注:部署前可以先系统的学习一下:Introduction · Prometheus中文技术文档
在之后需要书写自定义告警的,需要在学习一下PromQL语言,一般网上也能搜到,可以在安装一个grafana可视乎验证PromQL语言
一.概述
1.什么是普罗米修斯
普罗米修斯是一个开源系统,Prometheus 收集其指标并将其存储为时间序列数据,即指标信息与记录它的时间戳一起存储,以及称为标签的可选键值对
https://prometheus.io/docs/introduction/media/
2.特征
普罗米修斯的主要特点是:
具有由指标名称和键/值对标识的时间序列数据的多维数据模型
PromQL,一种灵活的查询语言,可利用此维度
不依赖分布式存储;单服务器节点是自治的
时序收集通过 HTTP 上的拉取模型进行
通过中间网关支持推送时间序列
通过服务发现或静态配置发现目标
多种图形和仪表板支持模式
3.什么是指标?
通俗地说,指标是数字度量。时间序列意味着随时间记录更改。用户想要测量的内容因应用程序而异。对于Web服务器,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。
指标在理解应用程序以某种方式工作的原因方面起着重要作用。假设您正在运行一个 Web 应用程序,发现该应用程序很慢。您将需要一些信息来了解您的应用程序发生了什么。例如,当请求数很高时,应用程序可能会变慢。如果您有请求计数指标,则可以找出原因并增加处理负载的服务器数量。
4.组件
普罗米修斯生态系统由多个组件组成,其中许多组件是 自选:
主要的普罗米修斯服务器,用于抓取和存储时间序列数据
用于检测应用程序代码的客户端库
支持短期作业的推送网关
HAProxy、StatsD、Graphite等服务的特殊用途出口商。
用于处理警报的警报管理器
各种支持工具
大多数普罗米修斯组件都是用 Go 编写的,使得 它们易于构建和部署为静态二进制文件
5.架构图
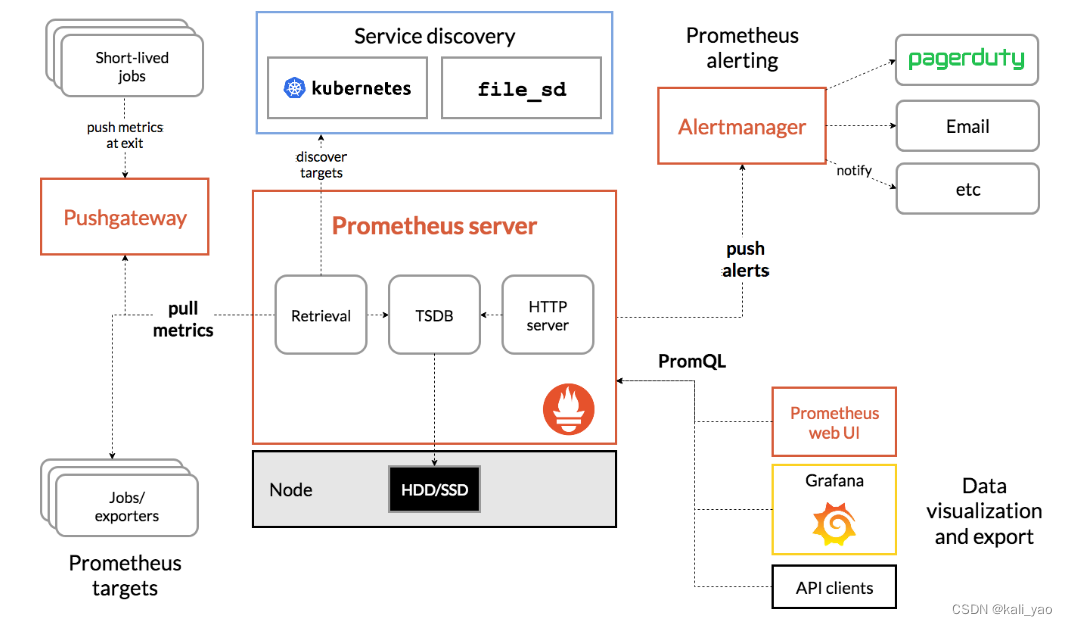
5.1官网结构图
5.2.本文简易架构图
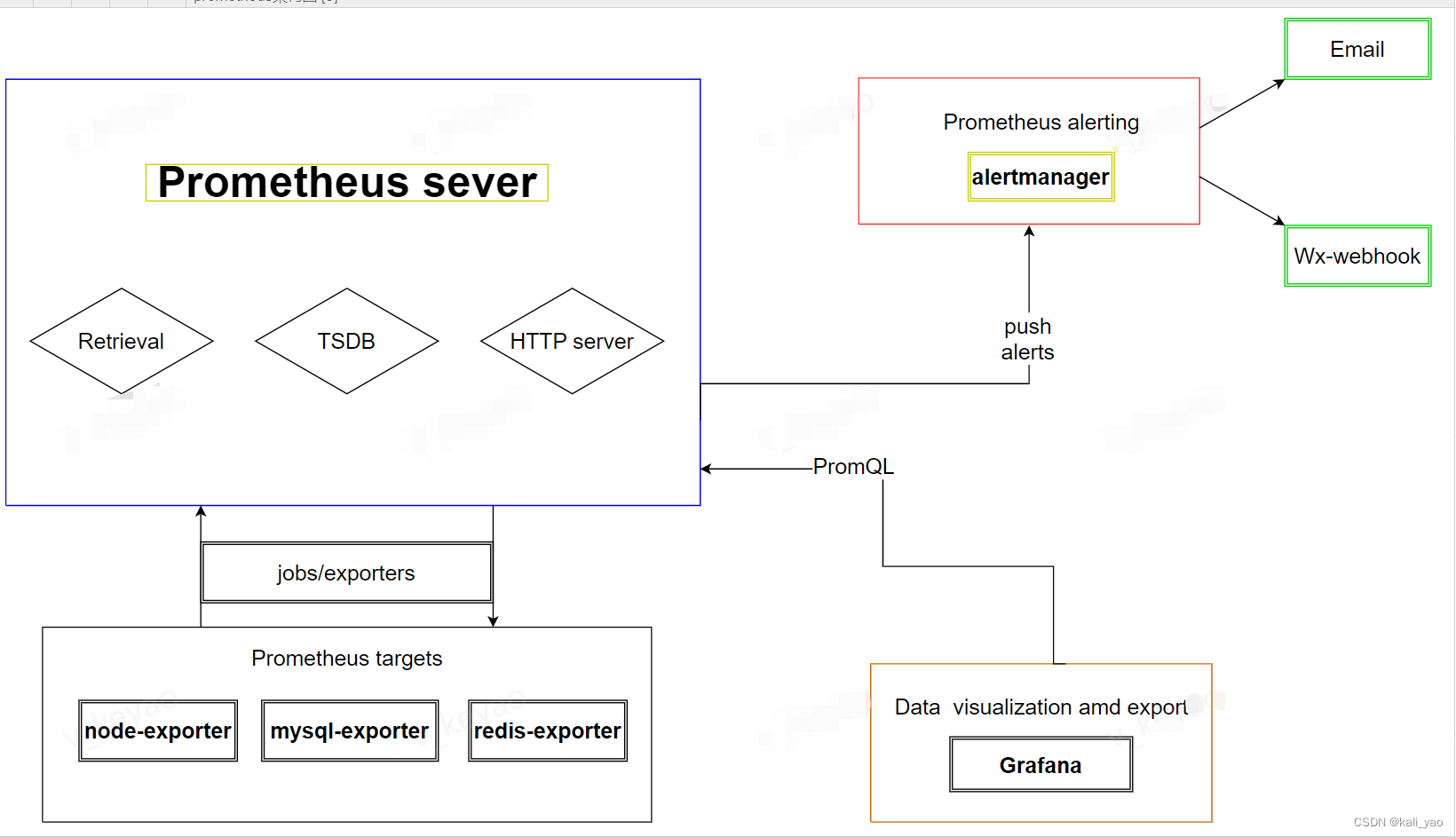
Prometheus 直接从检测的作业中抓取指标,也可以通过 用于短期作业的中间推送网关。它存储所有刮擦的样品 在本地并对此数据运行规则以聚合和记录新时间 从现有数据中序列或生成警报。格拉法纳或 其他 API 使用者可用于可视化收集的数据。
5.3.组件概述
Prometheus Server
于收集和存储时间序列数据。Prometheus Server 是 Prometheus 组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server 可以通过静态配置管理监控目标,也可以配合使用 Service Discovery 的方式动态管理监控目标,并从这些监控目标中获取数据。其次 Prometheus Server 需要对采集到的监控数据进行存储,Prometheus Server 本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server 对外提供了自定义的 PromQL 语言,实现对数据的查询以及
Node-Exporter
用于暴露已有的第三方服务的 metrics 给 Prometheus。Exporter 将监控数据采集的端点通过 HTTP 服务的形式暴露给 Prometheus Server,Prometheus Server 通过访问该 Exporter 提供的 Endpoint 端点,即可获取到需要采集的监控数据。
Grafana
第三方展示工具,可以编写 PromQL 查询语句,通过 http 协议与 prometheus 集成
AlertManager
从 Prometheus Server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,钉钉、企业微信,pagerduty等
Push Gateway
主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这些 jobs 可以直接向 Prometheus server 端推送它们的 metrics。
5.4.Prometheus工作流程
指标采集
prometheus server 通过 pull 形式采集监控指标,可以直接拉取监控指标,也可以通过 pushgateway 做中间环节,监控目标先 push 形式上报数据到 pushgateway;
指标处理
prometheus server 将采集的数据存储在自身 db 或者第三方 db;
指标展示
prometheus server 通过提供 http 接口,提供自带或者第三方展示系统;
指标告警
prometheus server 通过 push 告警信息到 alert-manager,alert-manager 通过"静默-抑制-整合-下发"4个阶段处理通知到观察者
5.5.Prometheus四种指标分类
Counter
计数器类型,只增不减,如机器的启动时间,HTTP 访问量等。机器重启不会置零,在使用这种指标类型时,通常会结合rate()方法获取该指标在某个时间段的变化率。
Gauge
仪表盘,可增可减,如CPU使用率,大部分监控数据都是这种类型的。
Summary
客户端定义;Summary,Histogram 都属于高级指标,用于凸显数据的分布情况。
二.安装prometheus
1.下载镜像
1.1.prometheus镜像
# 主服务数据库
~]# docker search prometheus
~]# docker pull bitnami/prometheus1.2.node-exporter镜像
# 暴露被监控节点
~]# docker search node-exporter
~]# docker pull prom/node-exporter1.3.alertmanager镜像
# 告警服务
~]# docker search alertmanager
~]# docker pull prom/alertmanager1.4.webhook镜像需要后续制作
# Webhook是一个API概念,webhook是一种web回调或者http的push API.Webhook作为一个轻量的事件处理应用
xxxxxx
2.安装prometheus部署节点
2.1.先书写主配置文件
~]# vim prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager的本机真实ip:9093"]
rule_files:
-"/etc/prometheus/rule.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ["prometheus的本机真实ip:9090"]
- job_name: 'node-exporter'
static_configs:
- targets: ["node节点的真实ip:9100","node节点的真实ip:9100","node节点的真实ip:9100"]
