最近几篇文章都有提到
来源: ICME2022
链接:https://github.com/huixiancheng/CENet
0、ABSTRACT
CENET:面向自动驾驶的简洁高效的激光雷达语义分割 摘要 准确快速的场景理解是自动驾驶的挑战性任务之一,需要充分利用激光雷达点云进行语义分割。在本文中,我们提出了一种简洁高效的基于图像的语义分割网络,称为 CENet。为了提高学习特征的描述能力并降低计算和时间复杂度,我们的 CENet 将具有更大内核尺寸的卷积(而不是 MLP)、精心选择的激活函数以及具有相应损失函数的多个辅助分割头集成到架构中。在公开的基准、SemanticKITTI 和 SemanticPOSS 上进行的定量和定性实验表明,与最先进的模型相比,我们的流程实现了更好的 mIoU 和推理性能。
Index Terms— LiDAR Point Cloud, Autonomous Driving, Semantic Scene Understanding, Semantic Segmentation
1、INTRODUCTION
近年来,LiDAR传感器的快速发展使得3D计算机视觉成为机器人和自动驾驶等应用中的一个有趣的研究课题[2],其中准确、实时和鲁棒的环境感知和理解是一项具有挑战性的任务。为了实现这一目标,LiDAR 成为最受欢迎和广泛使用的选择,因为 1) 与视觉相机相比,LiDAR 对不同的照明和天气条件更加稳健。 2)获取的3D点云提供了丰富的几何信息。因此,基于LiDAR的语义场景感知,特别是3D点云语义分割受到越来越多的关注,旨在进行逐点分类。
过去几年,SemanticKITTI [1]和SemanticPOSS [3]等数据集的出现,为LiDAR语义分割提供了基准。它们使得将深度学习技术应用于这项任务成为可能。然而,由于 3D 点云的不规则和稀疏结构,我们无法直接在 3D 点云上执行标准的卷积神经网络 (CNN)。为了解决这个问题,最近提出了许多新方法,可分为基于原始点的[4-6]、基于体素的[7,8]和基于范围图像的[9,10]。
一般来说,基于点的网络直接处理原始的3D LiDAR点云,可以获得更好的性能和更高的计算复杂度[5][6]。基于体素的方法将非结构化点云投影到规则网格单元中,并允许使用 3D 卷积神经网络。虽然可以达到最先进的精度,但较高的模型复杂度使得这些方法难以获得实时推理速度。例如,SPVCNN [7] 和 Cylinder3D [8] 在 Tesla V100 上的推理速度分别仅为 8.0 和 7.6 fps。此外,基于距离图像的方法选择使用球面投影策略将原始 3D 点云表示为有序距离图像,然后可以利用精心设计的 2D CNN 来执行 LiDAR 语义分割任务。这类方法实际上可以提供卓越的推理和准确性性能,这促使越来越多的研究人员关注这一领域[11],尽管他们不可避免地会在投影过程中遭受信息丢失[12]。
