3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation
本文介绍一篇cvpr2020里面关于点云识别的文章。
论文
目前还没有开源代码
1. 问题
3D目标检测的主要难点在于如何预测和处理 object proposal。一种思路是是自上而下的方式,先回归大量的box,然后再进行第二阶段的优化。但是如果box的偏差比较大,此类方法就很难奏效。另一种思路是自下而上的,通过metric learning学习每点的feature,然后根据这些点的特征,进行聚类形成instance。但是聚类的参数需要人为调整,而且pairwise的计算量太大。本文将这种两种方法结合起来,发挥自上而下方法计算量小的优点,又利用point feature的鲁棒性。通过point-level进行特征表达,但又不对point-level进行聚类,从而完成对两种方法的优势互补。
2. 思想
本文包含三个模块。proposal generation模块逐点学习feature, 每个点都对其所属中心点进行proposals。 接下来是proposal consolidation 模块,对之前的proposal 进行refine。最后是object generation 模块,回归最终的结果。值得一提的是,作者没有使用常见的NMS方式进行回归,因为NMS可能会丢掉正确的结果。而是对 high-level的proposel进行聚类,相比于直接对point聚类,大大减少计算量。
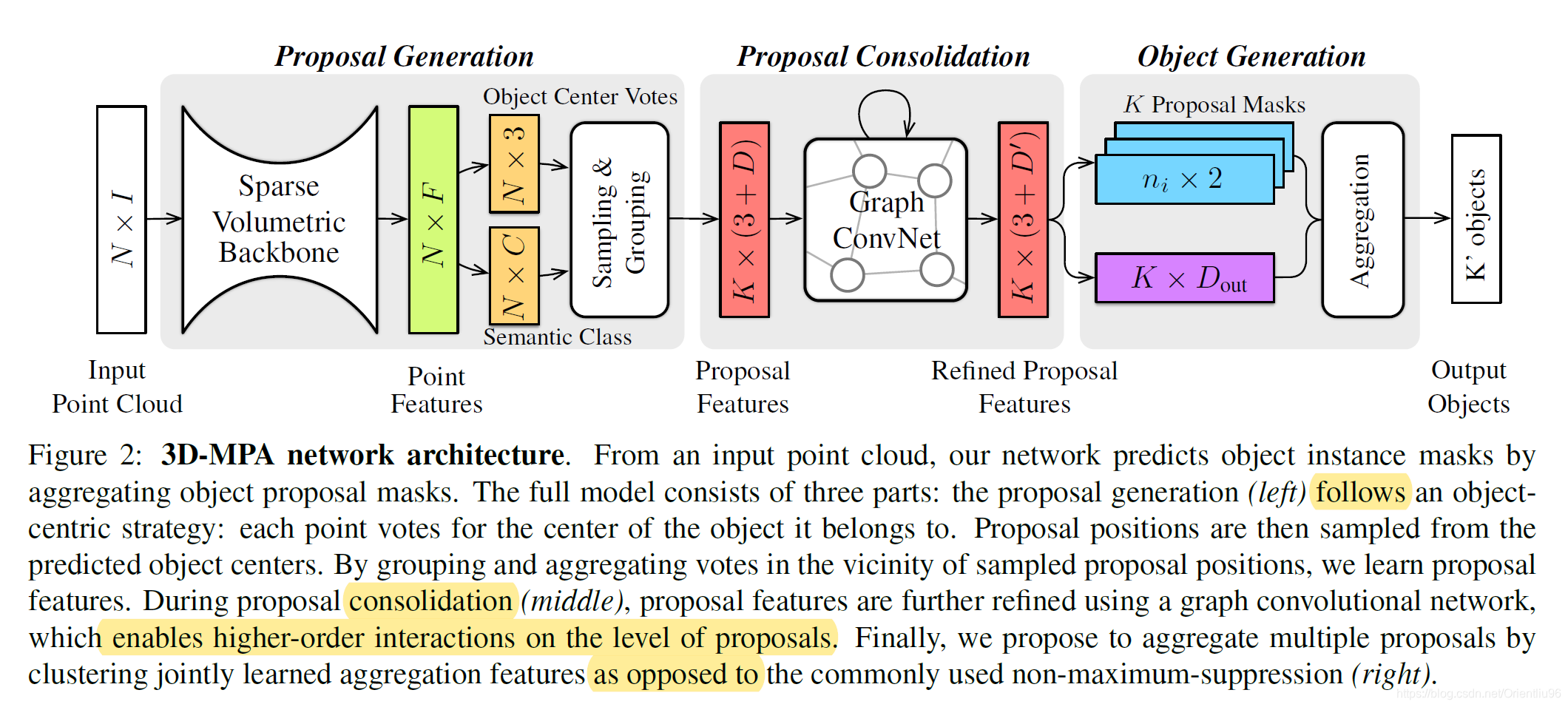
3. 算法
3.1 Proposal Generation
采用稀疏卷积提取每个点的特征,然后分成两个分支,分别预测语义类别以及回归每个点所属实例的中心点坐标。

对于得到的中心点集,随机采样k个点作为实例proposals,每个proposal中心点半径r范围内的点视为属于其对应的实例的点,然后将每个proposal点集通过简单的pointnet提取proposal feature。
每个proposal用元组(yi; gi; si)表示,其中yi代表proposal的中心点位置,gi代表proposal feature,si代表proposal对应包含的实例点集。
3.2 Proposal Consolidation
为了使proposal feature可以和全局特征产生更多的交互,本文使用DGCNN的思想,建立一个GCN来 refine proposal features。

