精确物体检测的不确定边界框回归——KL损失(解读)(源论文)
损失模型

KL损失的网络架构用于评估本地化信心。与两级检测网络的标准Fast R-CNN头不同,我们的网络计算标准偏差和边界框位置,这在我们的回归损失kl损失中被考虑到。
模型个人理解:
模型的三个分支,分别是:
- Class:是图像的类别
- Box:是预测的框
- Box std:是预测框的四个坐标(左上角和右下角两个点的四个坐标)与真实框之间的标准差,即坐标之间的距离
通过Box std计算得到的KL loss反向修改Box中的坐标点位置和预测框的大小。
KL损失的性能:
提出了一种新的边界框回归损失——KL损失,用于学习边界框回归和定位不确定性。通过学习到的误差,便于我们在进行NMS非极大值抑制时合并相邻的边界框。在MS-COCO上,提出的方法将VGG-16 Faster R-CNN的平均精度(AP)从23.6%提高到29.1%。更重要的是,对于ResNet-50-FPN Mask R-CNN,该方法将AP和AP90 分别提升了为1.8%和6.2%。
传统边界框损失的不足:
然而,传统的边界盒回归损失(即Smooth L1损失)没有考虑到地面真值边界盒的这种偏差。
- 传统的边界框回归损失并未考虑到地面实况边界框的模糊性。
- 此外,当分类分数很高时,边界框回归被认为是准确的,但并非总是如此。

如图:
- 左边图像,两个候选框都是不准确的。大的太大,小的太小。
- 右边图像,具有较高分类分数的边界框的左边界是不准确的。 (颜色更容易观察)
KL损失组成和好处:
首先将边界框预测和地面实际边界框分别建模为高斯分布和狄拉克δ函数。
然后,新的边界框回归损失被定义为预测分布和地面实际分布的KL差异。
使用KL损失有三大好处:
- 可以成功捕获数据集中的模糊。边界框回归器从模糊的边界框中获得较小的损失。
- 在后处理过程中,所学的方差是有用的。提出了VaR投票(方差投票)方法,即在非最大抑制(NMS)过程中,利用相邻位置的预测方差加权,对候选框的位置进行投票。
- 所学概率分布反映了边界框预测的不确定性水平
使用KL损失,模型可以在训练期间根据方差自适应地调整每个对象边界,这有助于学习更多的判别特征。从概率的角度来学习局部化方差,能够分别学习预测边界框的四个坐标的方差,而不是只学习IOU。var表决根据KL loss学习到的相邻边界框的方差来确定选定框的新位置,它可以与soft-NMS一起工作。
非极大值抑制(Non-Maximum Suppression,NMS)
两级检测器生成杂乱的对象提案,导致大量重复的边界框。然而,在标准的NMS过程中,分类分数较低的边界框将被丢弃,即使它们的位置是准确的。在定位置信度的基础上使用相邻的盒子进行方差投票,这样可以更好的对选出来的框进行定位。
- soft-NMS[1]不是消除所有较低得分的周围边界框,而是将所有其他邻居的检测得分衰减为与较高得分边界框重叠的连续函数。
- Learning NMS[24]提出学习一种新的神经网络,只使用方框和它们的分类分数来执行NMS。
边界框参数化
(x1,y1,x2,y2)表示预测边界框左上角和右下角的坐标。(x*1,y*1,x*2,y*2)表示真实的边界框左上角和右下角的坐标。(x1a, x2a, y1a, y2a, wa, ha)是通过对所有真实框聚类产生的锚盒(锚边界框)(Fast R-CNN中的)。那么预测边界框和真实边界框分别与锚盒的偏差如下:

同样,不带 * 号的 t 表示预测边框与锚盒的偏差,带 * 号的 t 表示真实边框与锚盒的偏差。
在LS损失中,采用参数化的(x1,y1,x2,y2)坐标,而不是R-CNN中使用的(x,y,w,h)坐标为简单起见,边界框坐标表示为x,因为我们可以独立地优化每个坐标。
(1)在文章中,假设坐标是独立的,为了简单起见,使用了单变量高斯函数。