- job_name: 'alertmanager'
static_configs:
- targets: ["alertmanager的本机真实ip:9093"]2.2创建rule告警阈值
# 这里为例方便测试设置为up==1
~]# vim rule.yml
groups:
- name: Hosts.rules
rules:
- alert: HostDown
expr: up{job=~"node-exporter|prometheus|grafana|alertmanager"} == 0
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
## 注意==0为报警条件,当有服务宕机测会告警,如果测试需改为1
注:- alert: HostDown这个数据本机基本数据类,如果要监控其他的可以设置例外的名字2.3.启动容器
# 创建数据目录
~]# mkdir /data/prometheus/data/
# 启动
~]# docker run -d -p 9090:9090 --name prometheus --restart=always -v /data/prometheus/data/:/data -v /root/docker-prometheus/prometheus.yml:/data/prometheus.yml -v /root/docker-prometheus/rule.yml:/data/rule.yml prom/prometheus --config.file=/data/prometheus.yml --web.enable-lifecycle --storage.tsdb.retention=90d
## --restart=always 还可以设置自动重启容器
# -d --detach=false, 指定容器运行于前台还是后台,默认为false
# --net 网络模式,host网络互通模式
# --web.enable-lifecycle 热更新
# -v 给容器挂载存储卷,挂载到容器的某个目录(宿主机目录:/docker目录),注意本地需要要该文件2.4.查看主服务部署状况
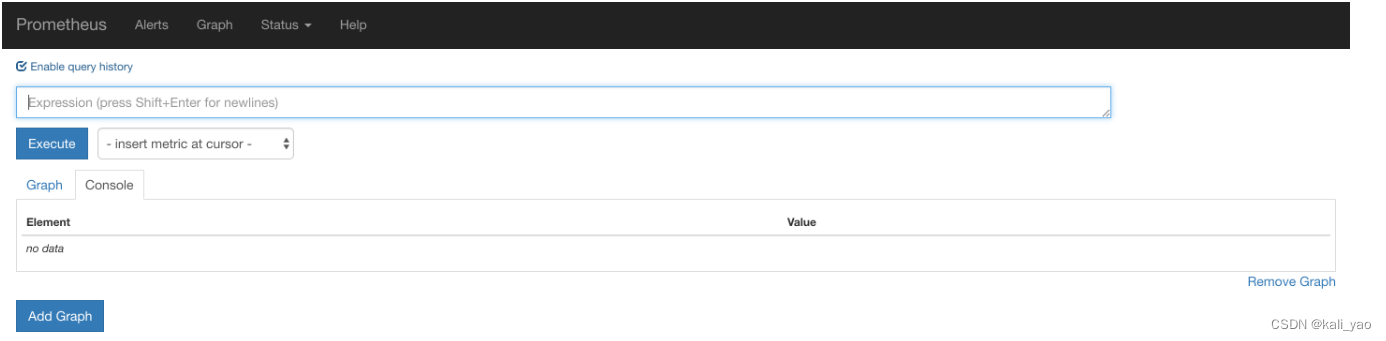
http://172.17.0.62:9090访问Prometheus的UI界面
2.5.其他命令
# 查看日志
~]# docker ps -a | grep prome
d54fc1e2751d prom/prometheus "/bin/prometheus --c…" 7 hours ago Up 13 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
~]# docker logs d54fc1e2751d
# 进容器查看配置文件是否报错
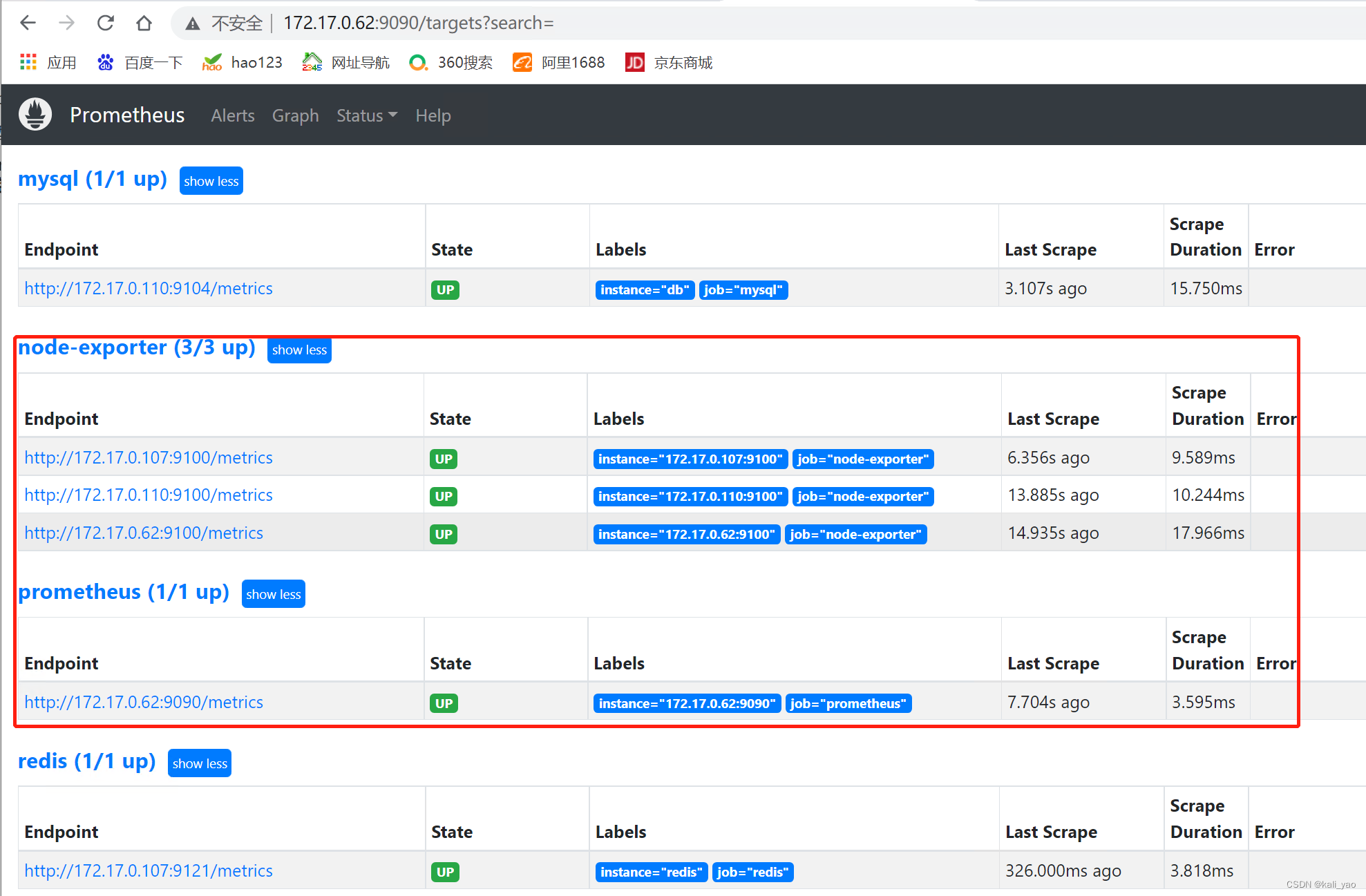
~]# promtool check config /etc/prometheus/prometheus.yml 3.安装暴露节点node-exporter
3.1.安装容器
~]# docker run -d --name node-exporter --restart=always -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter
# 常用选项说明
-d, --detach=false, 指定容器运行于前台还是后台,默认为false
--net="host", 容器网络设置:
bridge 使用docker daemon指定的网桥
host 容器使用主机的网络
container:NAME_or_ID > 使用其他容器的网路,共享IP和PORT等网络资源
none 容器使用自己的网络(类似--net=bridge),但是不进行配置
--cap-add=[], 添加权限,权限清单如下,SYS_TIME:设置实时时间:
--pid="host" 将 PID 模式设置为主机 PID 模式。这将打开之间的共享 容器和主机操作系统的 PID 地址空间。 使用此标志启动的容器可以访问和操作其他 裸机计算机命名空间中的容器,反之亦然。
-v 给容器挂载存储卷,挂载到容器的某个目录(/宿主机目录:/docker目录)
-e, --env=[], 指定环境变量,容器中可以使用该环境变量,设置容器 ,HOST=ip,PORTO=端口
/start 启动之后要执行的命令(可以是shell也可以是脚本),如带/bin/bash则是解释器(注:脚本启动失败则容器启动失败)
--restart=always 还可以设置自动重启容器3.2.参数概述
--cap-add所有参数
Capability Key |
Capability Description |
AUDIT_WRITE |
Write records to kernel auditing log. |
CHOWN |
Make arbitrary changes to file UIDs and GIDs (see chown(2)). |
DAC_OVERRIDE |
Bypass file read, write, and execute permission checks. |
FOWNER |
Bypass permission checks on operations that normally require the file system UID of the process to match the UID of the file. |
FSETID |
Don’t clear set-user-ID and set-group-ID permission bits when a file is modified. |
KILL |
Bypass permission checks for sending signals. |
MKNOD |
Create special files using mknod(2). |
NET_BIND_SERVICE |
Bind a socket to internet domain privileged ports (port numbers less than 1024). |
NET_RAW |
Use RAW and PACKET sockets. |
SETFCAP |
Set file capabilities. |
SETGID |
Make arbitrary manipulations of process GIDs and supplementary GID list. |
SETPCAP |
Modify process capabilities. |
SETUID |
Make arbitrary manipulations of process UIDs. |
SYS_CHROOT |
Use chroot(2), change root directory. |
The next table shows the capabilities which are not granted by default and may be added.