另一方面,当前基于距离图像的方法,例如KPRNet [13]和Lite-HDSeg [14]通常具有极其大量的参数,并且推理速度较低或模型复杂度较高,这限制了它们在一定程度上的自动驾驶。为了缓解这个问题,FIDNet [15] 提出了一种新的基于距离图像的 LiDAR 语义分割网络,该网络使解决方案尽可能简单,同时保持良好的性能。
然而,FIDNet 的性能无法与当前最先进的方法相比[7,14,16]。因此,基于FIDNet的基本思想和性能,我们尝试重新思考其设计选择,并提出一种简洁高效的LiDAR语义分割模型,称为CENet。定量实验结果表明,我们的网络性能可以在不增加有效参数数量的情况下优于当前最先进的方法,并且具有更高的推理速度(如图1所示)。具体来说,本文的主要贡献如下:
• 我们提出了一种新设计的LiDAR点云分割架构,名为CENet,它可以在不增加参数的情况下提高推理速度。
• 为了提高网络的非线性能力,我们使用SiLU和Hardswish来调整激活函数。
• 通过引入多个辅助分割头,我们显着提高了网络的学习能力,而无需引入额外的推理参数。
• 我们对公开数据集SemanticKITTI 和SemanticPOSS 进行了全面的实验。结果表明我们的方法达到了最先进的性能。
2. RELATED WORK
2.1 Point-based methods
于点的方法直接作用于原始点云。 PointNet [17] 和 PointNet++ [4] 是使用共享 MLP 来学习每个点的属性的开创性研究,这激发了一系列基于点的网络的出现。 KPConv [5] 开发了可变形卷积,可以使用任意数量的核点来学习局部表示。 RandLA-Net[6]采用随机采样策略大大提高了点云处理的效率,并利用局部特征聚合来减少随机操作带来的信息损失。 BAAF[16]充分利用点的几何和语义特征,通过双边结构和自适应融合方法获得更准确的语义分割。
2.2 Voxel-based methods
基于体素的方法首先将点云离散化为 3D 体素表示,然后使用 3D CNN 框架预测这些体素的语义标签。 Minkowski [18] 选择使用稀疏卷积代替标准 3D 卷积来降低计算成本。 SPVNAS [7] 利用神经结构搜索(NAS)来进一步提高网络的性能。
3.3 Image-based methods
基于图像的方法将 LiDAR 点云投影到 2D 多模态图像上,然后应用精心设计的 2D CNN 进行语义分割。 SqueeeSeg [9]和SqueezeSegV2 [19]使用轻量级模型SqueezeNet和CRF进行分割。 RangeNet++ [10]将Darknet集成到SqueezeSeg中,并提出了一种有效的KNN后处理方法来预测点的标签。 SqueezeSegV3 [20] 提出了空间自适应卷积(SAC),根据输入图像的位置使用不同的滤波器。 KPRNet [13] 通过使用强大的主干和 KPConv 作为分割头,取得了有希望的结果。 Lite-HDSeg [14] 通过引入三个不同的模块(类似 Inception 的上下文模块、多类空间传播网络和边界损失)实现了最先进的性能。虽然它具有较高的推理速度,但较高的参数数量和模型复杂性使其不太适合自动驾驶应用。