式中是一组可学习的参数。Xe是估计的边界框位置。标准差σ测量估计的不确定度。当σ→0时,这意味着网络对估计的边界框位置非常有信心。
(2)地面真值边界框也可以表示为高斯分布,σ→0,是Dirac delta函数:

其中xg是地面真实边界框位置。
带KL损失的边界框回归
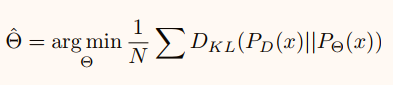
建立![]() ,使
,使![]() 和
和![]() 在N个样本上的KL误差最小化。
在N个样本上的KL误差最小化。
使用kl散度作为边界盒回归的损失函数Lreg。分类损失Lcls保持不变。对于单个样本:


图中,蓝色和灰色的高斯分布是我们的估计。橙色中的dirac delta函数是地面真值边界框的分布。当位置Xe估计不准确时,我们期望网络能够预测更大的方差σ2,从而使Lreg更低(蓝色)。
当位置Xe估计不准确时,我们期望网络能够预测更大的方差σ2,从而使Lreg更低。 不依赖于估计参数θ,因此:
不依赖于估计参数θ,因此:

当σ=1时,kl损失退化为标准欧几里得损失:

损失是可微的位置估计Xe和定位标准偏差σ:

然而,由于σ是分母,有时会在训练开始时梯度爆炸。为了避免梯度爆炸,网络在实际中预测 α=log(σ^2) 而不是 σ 。
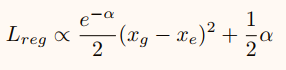
在测试过程中,我们把 α 转换回 σ 。
对于 |xg−xe|>1,我们采用类似于fast R-CNN中定义的Smooth L1 的损失。
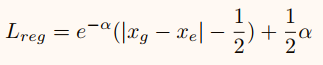
方差投票
在得到预测位置的方差后,根据已知的相邻边界框的方差对候选边界框位置进行投票。如Algorithm1所示,用三行代码更改NMS:

我们对标准NMS(非极大值抑制)或soft-NMS循环中所选框的位置进行投票。选择最大得分b,{x1、y1、x2、y2、s、σx1、σy1、σx2、σy2}四个值soft-NMS的结果四个值的方差,加权以更新box坐标,使得定位更准。在soft-NMS的启发下,我们为更近、底色更低的盒子指定了更高的权重。形式上,设X为坐标(例如X1),Xi 为 ith 盒的坐标。新坐标计算如下:

σt是变量表决的可调参数。当IOU(bi, b)越大,pi越大,即"距离"越近或交并比越大的两个框产生的pi值越大。对剩下的3个坐标值也进行同样的操作。以下两种类型的相邻边界框在投票时会得到较低的权重:(1)方差较大的框。(2)带有所选框的小IOU的框。分类分数不参与投票,因为得分较低的框可能具有较高的信心。在下图中,提供了VaR投票的可视化说明。通过表决,有时可以避免图2中前面提到的导致检测失败的两种情况。

实验
(1)检测模型中每个损失对MS-COCO的贡献。基本模型是vgg-16更快的r-cnn。

(2)推理时间比较

(3)

(4)


(5)

(6)

结论
综上所述,大规模目标检测数据集中的不确定性会阻碍最先进的目标检测设备的性能。分类置信度并不总是与本地化置信度密切相关。本文提出了一种新的具有不确定性的边界盒回归损失方法,用于学习更精确的目标定位。通过训练KL损失,网络学习预测每个坐标的定位方差。由此产生的差异使VaR投票成为可能,它可以通过投票来优化选定的边界框。在MS-COCO和Pascal VOC 2007上,vgg-16 Fast r-cnn、resnet-50 fpn和mask r-cnn得到了令人信服的结果。