3.3 Object Generation
此处,我们得到K个proposal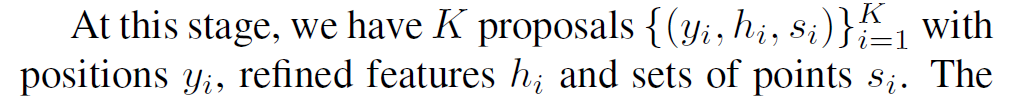
通过MLP得到objectness score。和gt中心点距离小于0.3m的设为正,大于0.6m或和两个gt中心点距离相等的设为负。负proposals不做处理。
对正的proposals,先预测语义类别,再aggregation features和二值实例mask。其中aggregation feature 包含两个方面Geometric features 和 Embedding features

最终的loss为
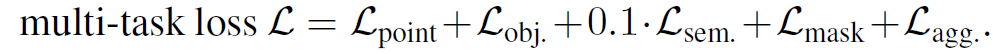
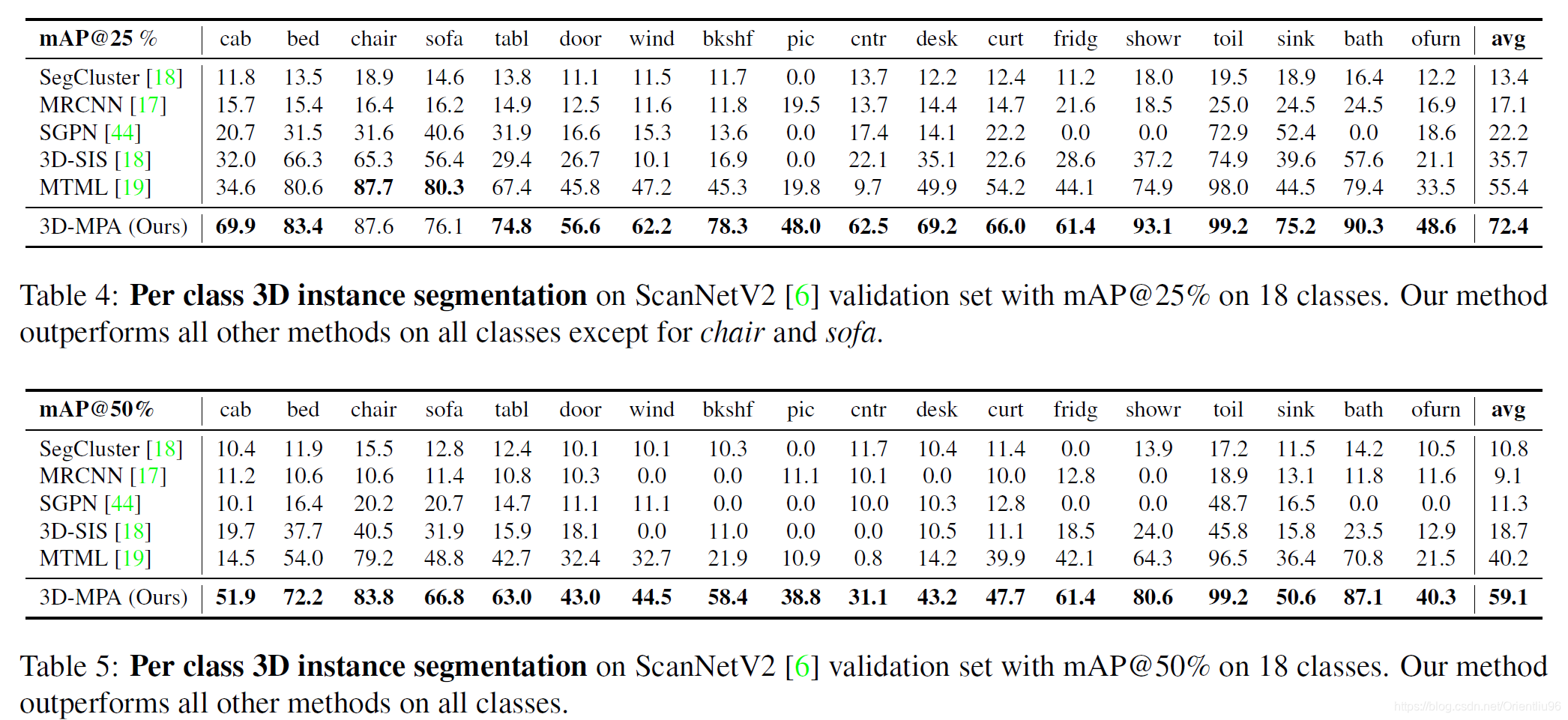
4 实验结果
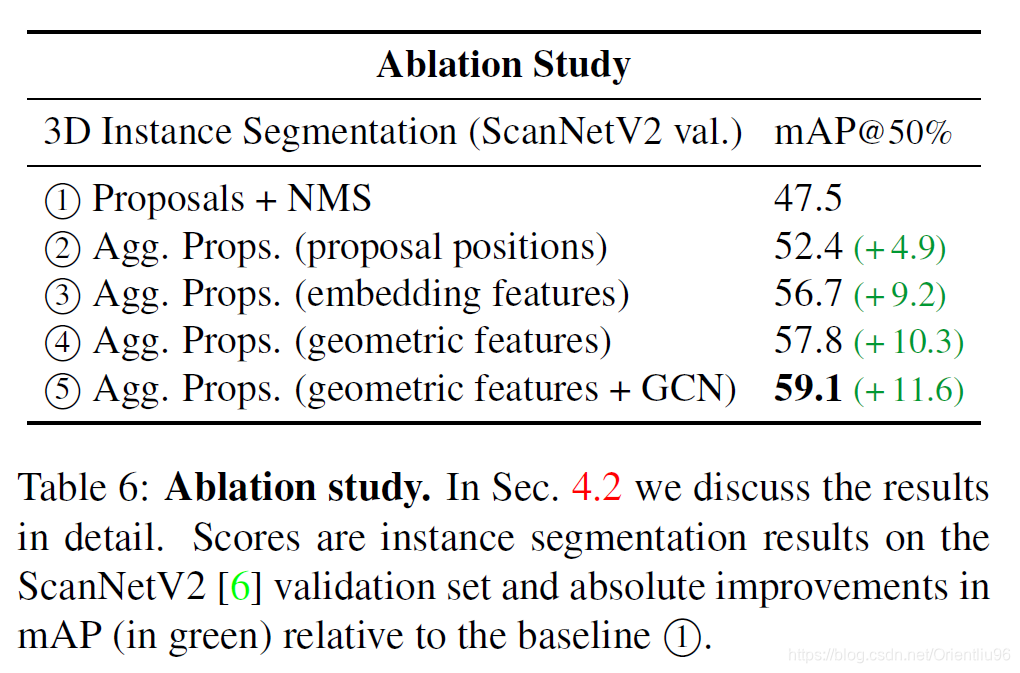
总结
上一篇PointGroup和这篇文章有着异曲同工之妙。但是3D-MPA应该更快一些。因为instance segmentation文章看得不够多,multi task loss似乎是不可避免的,总觉得太耗时难优化,令人望而却步啊。
