自动代码生成:文献阅读和学习
文献名称:《A Deep Learning Model for Source Code Generation 》
作者:Raymond Tiwang,Timothy Oladunni ,Weifeng Xu
PS:博主刚刚接触这个领域,很多内容还不了解,如果博文内容有误,敬请批评指正~
文章目录
摘要:受到n-gram等模型的启发,开发了一个通过抽象语法树(AST)分析源代码的模型。这个模型建立在基于深度学习的长短期记忆(LSTM)和多层感知器(MLP)架构上。通过评估,它能基于python语言,有效预测源码的令牌序列(tokens)。
1.Introduction
在这个模型中,我们通过两种方法来提高数据集的重复性:1)把源码生成抽象语法树AST;2)使用转储文件(这个文件是AST的先序遍历)。然后用LSTM和MLP来训练模型。
2.Related Work
2.1 Literature Review
其中对我而言比较有用的信息:
1)Roos[7]提出了一种N-gram语言模型方法,用于快速精确地完成API代码。据他介绍,该模型可以实时工作,并在几秒钟内完成code completion的工作。
2)Li et. al.[13]利用neural attention和pionter networks对code compeletion进行了研究。他们开发了一种注意机制,能够利用程序抽象语法树上的结构化信息。
3)Ginzberg等人[14]实现了一个普通的LSTM模型来完成代码生成任务。
2.2 Sentences as probability
如何计算一句话可能出现的概率?
假设句子S=“the car runs fast”。单词s1-s4分别为“the”“car”“runs”“fast”。文章中是这样推导的(P表示概率):
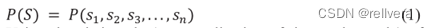
根据链式法则,上述公式可以转化成:
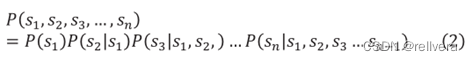
即:
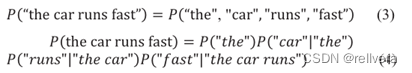
但是,像式4右半部分这边,太难算了。所以根据Markov Assumption来简化这个公式。简化成下面部分:
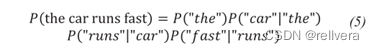
3. THEORETICAL BACKGROUND
这个研究,本质上是一个多分类研究,类别的数量就是词汇表中不同token的数量。用一组判别函数表示这种分类器:gi(x)。其中,i表示类别,x表示特征向量,gi(x)表示把特征向量x分配给某一类i。(这个地方其实不太懂呢)
损失函数使用:categorical cross entropy
激活函数使用:sigmoid/softmax
4. METHODOLOGY
4.1 Natural Language Processing Approach
首先用简单的LSTM网络进行训练和测试。
数据集来源:一个github仓库,包含1274个python源码。
预处理阶段:包含源码的各个文件被拼接成一个大文件。清洗数据(删除空格、无意义的字符),然后标记化、组织数据为固定长度的序列(tokenized and organized the dataset into
sequences of fixed length)。然后把这些序列喂入模型的嵌入层(embedding layer)。
训练和测试:训练15个epoch,accuracy为53.43%、loss为3.0.82。训练30个epoch,accuracy为53.36%,loss为3.3532。
结论:这种用来预测代码的下一个token的方法准确率很低,说明传统的NLP方法在源代码模式识别或知识发现方面的应用范围有限。
4.2 Proposed Approach
针对上述方法的不足,于是将抽象语法树AST进行应用。
数据集:与4.1中的数据集相同。
数据预处理:用抽象语法树对数据集进行预处理。然后加载这个预处理数据,为词汇表中的所有token定义一个引用字典,这个引用字典被存储到一个列表中,其每一行是一个单独的token。因为模型只接受整数值作为输入,所以作者使用了自定义的编码器对token进行编码。最后,使用sklearn将其分成输入-输出比例
4.3 Experimental design
将训练数据集分成一个个大小为n的窗口,每个窗口含有n个tokens,其中前n-1个令牌用作输入,第n个令牌作为输出。
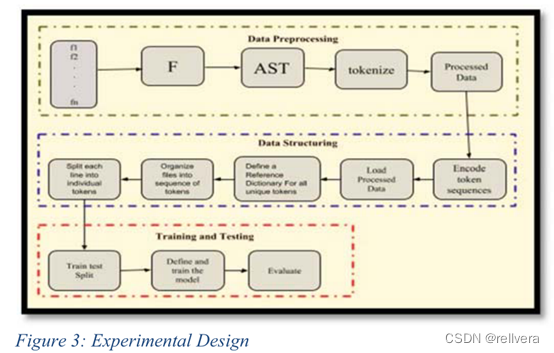
实验设计主要由三个阶段组成:数据处理阶段、数据结构阶段、训练测试阶段。
数据处理阶段:源代码(数据)加载到模型中。为了提高效率,加载的文件被传输到一个大的python对象f中。AST是从唯一的文件f生成的。
数据结构化阶段:将文本组织成tokens并为每个唯一的tokens创建字典。
训练测试阶段:将文本分割为训练数据和测试数据,并将其输入到模型中。
数据结构化阶段不太懂,根据论文,这里详写一下data structure的几个步骤:
①encode token sequences.