3. METHODOLOGY
为了充分利用优化良好的传统卷积函数进行实时LiDAR点云分割,我们使用球面投影方法通过将LiDAR点云投影到球面坐标系中来生成2D多模态距离图像,其公式为,
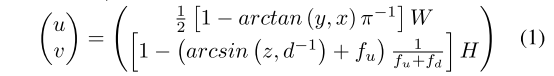
其中 f = fu + fd 指传感器的垂直视野。每个点的深度 d 的计算公式为 d = x2 + y2 + z2。最终结果是尺寸为(H,W,5)的投影距离图像,其中每个像素包含5个通道(x,y,z,d,r),r是点的强度信息。基于这种变换,点云分割问题转化为图像分割任务。
3.1. Network Architecture
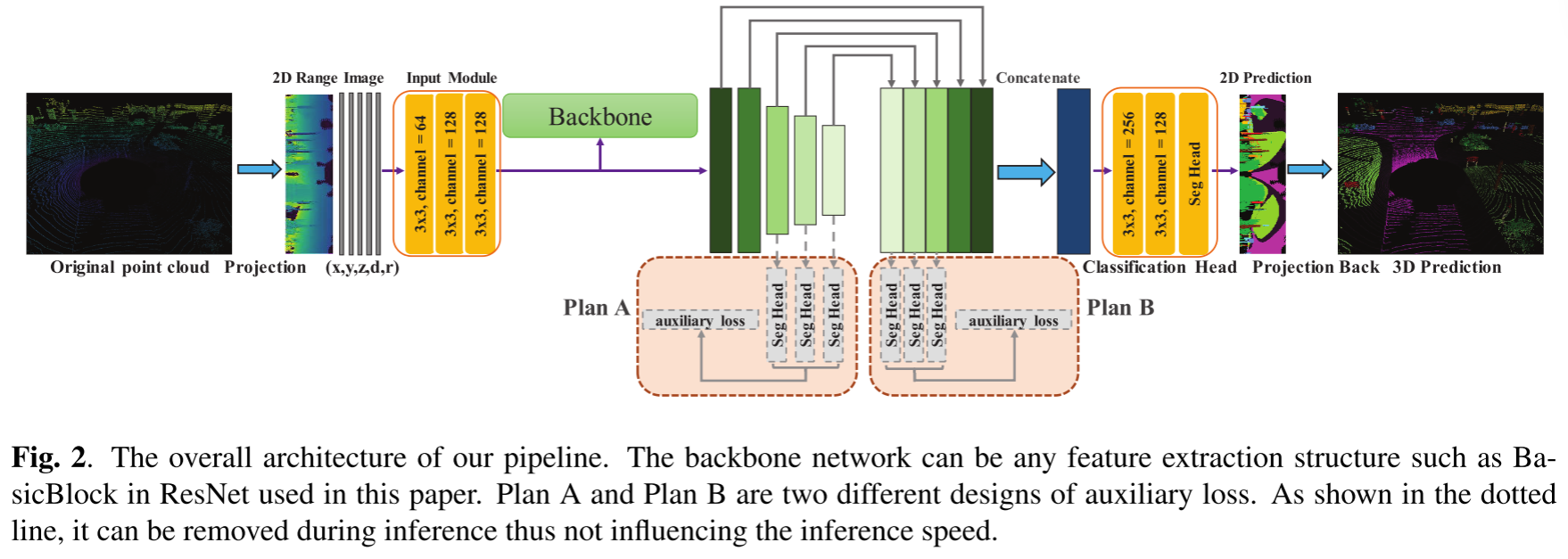
我们的CENet架构如图2所示。我们将在下面的小节中详细介绍核心组件。输入模块、分类头和激活功能。距离图像是一种特殊的具有五个通道的二维图像,其中每个位置实际上可以被视为一个点表示。因此,FIDNet[15]在输入模块和分类头中使用1×1卷积层来处理输入特征,作者认为这可以达到与PointNet中用于点特征学习的MLP类似的效果。然而,由于以下原因,使用 3 × 3 卷积层而不是 1 × 1 更合理。 1)与无序和非结构化的点云不同,生成的距离图像通常具有结构特征,这使得3×3 conv比MLP更适合。 2) 对于 1×1 卷积,较低的参数数量和计算成本并不意味着更快的推理速度。如RepVGG[21]的表1所示,可以得出结论,在相同的条件下,3×3卷积的计算密度(理论运算除以时间使用)可以达到1×1卷积的4倍1080Ti GPU。因此,我们尝试进行简单的替换来提高推理速度,这将在第4.3节消融研究中进行验证。此外,受YoloV5和MobileNetV3的启发,我们可以看到,使用更强的非线性激活函数可以在不增加参数的情况下有助于网络表达能力的提高。因此,我们在模型中采用 SiLU 和 Hardswish 激活函数。第 4.3 节中的实验还表明,这两个函数都可以增强我们模型的性能,而对推理速度影响很小。
Loss Function
为了解决问题1)类别不平衡,2)优化交集重叠(IoU)问题,3)模糊分割边界,按照[14],我们使用三种不同的损失函数,即加权交叉熵损失Lwce, Lov´asz-Softmax 损失 Lls 和边界损失 Lbd,用于监督我们的模型。
对于分割任务,不同对象之间的边界模糊问题通常由上采样和下采样操作引起。为了解决这个问题,我们引入了边界损失函数,它可以正式定义为