Capability Key |
Capability Description |
AUDIT_CONTROL |
Enable and disable kernel auditing; change auditing filter rules; retrieve auditing status and filtering rules. |
AUDIT_READ |
Allow reading the audit log via multicast netlink socket. |
BLOCK_SUSPEND |
Allow preventing system suspends. |
BPF |
Allow creating BPF maps, loading BPF Type Format (BTF) data, retrieve JITed code of BPF programs, and more. |
CHECKPOINT_RESTORE |
Allow checkpoint/restore related operations. Introduced in kernel 5.9. |
DAC_READ_SEARCH |
Bypass file read permission checks and directory read and execute permission checks. |
IPC_LOCK |
Lock memory (mlock(2), mlockall(2), mmap(2), shmctl(2)). |
IPC_OWNER |
Bypass permission checks for operations on System V IPC objects. |
LEASE |
Establish leases on arbitrary files (see fcntl(2)). |
LINUX_IMMUTABLE |
Set the FS_APPEND_FL and FS_IMMUTABLE_FL i-node flags. |
MAC_ADMIN |
Allow MAC configuration or state changes. Implemented for the Smack LSM. |
MAC_OVERRIDE |
Override Mandatory Access Control (MAC). Implemented for the Smack Linux Security Module (LSM). |
NET_ADMIN |
Perform various network-related operations. |
NET_BROADCAST |
Make socket broadcasts, and listen to multicasts. |
PERFMON |
Allow system performance and observability privileged operations using perf_events, i915_perf and other kernel subsystems |
SYS_ADMIN |
Perform a range of system administration operations. |
SYS_BOOT |
Use reboot(2) and kexec_load(2), reboot and load a new kernel for later execution. |
SYS_MODULE |
Load and unload kernel modules. |
SYS_NICE |
Raise process nice value (nice(2), setpriority(2)) and change the nice value for arbitrary processes. |
SYS_PACCT |
Use acct(2), switch process accounting on or off. |
SYS_PTRACE |
Trace arbitrary processes using ptrace(2). |
SYS_RAWIO |
Perform I/O port operations (iopl(2) and ioperm(2)). |
SYS_RESOURCE |
Override resource Limits. |
SYS_TIME |
Set system clock (settimeofday(2), stime(2), adjtimex(2)); set real-time (hardware) clock. |
SYS_TTY_CONFIG |
Use vhangup(2); employ various privileged ioctl(2) operations on virtual terminals. |
SYSLOG |
Perform privileged syslog(2) operations. |
WAKE_ALARM |
Trigger something that will wake up the system. |
3.3.查看
3.4.其他命令
## 查看日志
~]# docker ps -a | grep ale
ed860d9e67d6 prom/alertmanager "/bin/alertmanager -…" 5 hours ago Up 31 minutes 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp alertmanager
~]# docker logs ed84.安装告警主机
4.1.书写基本邮件告警
~]# vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xfjoexdzymztbjac' # 注意不是邮件密码
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
send_resolved: true全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
告警路由(route):根据标签匹配,确定当前告警应该如何处理;
接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
4.2.启动容器
~]# docker run -d -p 9093:9093 --restart always --name alertmanager -v /root/docker-prometheus/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
# -d --detach=false, 指定容器运行于前台还是后台,默认为false
# --net 网络模式,host网络互通模式
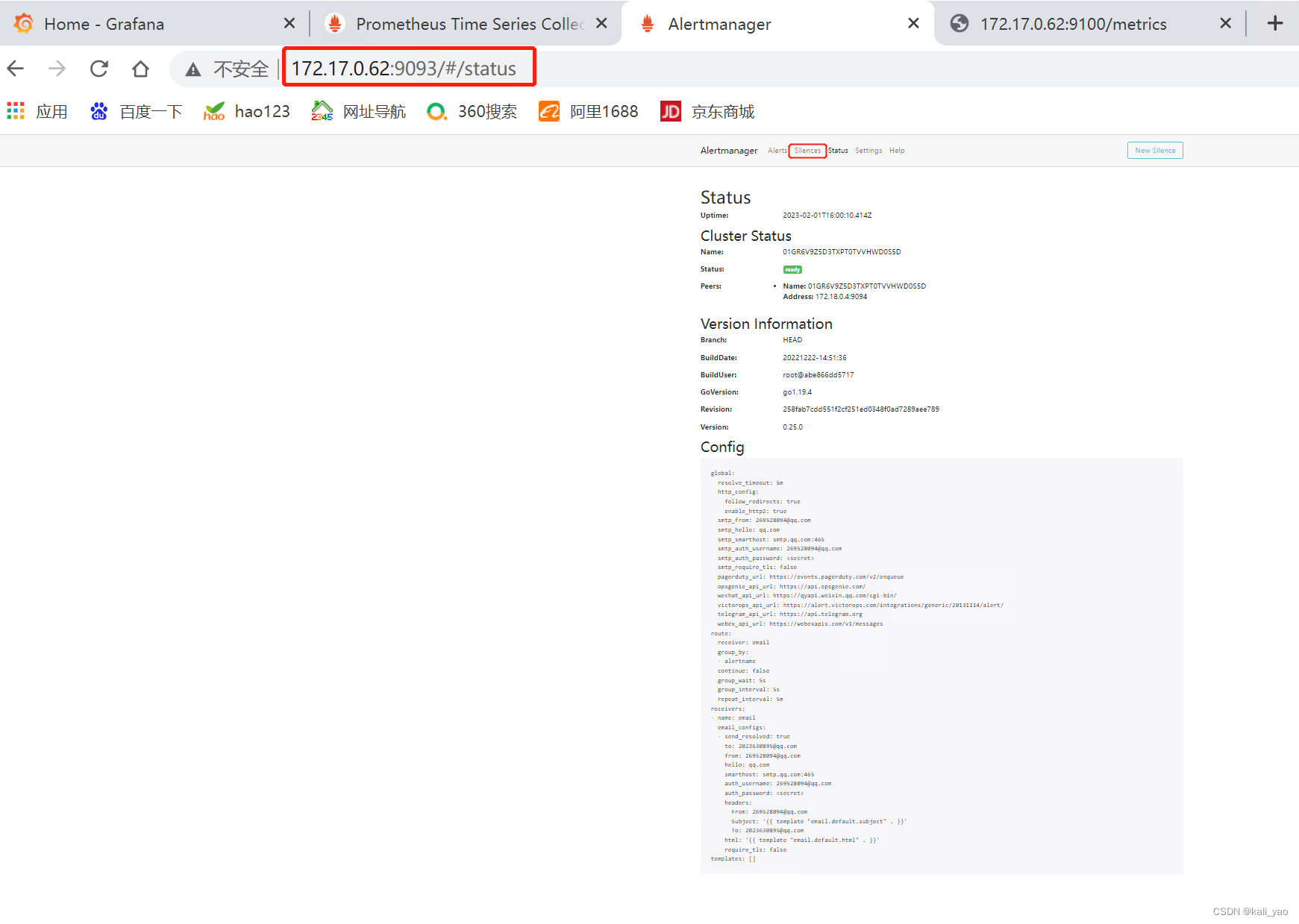
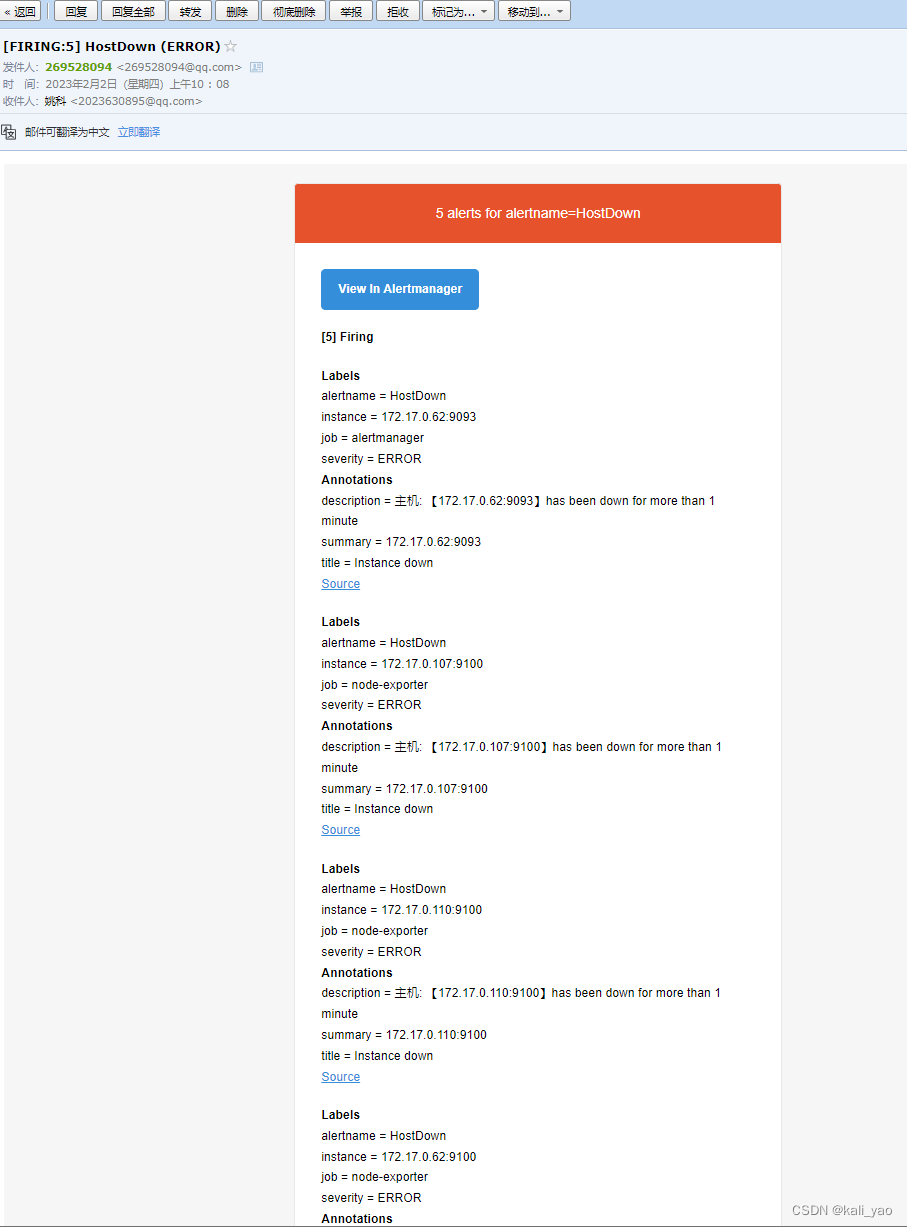
# --restart=always 还可以设置自动重启容器4.3.查看并等待告警
三.告警配置
1.邮件告警
1.1.指定告警配置
# 书写自定义告警配置
~]# vim email.tmpl
{
{ define "email.to.html" }} # 告警标题在alertmagar引用
{
{- if gt (len .Alerts.Firing) 0-}} # 告警有两种状态(Firing和Resolved)
{
{- range $index, $alert := .Alerts -}} # 格式书写
========= <span style=color:red;font-size:36px;font-weight:bold;> 监控告警 </span>=========<br>
告警程序: Alertmanager <br>
告警类型: {
{ $alert.Labels.alertname }} <br>
告警级别: {
{ $alert.Labels.severity }} 级 <br>
告警状态: {
{ .Status }} <br>
故障主机: {
{ $alert.Labels.instance }} {
{ $alert.Labels.device }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ $alert.Annotations.message }}{
{ $alert.Annotations.description}} <br>
主机标签: {
{ range .Labels.SortedPairs }} <br> [{
{ .Name }}: {
{ .Value | html }} ]{
{ end }}<br>
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
{
{- end }}
{
{- end }}
========== end = =========
{
{- if gt (len .Alerts.Resolved) 0-}}
{
{- range $index, $alert := .Alerts -}}
========= <span style=color:#00FF00;font-size:24px;font-weight:bold;> 告警恢复 </span>=========<br>
告警程序: Alertmanager <br>
告警类型: {
{ $alert.Labels.alertname }} <br>
告警级别: {
{ $alert.Labels.severity }} 级 <br>
告警状态: {
{ .Status }} <br>
故障主机: {
{ $alert.Labels.instance }} {
{ $alert.Labels.device }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ $alert.Annotations.message }}{
{ $alert.Annotations.description}} <br>
主机标签: {
{ range .Labels.SortedPairs }} <br> [{
{ .Name }}: {
