 1 − p 1 ≠ x 2 − p 2 x _1 − p_1 ≠ x_2 − p_2 x1−p1=x2−p2,显然由于输入图像尺寸的变化,候选目标框和真实目标框坐标之间的偏移量也随之成比例缩放,但是,进行归一化之后,其比例值是恒定不变的。所以,我们必须对 x x x 坐标的偏移量除以候选目标框的宽, y y y 坐标的偏移量除以候选目标框的高。
只有这样才能得到候选目标框与真实目标框之间坐标偏移量值的相对值。
使用相对偏移量的好处:
可以自由选择输入图像的尺寸,使得模型灵活多变。也就说,对坐标偏移量除以宽、高就是在做尺度归一化,即尺寸较大的目标框的坐标偏移量较大,尺寸较小的目标框的坐标偏移量较小。
参考链接:【R-CNN目标检测系列】二、边界框回归(Bounding-Box Regression)
- 宽、高坐标使用Log形式的原因:
保证缩放尺度的非负性。 要得到一个放缩的尺度,这里必须限制尺度大于0。那么,我们学习的 t w , t h t_w, t_h tw,th 怎么保证满足大于 0 0 0 呢?最直观的想法就是引入EXP函数,如公式(3), (4)所示,那么反过来推导就是Log函数的来源了。 - 为什么IoU较大时,可以认为是线性变换?
当输入的 Proposal 与 Ground Truth 相差较小时(RCNN 设置的是 IoU>0.6), 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归来建模对窗口进行微调, 否则会导致训练的回归模型不 work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。
解释如下:
Log函数明显不满足线性函数,但是为什么当Proposal 和Ground Truth相差较小的时候,就可以认为是一种线性变换呢?原理如下:
l i m x = 0 + ∞ l o g ( 1 + x ) x = 1 \begin{aligned} lim_{x=0}^{+∞}\frac{log(1+x)}{x} =1 \end{aligned} limx=0+∞xlog(1+x)=1将公式(8)、(9)进行变形可得:
{ t w = l o g G w P w = l o g G w + P w − P w P w = l o g ( 1 + G w − P w P w ) t h = l o g G h P h = l o g G h + P h − P h P h = l o g ( 1 + G h − P h P h ) \left\{ \begin{array}{c} t_w=log\frac{G_w}{P_w}=log\frac{G_w+P_w−P_w}{P_w}=log(1+\frac{G_w−P_w}{P_w}) \\ \quad\\ t_h=log\frac{G_h}{P_h}=log\frac{G_h+P_h−P_h}{P_h}=log(1+\frac{G_h−P_h}{P_h}) \end{array} \right. ⎩⎨⎧tw=logPwGw=logPwGw+Pw−Pw=log(1+PwGw−Pw)th=logPhGh=logPhGh+Ph−Ph=log(1+PhGh−Ph)
因此,当 G w − P w P w \frac{G_w−P_w}{P_w} PwGw−Pw 和 G h − P h P w \frac{G_h−P_h}{P_w} PwGh−Ph趋向于0时,即: G w ≈ P w G_w ≈ P_w Gw≈Pw和 G h ≈ P h G_h ≈ P_h Gh≈Ph时,可以近似将对数变换看成线性变换,也就是 宽度和高度必须近似相等。有的博主认为:对于IoU大于指定值这块,我并不认同作者的说法。我个人理解,只保证Region Proposal和Ground Truth的宽高相差不多就能满足回归条件。x,y位置到没有太多限制,这点我们从YOLOv2可以看出,原始的边框回归其实x,y的位置相对来说对很大的。这也是YOLOv2的改进地方。(本人暂时不做评价,仅做记录,后续更新知识库)
按照RCNN论文的说法,IoU大于0.6时,边界框回归可视为线型变换。
参考链接:
边框回归(Bounding Box Regression)详解
【R-CNN目标检测系列】二、边界框回归(Bounding-Box Regression)
赠人玫瑰,手留余香!!!您的点赞和关注是对良心原创者最大的鼓励和支持~