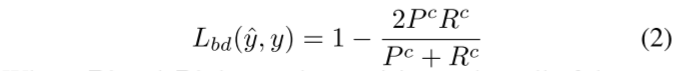
其中 Pc 和 Rc 表示预测边界图 ypd 相对于 c 类地面实况 ygt 的精度和召回率。我们将边界定义为:(前几天刚看过这一篇,当时觉得巧妙,原来是cenet提出的论文阅读:LENet: Lightweight And Efficient LiDAR Semantic Segmentation Using Multi-Scale Convolution Atte-CSDN博客)
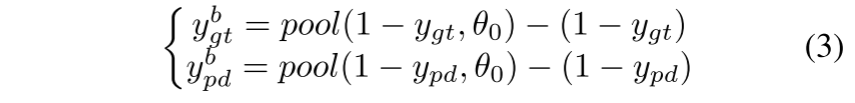
这里pool(·)指的是大小为θ0的滑动窗口上的最大池化操作。最后,我们的总损失是这三个损失函数的加权组合。
 其中α、β、γ是相应的权重,分别设置为1.0、1.5、1.0。另外,我们将Lbd中的θ0设置为3。
其中α、β、γ是相应的权重,分别设置为1.0、1.5、1.0。另外,我们将Lbd中的θ0设置为3。
Auxiliary Loss
在FIDNet中,作者将双线性上采样方法集成到FID模块中以对低分辨率特征图进行插值,从而生成五个具有相同分辨率但编码不同级别信息的逐点特征张量。与其他网络中使用的传统解码器相比[13,14,22],FID 完全无参数,大大降低了复杂性和存储成本。然而,这种简单的解码器使得模型的性能过度依赖于低维和高维特征。另外,与渐进上采样解码器不同,简单的插值融合解码可能导致不同尺度的特征图未完全对齐和解码。为了缓解这个问题,我们引入了多个辅助损失头来细化不同分辨率下的特征图,以提高学习能力。
具体来说,我们使用辅助分割头来预测具有不同分辨率的三个特征图的输出,并与主损失一起计算加权损失以监督我们的网络产生更多语义特征。最终的损失函数可以定义为,

其中Lmain是主要损失,yi是第i阶段获得的语义输出,ˆyi表示相应的语义标签。 L(·)根据公式4计算。如图2所示,对于Plan A,ˆyi是通过下采样相应 GT 标签。对于 B 计划,由于所有特征图都被上采样到最终输出大小,因此 GT 标签是它们的 ˆyi。
4. EXPERIMENT
4.1. Dataset and Implementation details
SemanticKITTI是一个用于自动驾驶场景点云分割任务的大规模数据集。它包含从德国一座城市收集的 22 个序列的 43,551 个 LiDAR 扫描,其中序列 00 至 10(19,130 次扫描)用于训练,11 至 21(20,351 次扫描)用于测试,序列 08(4,071 次扫描)用于验证。所有序列都标有密集的逐点注释。
SemanticPOSS 是北京大学收集的一个更小、更稀疏、更具挑战性的基准。它由 2,988 个不同的复杂 LiDAR 场景组成,每个场景都有大量稀疏的动态实例(例如行人和自行车)。 SemanticPOSS分为6部分,其中我们使用第2部分作为测试集,其他部分作为训练集。