{ .Value | html }} ]{
{ end }}<br>
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
{
{- end }}
{
{- end }}
========== end = =========
{
{- end }}
# 注:时间任意只要格式相同,系统默认会输出当前时间
##------------------------------------------##
## 修改alertmanager告警配置,指定自定义告警配置
~]# vim alertmanager
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xfjoexdzymztbjac'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates:
-'/etc/alertmanager/*.tmpl'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
html: '{
{ template "email.to.html" . }}'
headers: { Subject: "[WARN]告警" }
send_resolved: true
# (group_wait: 5s ;group_interval: 5s repeat_interval: 5m注意这三者之间的时间)
##-----------------------------------------##
# 重新起容器,这个旧的关闭
~]# docker run -d -p 9093:9093 --restart always --name alertmanager -v /root/docker-prometheus/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /root/docker-prometheus/email.tmpl:/etc/alertmanager/email.tmpl prom/alertmanager
## 基本参数概述
# -d --detach=false, 指定容器运行于前台还是后台,默认为false
# --net 网络模式,host网络互通模式
--cap-add=[], 添加权限,权限清单如下,SYS_TIME:设置实时时间:SYS_PTRACE:防止进程agetty占用宿主机的cpu
--pid="host" 将 PID 模式设置为主机 PID 模式。这将打开之间的共享 容器和主机操作系统的 PID 地址空间。 使用此标志启动的容器可以访问和操作其他 裸机计算机命名空间中的容器,反之亦然。
-v 给容器挂载存储卷,挂载到容器的某个目录(/宿主机目录:/docker目录)
-e, --env=[], 指定环境变量,容器中可以使用该环境变量,设置容器 ,HOST=ip,PORTO=端口注:-cap-add参数是出于对安全的考虑,在启动容器时,docker容器里的系统只具有一些普通的linux权限,并不具有真正root用户的所有权限。而--privileged=true参数可以让docker容器具有linux root用户的所有权限。
为了解决这个问题,docker后来的版本中docker run增加了两个选项参数"--cap-add"和"--cap-drop"。则是避免混淆权限,SYS_TIME:设置实时时间;SYS_PTRACE防止进程agetty占用宿主机的cpu
1.2.查看容器状态及告警
# 查看容器是否启动
~]# docker ps -a | grep alertmanager
ed860d9e67d6 prom/alertmanager "/bin/alertmanager -…" 5 hours ago Up 31 minutes 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp alertmanager查看告警是否正常

修改Prometheus自定阀值参数(之前为1)
~]# vim rule.yml
groups:
- name: Hosts.rules
rules:
- alert: HostDown
expr: up{job=~"node-exporter|prometheus|grafana|alertmanager"} ==0 # 等于0则会恢复告警
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
# 重启容器(之前有做持久化-v)
~]# docker ps -a | grep prome
~]# docker stop d54
~]# docker start d54 告警状态

2.企业微信机器人告警
2.1.创建机器人
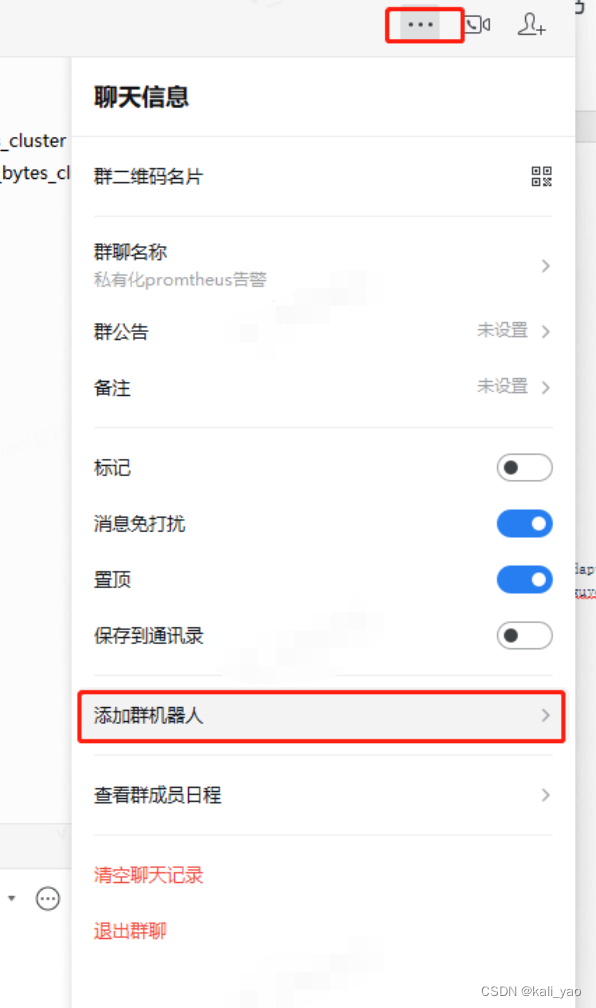
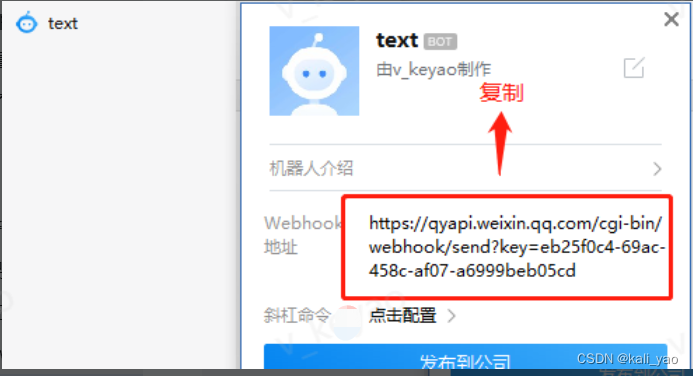
注:首先要有个群
2.2.创建webhook容器
1.flask程序代码
~]# vim app.py
# -*- coding: utf-8 -*-
importos
importjson
importrequests
importarrow
fromflaskimportFlask
fromflaskimportrequest
app = Flask(__name__)
defbytes2json(data_bytes):
data = data_bytes.decode('utf8').replace("'", '"')
returnjson.loads(data)
defmakealertdata(data):
foroutputindata['alerts'][:]:
ifoutput['status'] == 'firing':
status_zh = '<font color=\"warning\">告警</font>'
title = '【%s】TAPD告警 %s 有新的报警'% (status_zh,output['labels']['instance'])
send_data = {
"msgtype": "markdown",
"markdown": {
"content": "## %s \n\n"%title+
">**告警类型**: %s \n\n"%output['labels']['alertname'] +
">**告警级别**: %s \n\n"%output['labels']['severity'] +
">**告警状态**: %s \n\n"%output['status'] +
">**告警主机**: %s \n\n"%output['annotations']['summary'] +
">**告警负责人**: %s \n\n"%"<@v_keyao>"+
">**告警详情**: %s \n\n"%output['annotations']['description'] +
">**触发时间**: %s \n\n"%arrow.get(output['startsAt']).to('Asia/Shanghai').format(
'YYYY-MM-DD HH:mm:ss ZZ')
}
}
elifoutput['status'] == 'resolved':
status_zh = '<font color=\"info\">恢复</font>'
title = '【%s】TAPD环境 %s 有报警恢复'% (status_zh, output['labels']['instance'])
send_data = {
"msgtype": "markdown",
"markdown": {
"content": "## %s \n\n"%title+
">**告警类型**: %s \n\n"%output['labels']['alertname'] +
">**告警级别**: %s \n\n"%output['labels']['severity'] +
">**告警状态**: %s \n\n"%output['status'] +
">**告警主机**: %s \n\n"%output['annotations']['summary'] +
">**告警负责人**: %s \n\n"%"<@v_keyao>"+
">**告警详情**: %s \n\n"%output['annotations']['description'] +
">**触发时间**: %s \n\n"%arrow.get(output['startsAt']).to('Asia/Shanghai').format(
'YYYY-MM-DD HH:mm:ss ZZ') +
">**触发结束时间**: %s \n"%arrow.get(output['endsAt']).to('Asia/Shanghai').format(
'YYYY-MM-DD HH:mm:ss ZZ')
}
}
returnsend_data
defsend_alert(data):
token = os.getenv('ROBOT_TOKEN')
ifnottoken:
print('you must set ROBOT_TOKEN env')
return
url = 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=%s'%token
send_data = makealertdata(data)
req = requests.post(url, json=send_data)
result = req.json()
ifresult['errcode'] != 0:
print('notify dingtalk error: %s'%result['errcode'])
@app.route('/', methods=['POST', 'GET'])
defsend():
ifrequest.method == 'POST':
post_data = request.get_data()
send_alert(bytes2json(post_data))
return'success'
else:
return'weclome to use prometheus alertmanager dingtalk webhook server!'
