线性回归又称最小二乘法。其中:
预测值可以表示为输入参数在各个参数下的线性组合:
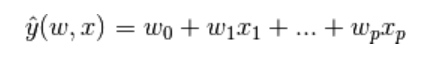
最小二乘法的核心为计算预测值与真实值向量差的2范数的平方的最小值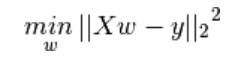
在线性回归中,调用linear_model模块中类linearRegreesion类的fit方法(最小二乘法)对训练数据进行预测得出各个参数
w0为截距项,python中调用为intercept_属性
其余参数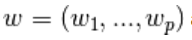 为参数向量,python中调用为coef_
为参数向量,python中调用为coef_
线性回归模型的例子如下:
1 #导入需要的模块 2 import matplotlib.pyplot as plt #可视化模块 3 import numpy as np #矩阵处理模块 4 from sklearn import datasets, linear_model #数据集,线性模型 5 from sklearn.metrics import mean_squared_error, r2_score #均方误差,方差得分 6 7 # Load the diabetes dataset 加载糖尿病数据 8 diabetes = datasets.load_diabetes() 9 10 11 # Use only one feature,导入糖尿病数据集的两列,即表示特征的数据集X列,和观测值y 12 diabetes_X = diabetes.data[:, np.newaxis, 2] 13 14 # Split the data into training/testing sets,将所有数据分为训练集和测试集,后20个数据为测试集,其余为训练集 15 diabetes_X_train = diabetes_X[:-20] 16 diabetes_X_test = diabetes_X[-20:] 17 18 # Split the targets into training/testing sets 将观测值也分为训练集和测试集,个数同X,分别对应 19 diabetes_y_train = diabetes.target[:-20] 20 diabetes_y_test = diabetes.target[-20:] 21 22 # Create linear regression object 建立线性回归的对象 23 regr = linear_model.LinearRegression() 24 25 # Train the model using the training sets 使用对象的fit方法对训练集的(x,y)进行线性拟合 26 regr.fit(diabetes_X_train, diabetes_y_train) 27 28 # Make predictions using the testing set 输出y的预测值 29 diabetes_y_pred = regr.predict(diabetes_X_test) 30 31 # The coefficients 输出参数向量 32 print('Coefficients: \n', regr.coef_) 33 # The mean squared error 输出测试集的均方误差,并保留两位小数 34 print("Mean squared error: %.2f" 35 % mean_squared_error(diabetes_y_test, diabetes_y_pred)) 36 # Explained variance score: 1 is perfect prediction 输出测试集的方差得分,并保留两位小数 37 print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred)) 38 39 # Plot outputs 画出测试集的散点图及采用预测参数得出线性回归线 40 plt.scatter(diabetes_X_test, diabetes_y_test, color='black') 41 plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3) 42 43 #显示x,y轴 44 plt.xticks(()) 45 plt.yticks(()) 46 #显示plot图 47 plt.show()
均方误差的数学意义:反应估计量与被估计量的差异,用来指定在多目标回归问题中,若干个目标变量的损失或得分以什么样的形式平均起来
这个模块在sklearn.metrics里 eg: from sklearn.metrics import mean_squared_error
mean_squared_error(y_true, y_pred,
sample_weight=None,
multioutput='uniform_average')
均方误差为计算y_true, y_pred 两个向量或数组的误差,
sample_weight:每组数据的权重向量,可理解为各数据的概率向量
multioutput有两个字符串形式的选择或数组
默认为multioutput='uniform_average'表示所有数据输出的权重都相同,
multioutput='raw_values'表示所有回归目标的预测损失或预测得分都会被单独返回一个shape是(n_output)的数组中
函数返回值为一个非负的浮点数值或数组(每个值对应一个单独的目标)
方差得分:R2方法 表示用预测值估计与用均值估计的情况下,看能好多少,
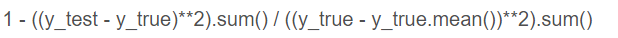
上式表示R2范围在[0,1]之间,当预测值接近均值时,R2值为0,表示预测没必要,可以直接取均值,值为1时,表示预测值与真实值相等