实施细节。我们在单个 NVIDIA RTX3060 和 RTX3090 GPU 上进行所有实验。动量为 0.9 的随机梯度下降 (SGD) 优化器用于网络优化。在训练过程中,我们采用随机旋转、随机点丢失以及向X、Y、Z值添加随机噪声来进行数据增强。权重衰减设置为 1e−4。对于 SemanticsKITTI,我们以初始学习率 1e−2 训练网络 100 个时期,由余弦退火调度器动态调整。对于 SemantciPOSS,网络训练 3 个周期,共 45 个时期,最小和最大学习率分别设置为 1e−5 和 1e−3。
4.2. Results and Discussion
SemanticKITTI 上的定量结果:表 2 显示了几种最先进模型在 SemanticKITTI 基准上的定量结果。它报告输入大小、每秒帧数 (FPS)、平均 IoU 和按类别 IoU。最佳结果以粗体突出显示。从这些结果可以看出,对于大小为 64 × 2048 的输入,与基于点、基于体素的方法或基于图像的方法相比,我们的模型实现了最先进的性能 (64.7%mIoU) ,同时保持较高的FPS(37.8 FPS)。对于64×1024和64×512输入,CENet获得了优异的结果,67.9FPS,62.3%mIoU和84.9FPS,60.7%mIoU,大大优于当前方法。值得注意的是,我们的CENet在输入为64×512时表现出优异的性能,超过了基线方法FIDNet[15]和许多其他方法[20,22,23]在64×2048输入下的性能。
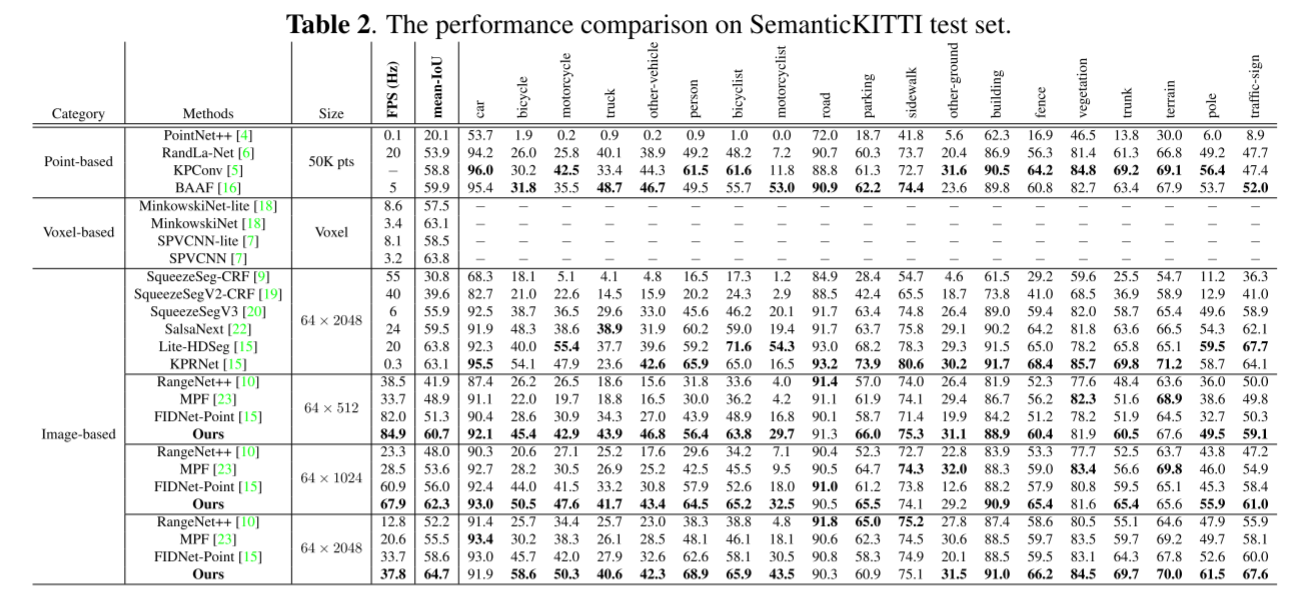
SemanticPOSS 的定量结果:表 3 显示了我们提出的 CENet 与其他相关工作的比较。从这些结果可以看出,由于传感器和环境的差异以及特征的小尺度和稀疏结构,所有方法的结果都稍差。尽管如此,值得注意的是,我们的方法不仅在整体 mIoU 方面优于所有模型,而且在几乎类别的 mIoU 方面也优于所有模型。这进一步验证了我们网络的有效性和效率。具体来说,与原始最佳模型 MINet [24] 和基线方法 FIDNet [15] 相比,我们实现了 7.1% 和 3.9% mIoU 的显着改进。
定性结果:为了更好地可视化我们的模型相对于基线的增强,我们在图 3 中提供了定性比较示例。从结果中可以看出,我们的方法表现出相对于基线的显着改进,并且更接近真实情况。

4.3. Ablation Studies
为了定量分析不同组件的有效性,我们在 SemanticKITTI 验证集上进行了以下消融实验。在这里,我们利用与 SqueezeSegV3 [20] 类似的设置来进行高效的训练和评估。输入范围图像的大小设置为 64 × 512。我们选择列出直接在投影的 2D 图像而不是原始 3D 点上评估的精度。
Effects of Module Components.