if__name__ == '__main__':
app.run(host='0.0.0.0', port=5000)注:中间的先发一个普通的邮件告警看一下有哪些键值如下:
2.python模块依赖
~]# vim requirements.txt
certifi==2018.10.15
chardet==3.0.4
Click==7.0
Flask==1.0.2
idna==2.7
itsdangerous==1.1.0
Jinja2==2.10
MarkupSafe==1.1.0
requests==2.20.1
urllib3==1.24.1
Werkzeug==0.14.1
arrow==0.13.13.书写dockerfile
~]# vim Dockerfile
FROM python:3.6.4
# set working directory
WORKDIR /src
# add app
ADD . /src
# install requirements
RUN pip install selectivesearch -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
RUN pip install -r requirements.txt
EXPOSE 500
# run server
CMD python app.py4.运行
~]# docker run -d -p 8060:5000 --restart always --name webhook -v /etc/localtime:/etc/localtime:ro -v /data/alertmanager/app.py:/src/app.py -e ROBOT_TOKEN=eb25f0c4-69ac-458c-af07-a6999beb05cd webhook:v128baf72d5f6a42e9c1c8374e57836d1659bb109981d5bf7a9654aa599532c314
# 注意-v文件的位置(本地文件位置可能改变)
-e:指定机器人密钥
# 查看启动状态
~]# docker ps -a | grep webhook
~]# docker exec -it xxx sh
# env
HOSTNAME=28baf72d5f6a
GPG_KEY=0D96DF4D4110E5C43FBFB17F2D347EA6AA65421D
ROBOT_TOKEN=eb25f0c4-69ac-458c-af07-a6999beb05cd2.3.修改alertmanager
~]# vim alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: '172.17.0.62:8060'
send_resolved: true
# 重启容器alertmanager
~]# docker ps -a | grep alertmanager
ed860d9e67d6 prom/alertmanager "/bin/alertmanager -…" 6 hours ago Up About a minute 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp alertmanager
~]# docker stop ed8
~]# docker start ed82.4.查看
# 1.查看Prometheus是否报错
~]# docker ps -a | grep prometheus
d54fc1e2751d prom/prometheus "/bin/prometheus --c…" 11 hours ago Up 4 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
~]# docker logs d54
# 2.查看alermanager是否报错
]# docker ps -a | grep alertmanager
d4301871c6e3 prom/alertmanager "/bin/alertmanager -…" 43 minutes ago Up 4 minutes 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp alertmanager
~]# docker logs d43
# 3.查看webhook是否报错
~]# docker ps -a | grep webhook
fb8620f47a65 webhook:v1 "/bin/sh -c 'python …" About an hour ago Up About an hour 500/tcp, 0.0.0.0:8060->5000/tcp, :::8060->5000/tcp webhook
~]# docker logs fb86
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
172.18.0.1 -- [02/Feb/2023 20:24:13] "POST / HTTP/1.1"200-
172.18.0.1 -- [02/Feb/2023 20:29:18] "POST / HTTP/1.1"200-
# 以上为正常
## 告警排查
# 1.排查alertmanager是否挂载入容器
# 2.排查prometheus告警阈值是否设置为错
# 3.webhook是否正确
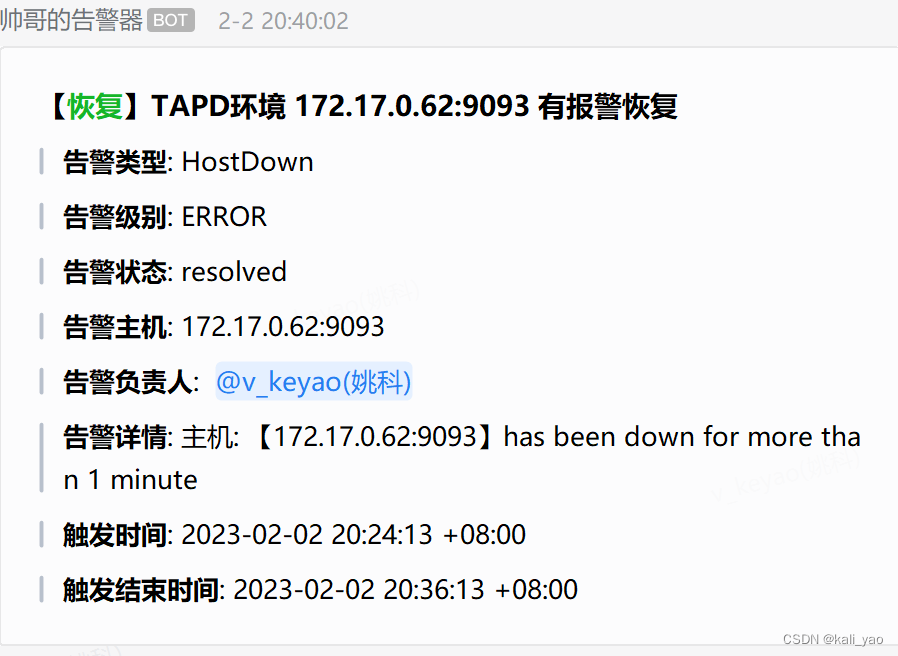
修改告警参数,告警恢复(注意重启容器)
3.测试alertmanager机器
~]# vim ceshi.sh
#!/bin/bash
alerts_message='[
{
"labels": {
"alertname": "磁盘已满",
"dev": "sda1",
"instance": "实例1",
"msgtype": "testing"
},
"annotations": {
"info": "程序员小王提示您:这个磁盘sda1已经满了,快处理!",
"summary": "请检查实例示例1"
}
},
{
"labels": {
"alertname": "磁盘已满",
"dev": "sda2",
"instance": "实例1",
"msgtype": "testing"
},
"annotations": {
"info": "程序员小王提示您:这个磁盘sda2已经满了,快处理!",
"summary": "请检查实例示例1",
"runbook": "以下链接http://test-url应该是可点击的"
}
}
]'
curl-XPOST-d"$alerts_message" http://127.0.0.1:9093/api/v1/alerts
~]# bash ceshi.sh
{"status":"success"}测试结果
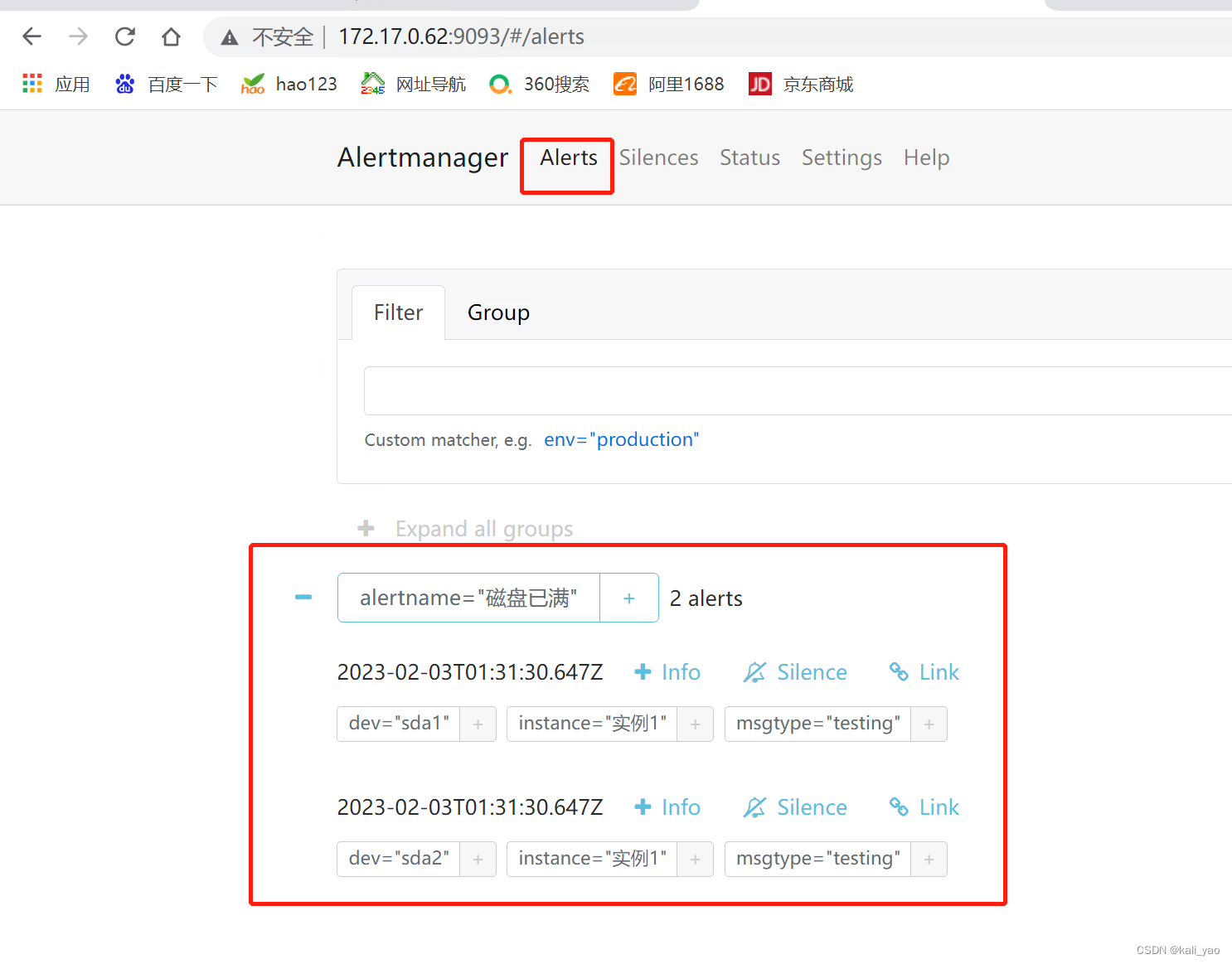
四.添加redis和mysql监控
1.redis监控
1.1.安装redis
~]# wget http://download.redis.io/releases/redis-5.0.7.tar.gz
~]# tar -zvxf redis-5.0.7.tar.gz
~]# mv /root/redis-5.0.7 /usr/local/redis