②load processed data
③define a reference dictionary for all unique tokens 定义一个引用字典
④organize files into sequence of tokens 把文件转化为sequence of tokens
⑤split each line into individual tokens
4.4 AST Processing
在AST处理的源代码中,树的每个节点都有一个预定的结构,这取决于所涉及的关键字或操作的类型。例如,叶节点通常是函数名、目标名或参数名。每个叶子节点都由标识符(id)和上下文(ctx)标识。
id可以是字符串变量、数字文字或本机函数,而ctx表示名称执行的任务。ctx可能的值有Load、Store、Del等。
因为结点的结构是固定的,所以相对4.1中的方法,使用AST会比较容易预测。用AST树而不是纯文本源代码来表示程序,可以方便地预测程序结构,从而确保下一个token生成的准确性更好。
4.4.1 RNN-LSTM Learning
之前的整数编码tokens被送入keras模型的嵌入层。随后将嵌入的输出序列输入LSTM层。
4.4.2 MLP Learning
用MLP继续训练
5. RESULT
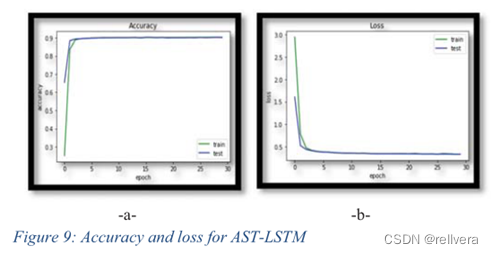
如图9所示,LSTM模型的准确率为90.32%,损失为0.3505。
除了使用AST转储来训练数据外,作者还使用了正则化。在L2正则化为0.1的情况下运行模型,可以一定程度上防止过拟合。
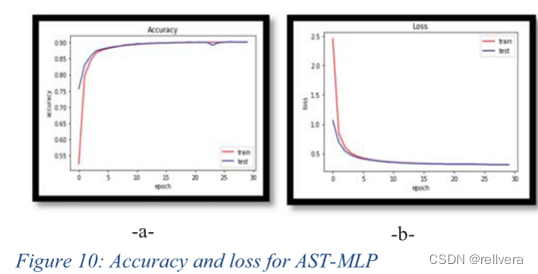
如图10所示,准确率为90.11%,损失为0.314。
6. MODEL PERFORMANCE
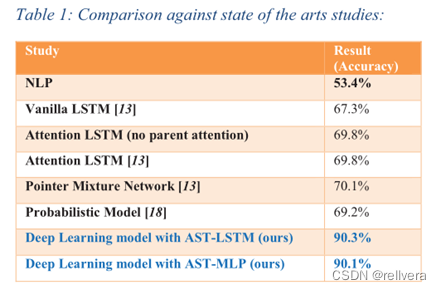
该模型与其他模型的对比。
7. CONCLUSION
主要贡献:
1.设计、开发和评估ASTLSTM/MLP代码完成模型。
2.标记化(tokenize)了1274个python源代码。
3.与NLP和Pointer Mixture Network方法相比,分别提高了69.5%和29% 。
4.LSTM和MLP的准确率分别为90.3%和90.1%。
本研究的意义如下:
1.传统的自然语言处理方法在源代码模式识别或知识发现方面的应用范围有限。
2.LSTM和MLP学习算法具有较高的代码补全或生成精度。
3.AST-LSTM是python代码补全或生成的一种有效机制。虽然MLP和LSTM的准确率都在90%以上,但LSTM在代码完成任务上比MLP更优秀,因为它的学习速度比MLP算法快得多。
总结
这篇文章实现了python代码生成。在数据预处理阶段引入了抽象语法树AST来分析源代码,然后分别用LSTM和MLP两种方法来进行训练。这个模型能有效预测源代码的令牌序列(tokens),最后再使用astunparse模块或astor以一对一的通信方式把AST转换回源代码。
疑问
- 实验设计中data structure这个部分不太懂。感觉文章中介绍得也很模糊。这部分的作用究竟是什么?为什么不能直接从data preprocessing跳到training and testing?
- 对AST其实还不太了解。一段程序是如何从代码转换成抽象语法树的?对一个AST,又如何进行先序遍历?(即:文章中的figure 5和figure 6是如何生成的?)
- 那么,这篇文章就只能实现代码的扩展和生成了?并不具备从description到code的功能?(比如:像copilot一样,写一段注释,敲tab之后就能形成推荐代码)