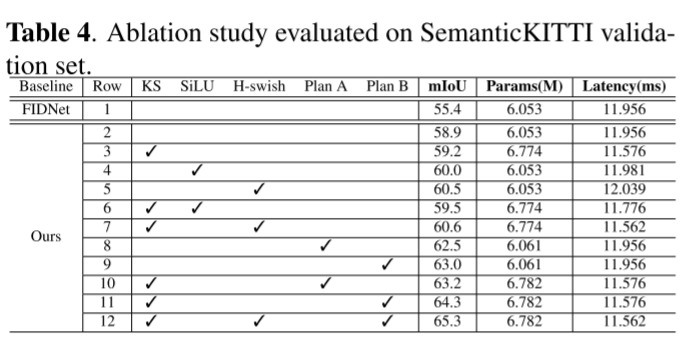
表4展示了不同网络设计选择的实验结果,其中使用mIoU、模型所需的训练参数和推理时间作为衡量标准。
第一行的结果是使用FIDNet官方代码得到的。
第二行报告使用我们的网络实现的性能,其中所需的法线向量已被删除。它仍然比 FIDNet 提高了 3.5%。
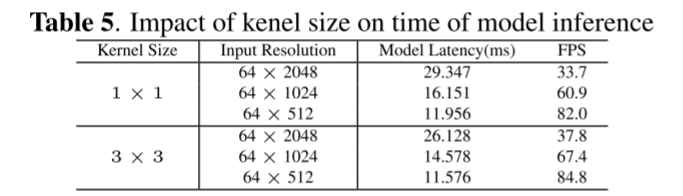
第三行验证用 3×3 卷积替换 1×1 卷积时的有效性。可以得出结论,虽然3×3 conv比1×1 conv引入了更多的参数,但前者可以进一步减少模型的推理时间,并略微提高了0.3%的性能。这主要是因为大的内核尺寸带来了更大的感知领域,并且现代计算库是高度优化的。表 5 进一步报告了不同输入范围图像分辨率下 3 × 3 转换和 1 × 1 转换在模型延迟和总 FPS 方面的差异。总体而言,3×3 卷积可以显着提高模型推理速度。
第四到第七行表示使用不同激活函数的性能。从这些结果中,我们可以看到,引入更强的非线性有助于以很少的推理速度为代价提高模型的描述性。
第八行到第十一行的结果表明:1)两个辅助分割头都可以显着提高我们的 CENet 的性能。虽然辅助头的集成引入了一些额外的训练参数并增加了训练时间,但我们可以在推理阶段删除这些辅助头。因此,它们对网络延迟没有影响。 2)3×3 卷积和辅助损失的组合优于原始 1 × 1 卷积和辅助损失的效果。 3)由于Plan B模块直接根据上采样的特征图计算损失,这有助于细化不同阶段的特征,因此Plan B带来了比Plan A更好的性能。
Effects of λ in auxiliary loss.
公式 5 中包含的超参数 λ 在优化模型性能方面发挥着重要作用。因此,我们评估 λ 的有效性。如表 6 所示,引入额外的监督损失项有助于提高分割性能。当 λ = 1.0 时可获得最佳结果。

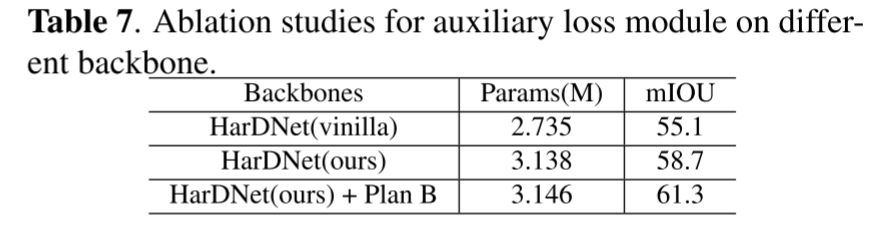
Effectiveness on Different Backbone
在表7中,我们使用不同的特征提取主干HarDNet(Harmonic DenseNet)来验证辅助损失模块的泛化能力。与 ResNet 和 DenseNet 相比,HarDNet 可以在多个任务中实现相当的精度,同时显着减少 GPU 运行时间。首先,我们使用 FC-HarDNet-70 进行实验,得到 55.1% mIoU。然后,我们仔细优化 HarDNet 的结构,以添加更少的参数来构建更强大的基线。最后,我们整合辅助损失,并实现一致的模型性能改进。
5. CONCLUSION
在本文中,我们提出了一种新设计的网络,称为 CENet,用于 LiDAR 点云分割任务。这是一个简洁、高效的模型。基于对先前研究的分析,我们选择使用具有更大内核尺寸的标准卷积以及 SiLU 以及 Hardswish 激活函数,以提高网络的学习能力。然后,我们嵌入多个辅助分割头,以进一步提高学习特征的能力,而无需引入参数和效率成本。 SemanticKITTI 和 SemanticPOSS 上的实验结果表明我们的 CENet 可以实现最先进的性能。
自己总结:
1、整体十分简洁,作者开源了代码,有机会一定试一下
2、辅助分割头应该能有不错的提升、边界损失、激活函数值得学习
疑问:
1、存在疑问到底是3060还是3090,没说时间,纸面速度差了三倍
2、HarDNet替换消融那里没有看懂,cenet用的什么呢?