~]# cd /usr/local/redis
~]# make
~]# make PREFIX=/usr/local/redis install
1.2.启动redis
~]# cd /usr/local/redis
# 设置外网可以访问
~]# vim /usr/local/redis/redis.conf
daemonize yes
# 启动
~]# ./bin/redis-server ./redis.conf
~]# ss -nutlp | grep 6379
~]# ps -ef | grep redis
~]# cd /usr/local/redis/
~]# cp src/redis-cli bin/
~]# cd bin/
~]# ./redis-cli
CONFIG GET * # 查看详情
注:这里不做过多的redis概述1.3.安装Redis Exporter监控redis
# 部署redis exporter
~]# wget https://github.com/oliver006/redis_exporter/releases/download/v1.6.1/redis_exporter-v1.6.1.linux-amd64.tar.gz
~]# tar -xf redis_exporter-v1.6.1.linux-amd64.tar.gz
~]# mv redis_exporter-v1.3.2.linux-amd64 /data/redis_exporter
#################################################
## 测试
# 无密码
./redis_exporter redis//172.17.0.107:6379 &
# 有密码
./redis_exporter -redis.addr 172.17.0.107:6379 -redis.password 123456 &
-redis.addr string:Redis实例的地址,可以使一个或者多个,多个节点使用逗号分隔,默认为 "redis://localhost:6379"
-redis.password string:Redis实例的密码
-web.listen-address string:服务监听的地址,默认为 0.0.0.0:9121
##################################################
## 设置systemd管理
~]# cat > /etc/systemd/system/redis_exporter.service <<EOF
[Unit]
Description=redis_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/data/redis_exporter/redis_exporter redis//172.17.0.107:6379 # 这里填写启动命令(没有密码就用上面那个)
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 注:这里启动用户是prometheus所以需要创建
~]# groupadd prometheus
~]# useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
~]# chown -R prometheus:prometheus /data/redis_exporter
~]# systemctl daemon-reload
# 注:启动前先kill掉之前用当前启动的方式(ps -ef | grep resi)
~]# systemctl start redis_exporter
~]# ss -tln | grep 9121
LISTEN 0 128 [::]:9121 [::]:*
~]# systemctl stop redis_exporter
~]# ss -tln | grep 91211.4.添加监控目标
~]# vim prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
alerting:
alertmanagers:
- static_configs:
- targets: ["172.17.0.62:9093"]
rule_files:
- "/etc/prometheus/rule.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ["172.17.0.62:9090"]
- job_name: 'node-exporter'
static_configs:
- targets: ["172.17.0.62:9100","172.17.0.107:9100","172.17.0.110:9100"]
- job_name: 'alertmanager'
static_configs:
- targets: ["172.17.0.62:9093"]
- job_name: redis # 添加如下:
static_configs:
- targets: ['172.17.0.107:9121']# 监控redis机器的ip
labels:
instance: redis
# 重启Prometheus容器(之前做了持久化所以可以直接重启)
~]# docker ps -a | grep prome
d54fc1e2751d prom/prometheus "/bin/prometheus --c…" 25 hours ago Up 2 seconds 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
~]# docker stop d54
d54
~]# docker start d54
d54
~]# docker ps -a | grep prome
d54fc1e2751d prom/prometheus "/bin/prometheus --c…" 25 hours ago Up 2 seconds 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus1.5.验证并查看
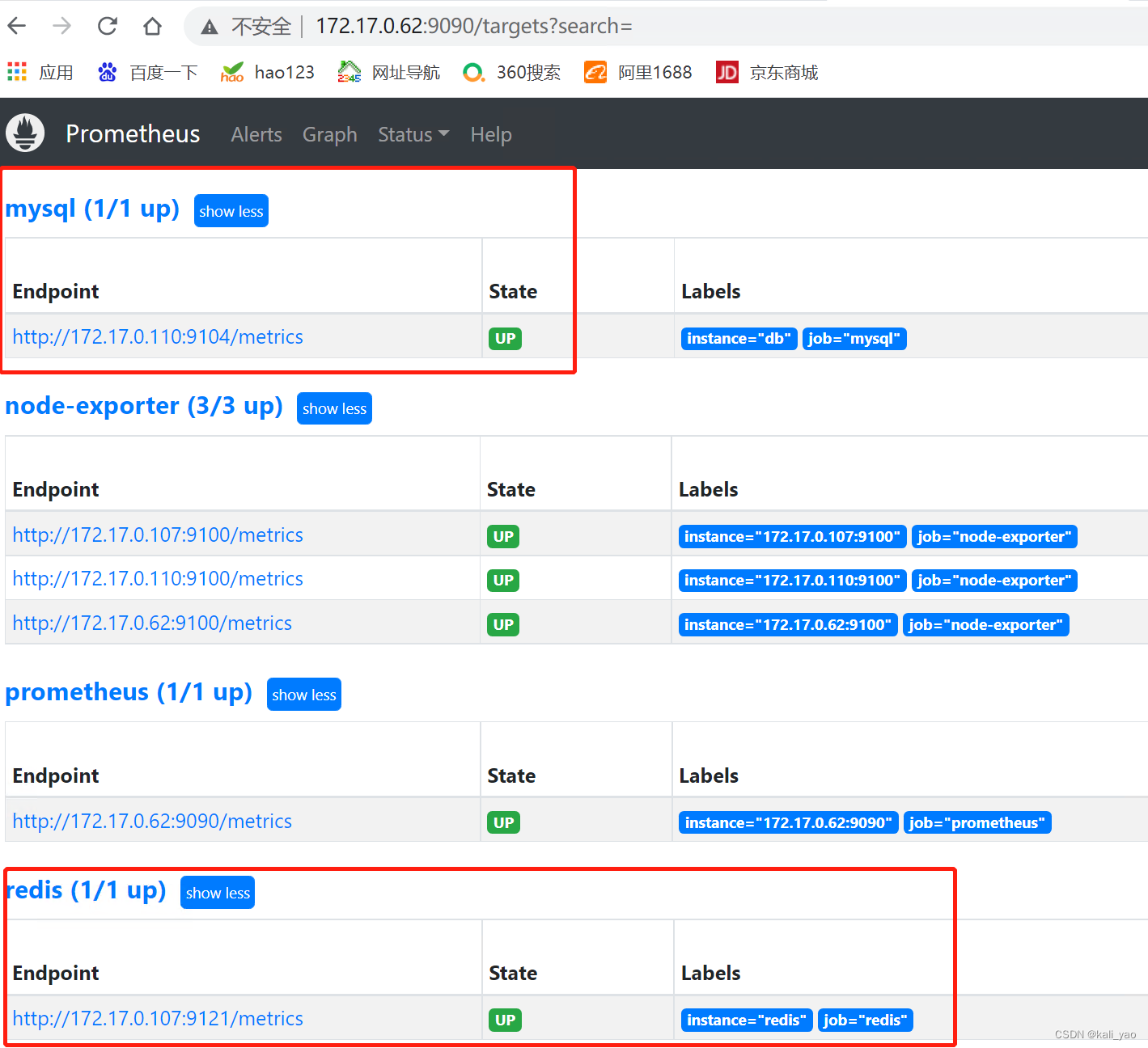
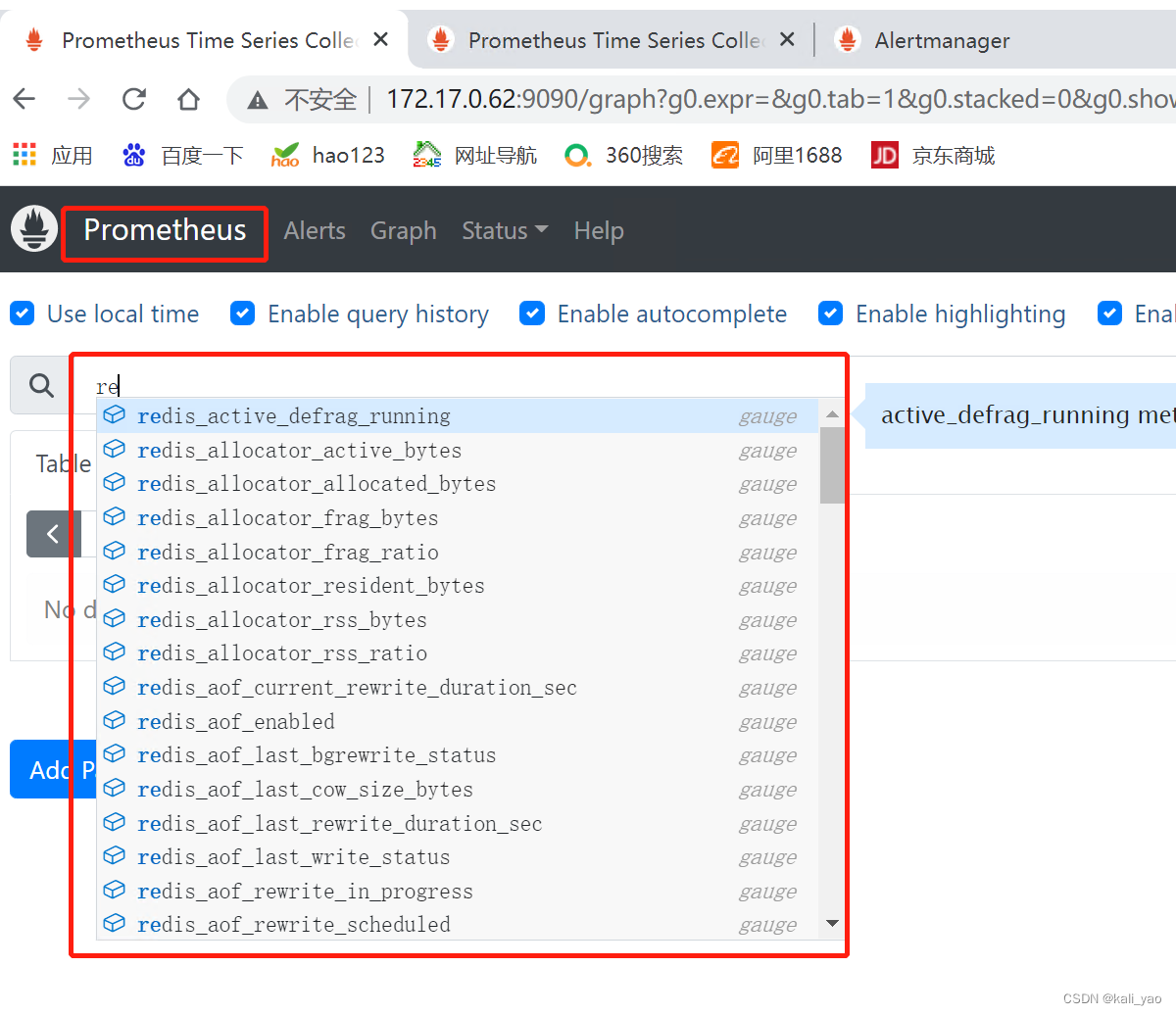
设置告警阈值测试
~]# vim rule.yml
groups:
- name: Hosts.rules
rules:
- alert: HostDown
expr: up{job=~"node-exporter|prometheus|grafana|alertmanager"} ==0
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
- alert: redis
expr: up{job=~"redis"} ==1
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
## 之前有做持久化直接重启容器
~]# docker stop d54
d54
~]# docker start d54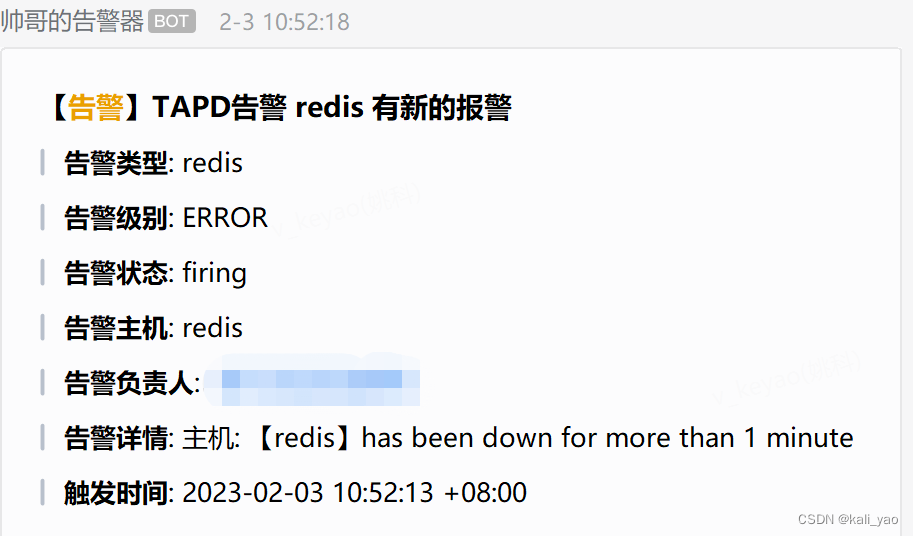
在把阈值修改为正确的则会恢复

2.mysql监控
2.1.安装mysql
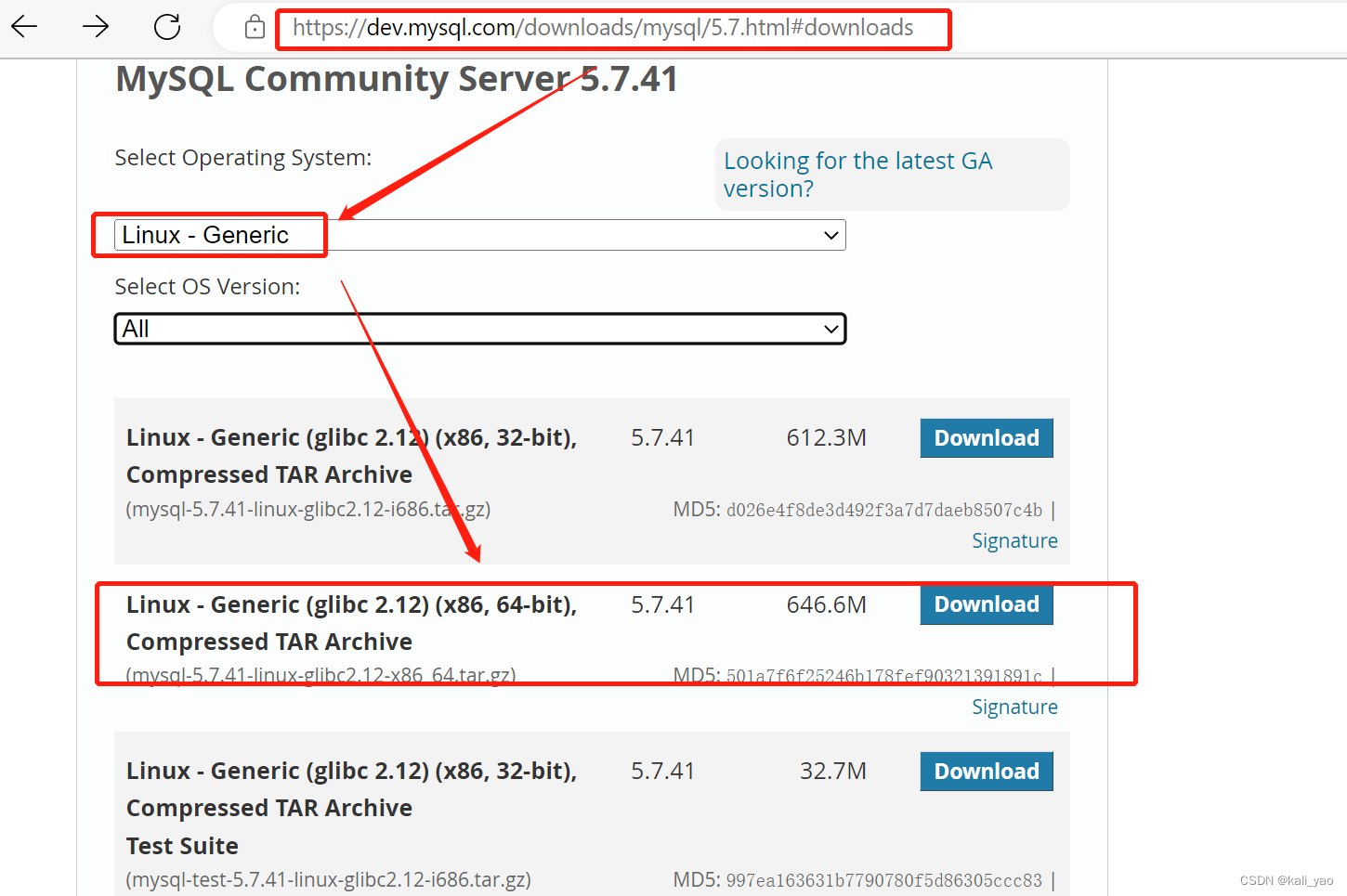
1.下载tar包
链接:https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.41-linux-glibc2.12-x86_64.tar.gz
2.解压安装(绿色软件可直接使用)
~]# tar -xf mysql-5.7.41-linux-glibc2.12-x86_64.tar.gz
~]# mv mysql-5.7.41-linux-glibc2.12-x86_64 /usr/local/mysql
~]# ls /usr/local/mysql/
bin docs include lib LICENSE man README share support-files3.创建数据目录
~]# groupadd mysql
~]# useradd -r -g mysql mysql
~]# mkdir -p /data/mysql
~]# mkdir -p /data/mysql4.创建my.cnf配置文件
~]# vim /etc/my.cnf
[mysqld]
bind-address=172.17.0.110 #自己的ip
port=3306
user=mysql
basedir=/usr/local/mysql # 软件包解压的位置
datadir=/data/mysql # 数据目录
socket=/tmp/mysql.sock
log-error=/data/mysql/mysql.err
pid-file=/data/mysql/mysql.pid
#character config
character_set_server=utf8mb4
symbolic-links=0
explicit_defaults_for_timestamp=true5.初始化数据库
# 进入mysql的bin目录
~]# cd /usr/local/mysql/bin/
~]# yum -y install numactl.x86_64
# 初始化
~]# ./mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql/ --datadir=/data/mysql/ --user=mysql --initialize
# 查看密码
~]# cat /data/mysql/mysql.err
2023-02-03T06:13:22.872091Z 1 [Note] A temporary password is generated for root@localhost: yWLcd2pmQF=1
# 密码是 yWLcd2pmQF=1
## 启动mysql,并更改root 密码
#先将mysql.server放置到/etc/init.d/mysql中
~]# cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
# 启动!!!
~]# service mysql start
~]# ps -ef|grep mysql
# 下面修改密码,首先登录mysql,前面的那个是随机生成的。
~]# cd
~]# ./mysql -u root -p #bin目录下
## 重置密码
SET PASSWORD = PASSWORD('123456');
ALTER USER 'root'@'localhost' PASSWORD EXPIRE NEVER;
FLUSH PRIVILEGES;
use mysql #访问mysql库
update user set host ='%' where user ='root'; #使root能再任何host访问
FLUSH PRIVILEGES;
# mysql命令直接使用
~]# ln -s /usr/local/mysql/bin/mysql /usr/bin
~]# mysql -uroot -p1234562.2.安装并配置mysql-exporter
1.下载并设置
~]# wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.12.1/mysqld_exporter-0.12.1.linux-amd64.tar.gz
~]# tar -xf mysqld_exporter-0.12.1.linux-amd64.tar.gz
~]# mv mysqld_exporter-0.12.1.linux-amd64 /data/mysqld_exporter
~]# chmod +x /data/mysqld_exporter/mysqld_exporter暂时还0.14还没有linux版本所以还是用1.12.1
2.配置基本需求
# 设置用户下面配置文件需要
~]# mysql -uroot -p123456
mysql>GRANT PROCESS, REPLICATION CLIENT,SELECTON*.*TO'exporter'@'%' identified by 'Abc@123456';
mysql>flushprivileges;3.创建配置文件
## 创建配置文件
~]# cd /data/mysqld_exporter
~]# vim .my.cnf
[client]
host=172.17.0.110 # 或localhost
user=exporter
password=Abc@123456
# 启动的时候,指定这个配置文件即可4.创建启动文件(使用systemd管理)
~]# cat > /usr/lib/systemd/system/mysqld_exporter.service <<EOF
[Unit]
Description=mysqld_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/data/mysqld_exporter/mysqld_exporter --config.my-cnf=/data/mysqld_exporter/.my.cnf
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 这里我也是用prometheus用户启动mysqld_exporter,所以要创建prometheus用户并授权。5.创建数据目录
~]# groupadd prometheus
~]# useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
~]# chown -R prometheus:prometheus /data/mysqld_exporter6.启动mysqld_exporter
~]# systemctl daemon-reload
~]# systemctl start mysqld_exporter
~]# systemctl status mysqld_exporter
~]# systemctl enable mysqld_exporter
~]# ss -tln | grep 91042.3.添加监控目标
# 添加
~]# vim prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
alerting:
alertmanagers:
- static_configs:
- targets: ["172.17.0.62:9093"]
rule_files:
- "/etc/prometheus/rule.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ["172.17.0.62:9090"]
- job_name: 'node-exporter'
static_configs:
- targets: ["172.17.0.62:9100","172.17.0.107:9100","172.17.0.110:9100"]
- job_name: 'alertmanager'
static_configs:
- targets: ["172.17.0.62:9093"]
- job_name: redis
static_configs:
- targets: ['172.17.0.107:9121']
labels:
instance: redis
- job_name: 'mysql' # 添加如下:
static_configs:
- targets: ['172.17.0.110:9104']
labels:
instance: db
## 设置告警阈值测试
~]# vim rule.yml
groups:
- name: Hosts.rules
rules:
- alert: HostDown
expr: up{job=~"node-exporter|prometheus|grafana|alertmanager"} == 0
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
- alert: redis
expr: up{job=~"redis"} == 0
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
- alert: db
expr: up{job=~"mysql"} == 0
for: 0m
labels:
severity: ERROR
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
# 重启Prometheus容器(之前做了持久化所以可以直接重启)
~]# docker ps -a | grep prome
d54fc1e2751d prom/prometheus "/bin/prometheus --c…" 25 hours ago Up 2 seconds 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
~]# docker stop d54
d54
~]# docker start d54
d54
~]# docker ps -a | grep prome
d54fc1e2751d prom/prometheus "/bin/prometheus --c…" 25 hours ago Up 2 seconds 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus2.5.验证并查看
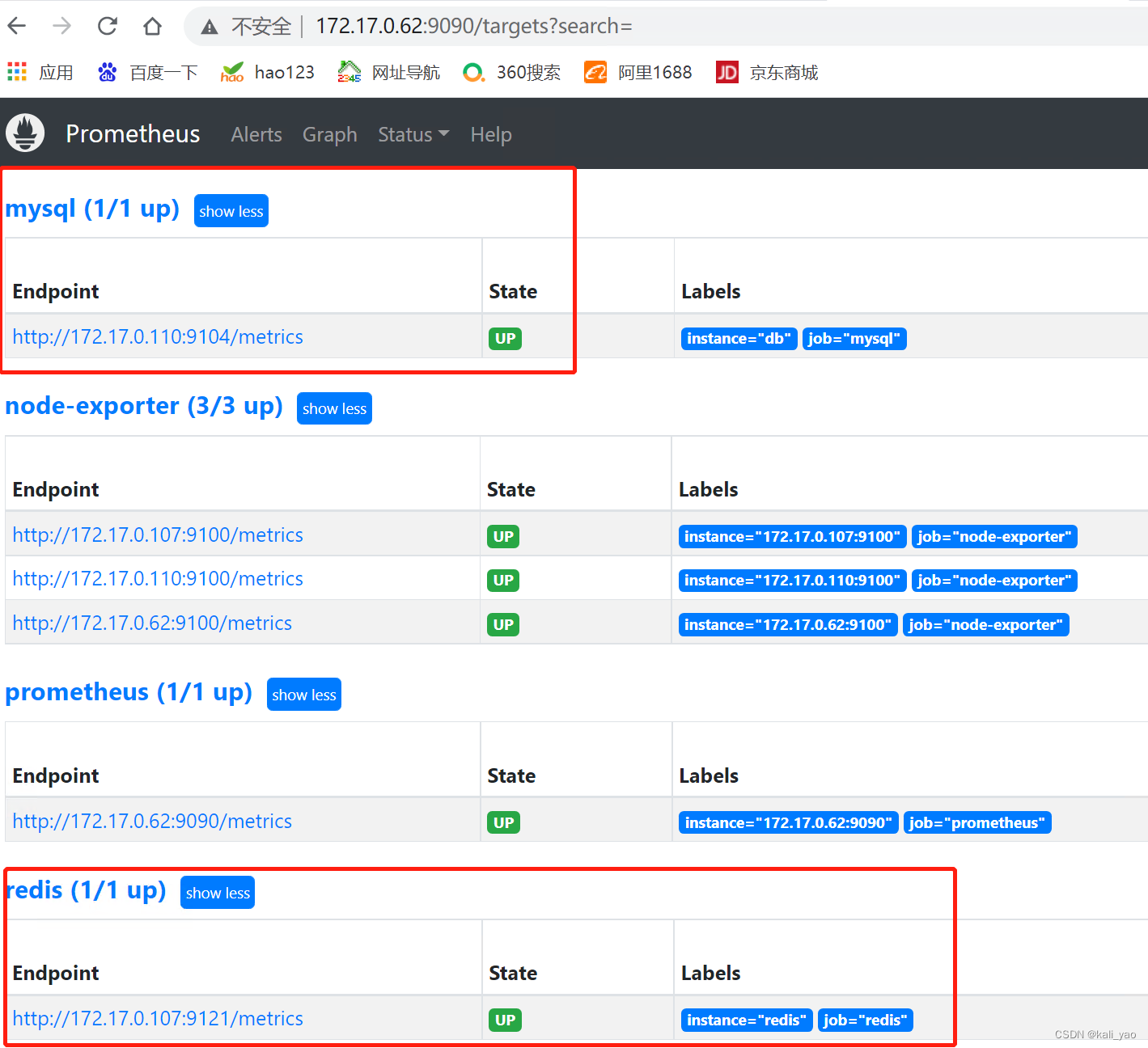

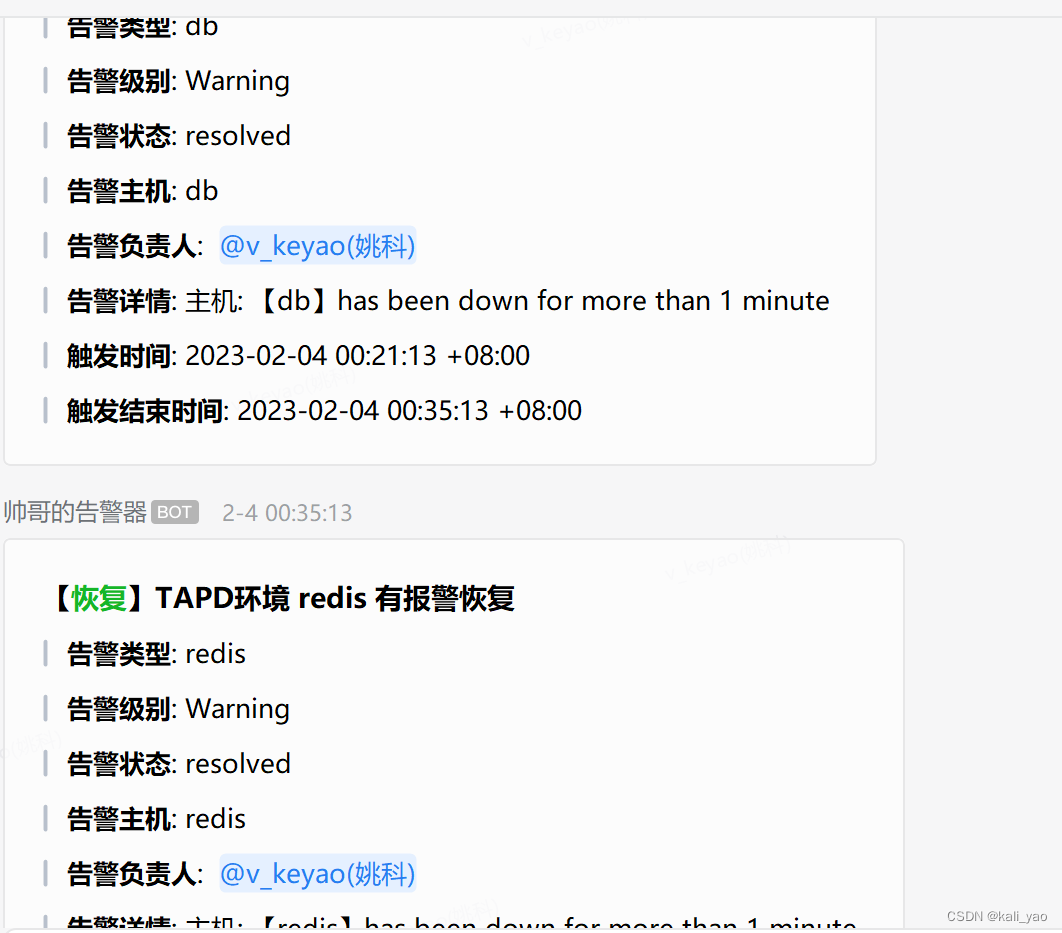
告警阈值设置回后

五.邮件告警和webhook告警组合
主:之前写的邮件告警和webhook告警类似,这里就直接修改配置文件了
1.修改alertmanager
~]# vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xfjoexdzymztbjac'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates:
- '/etc/alertmanager/*.tmpl'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
routes:
- receiver: 'web.hook'
match:
severity: Warning # 与prometheus自定义告警阈值一致如下:severity: Warning
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
html: '{
{ template "email.to.html" . }}'
headers: { Subject: "TAPD告警"}
- name: 'web.hook'
webhook_configs:
- url: 'http://172.17.0.62:8060'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']2.修改自定义告警阈值文件
~]# vim rule.yml
groups:
- name: Hosts.rules
rules:
- alert: HostDown
expr: up{job=~"node-exporter|prometheus|grafana|alertmanager"} == 1
for: 0m
labels:
severity: ERROR # 这个是区分邮件还是告警的表字
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
- alert: redis
expr: up{job=~"redis"} == 1
for: 0m
labels:
severity: Warning # 这个是区分邮件还是告警的表字
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"
- alert: db
expr: up{job=~"mysql"} == 1
for: 0m
labels:
severity: Warning # 这个是区分邮件还是告警的表字
annotations:
title: 'Instance down'
summary: "{
{$labels.instance}}"
description: "主机: 【{
{ $labels.instance }}】has been down for more than 1 minute"3.重启Prometheus和alertmanager容器
~]# docker ps -a | grep prometheus
d5657322a891 bitnami/prometheus "/opt/bitnami/promet…" 7 hours ago Up 6 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
~]# docker stop d56
~]# docker start d56
~]# docker ps -a | grep alertmanager
d4301871c6e3 prom/alertmanager bin/alertmanager -…" 29 hours ago Up 14 minutes 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp alertmanager
~]# docker stop d43
~]# docker stop d434.查看告警
webhook内告警
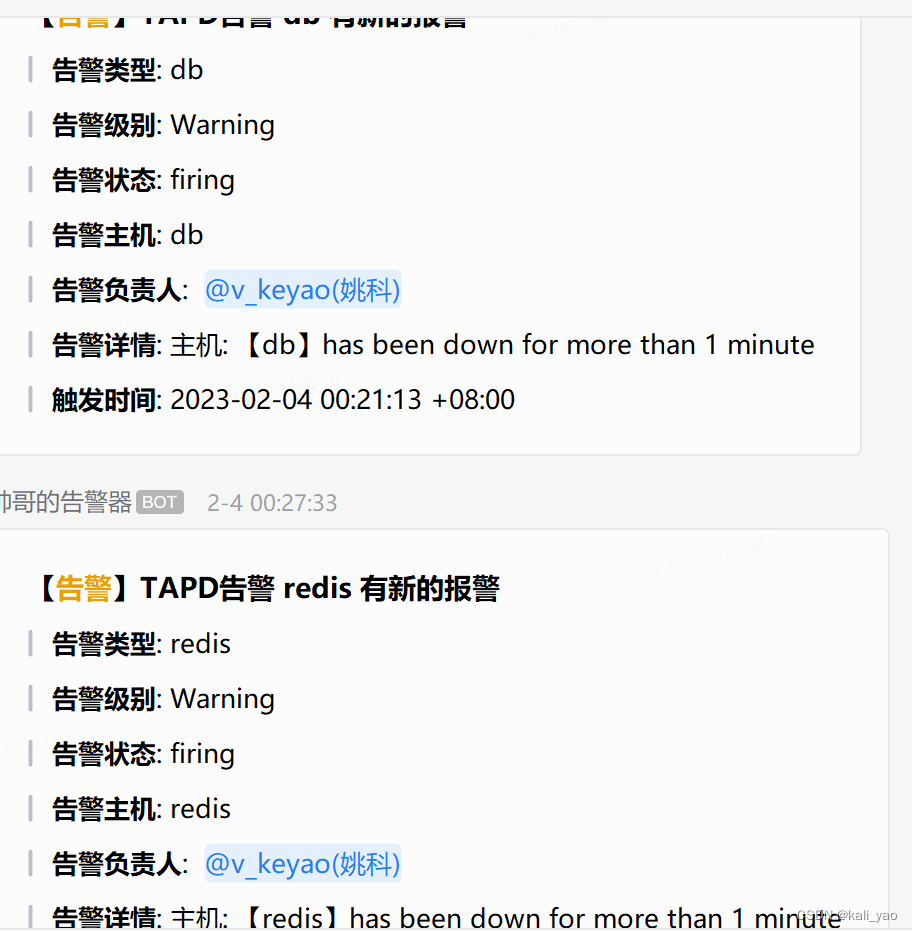
邮件告警

修改回则恢复